Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Три бывших исследователя DeepMind, создавшие ИИ, обыгравший профессионалов в покер, теперь применяют те же технологии в трейдинге. Их пражский стартап EquiLibre Technologies торгует миллиардами долларов в день и показывает нулевые убытки с момента запуска. Компания привлекла новый раунд инвестиций при оценке $500 млн и планирует расширить вычислительную инфраструктуру.
Материал описывает путь от базовых понятий LLM до продакшен-развёртывания. Включает практические рекомендации, примеры кода и проекты по работе с промтами, инструментами, RAG, файн-тюнингом и операционной эксплуатацией моделей. Подходит для ML-специалистов, желающих перейти в область LLM-инженерии.
Sony AI разработала робота Ace — первого, достигшего экспертного уровня в теннисе стола. В 2025 году он побеждал элитных игроков и профессионалов благодаря девяти камерам, системам зрения и ИИ. Технологии перспективны для производства и сервисной робототехники.
Бенчмарк ProactiveBench показал: из 22 мультимодальных ИИ-моделей почти ни одна не просит помощи при нехватке визуальных данных, предпочитая ошибаться. Дообучение с подкреплением GRPO поднимает точность до 38,6%, но проблема неопределенности остается острой. Исследователи открыли код бенчмарка для дальнейшей работы.
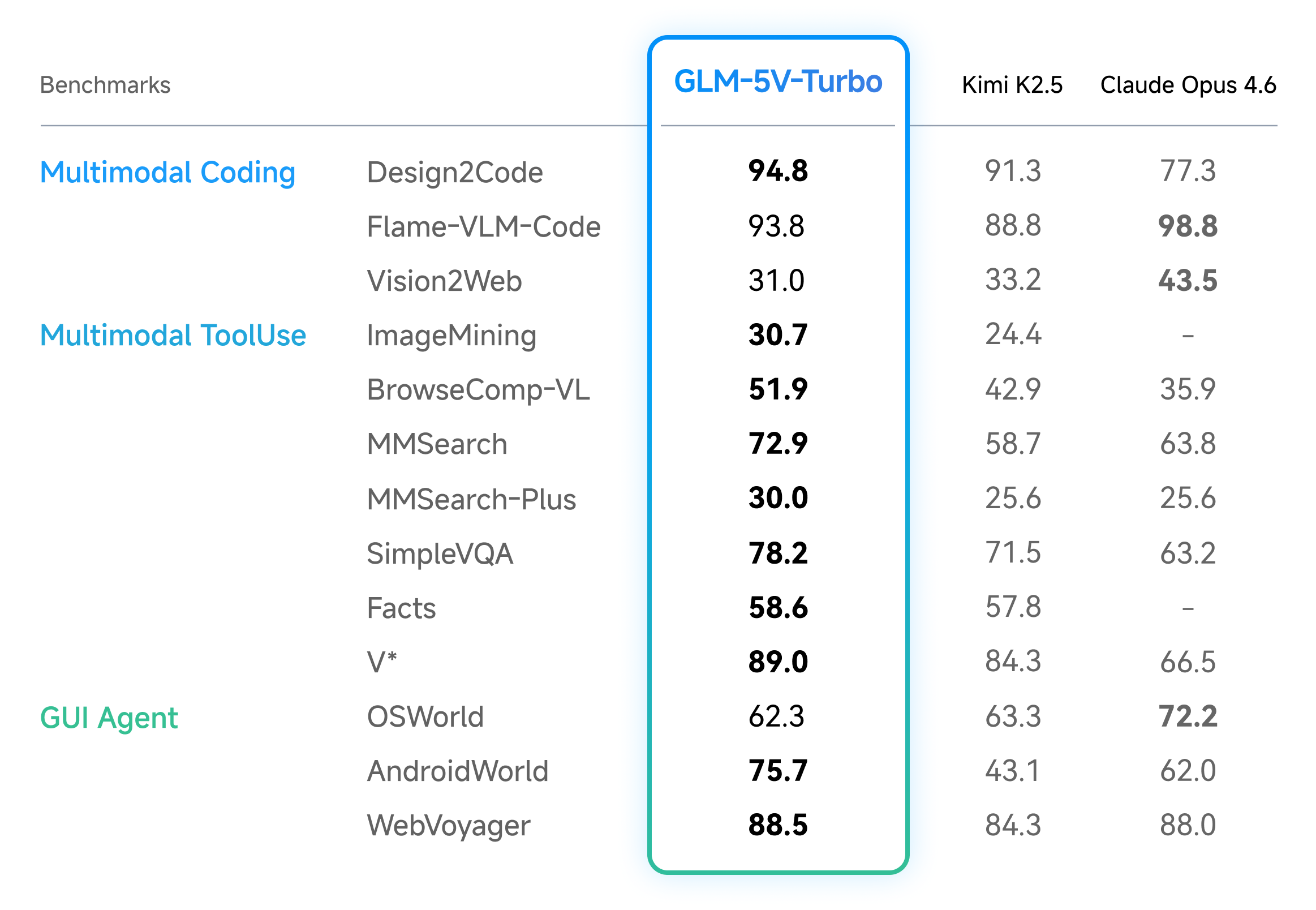
Zhipu AI представила GLM-5V-Turbo — мультимодальную модель, которая превращает дизайн-макеты в исполняемый фронтенд-код и интегрируется в агенты вроде OpenClaw. Она лидирует в бенчмарках по мультимодальному кодингу и GUI-задачам, сохраняя силу в текстовых тестах. Модель доступна через API по цене $1.20/млн входных и $4/млн выходных токенов.
Amazon вывела ИИ-ассистент Alexa+ в Великобританию — первую страну за пределами Северной Америки. Сервис адаптирован под британский акцент с помощью обучения с подкреплением и доступен бесплатно в раннем доступе для покупателей Echo. После теста он будет стоить 19,99 фунта в месяц без Prime.
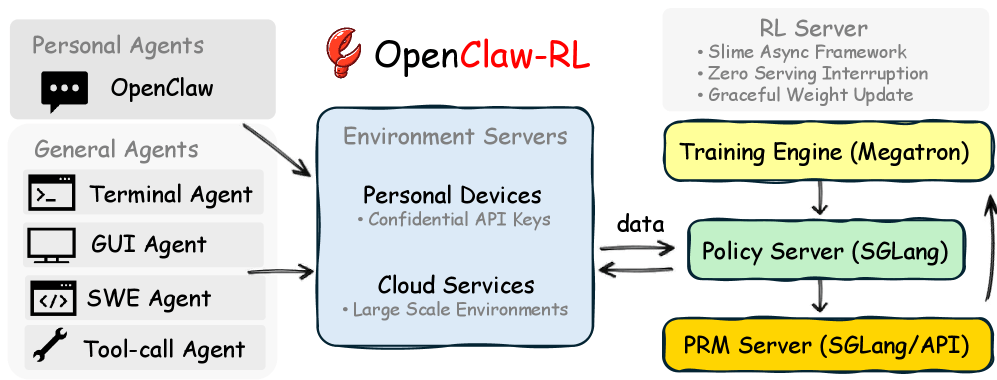
Ученые из Принстонского университета создали OpenClaw-RL — фреймворк, который обучает ИИ-агентов на сигналах из повседневных взаимодействий, превращая ответы пользователей в данные для RL. Сочетает Binary RL и OPD для оценок и корректировок. После десятков шагов точность растет: в симуляциях персонализация до 0.90, в задачах GUI и tool-call — на 0.02–0.13.
ИИ AlphaGo и KataGo радикально изменили го: топ-игроки копируют машинные ходы, дебюты стали однообразными, но мидлгейм сохраняет человеческий шарм. Технология democratizes тренировки, помогая женщинам расти в рейтингах, и дает новые вызовы мастерам вроде Сина Джин-со.
Исследователи из Принстона создали ИИ-систему, которая самостоятельно проектирует радиочастотные интегральные схемы (RFIC) без шаблонов, достигая рекордных характеристик. Используя обучение с подкреплением и диффузионные модели, алгоритм генерирует нестандартные, но эффективные топологии за считанные минуты, преодолевая ограничения традиционного «искусства» проектирования.
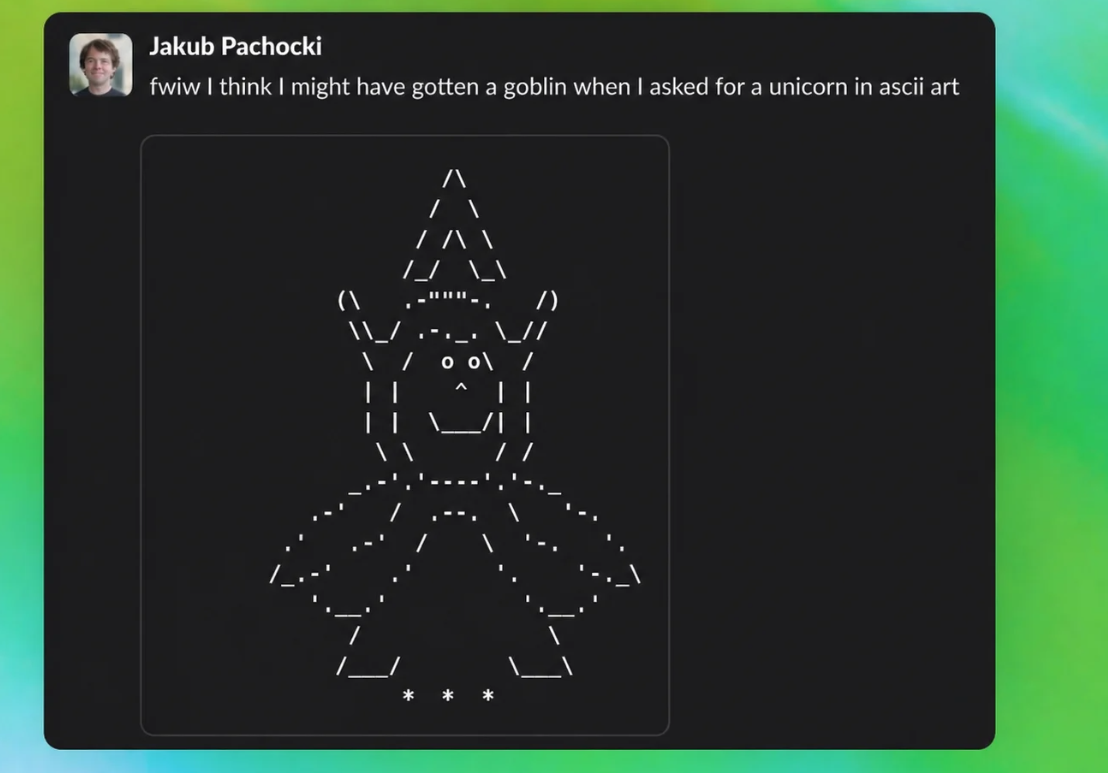
OpenAI разобралась, почему с GPT-5.1 модели ChatGPT стали часто вставлять гоблинов в ответы: сбой в поощрении при дообучении 'Nerdy' личности вызвал 175-процентный рост упоминаний. Привычка распространилась на другие режимы через обратную связь, компания устранила дефект и добавила запреты. Случай подчёркивает риски непредвиденных эффектов от мелких изменений в обучении.
Инвестиции в гуманоидных роботов достигли 6,1 млрд долларов в 2025 году — вчетверо больше, чем ранее, благодаря прорыву в ИИ-обучении от симуляций до языковых моделей. Проекты вроде Jibo, Dactyl, RT-2, RFM-1 и Digit показывают эволюцию: роботы осваивают общение, манипуляции и реальные задачи на складах. Кремниевая долина возвращается к большим амбициям с data-driven подходами.
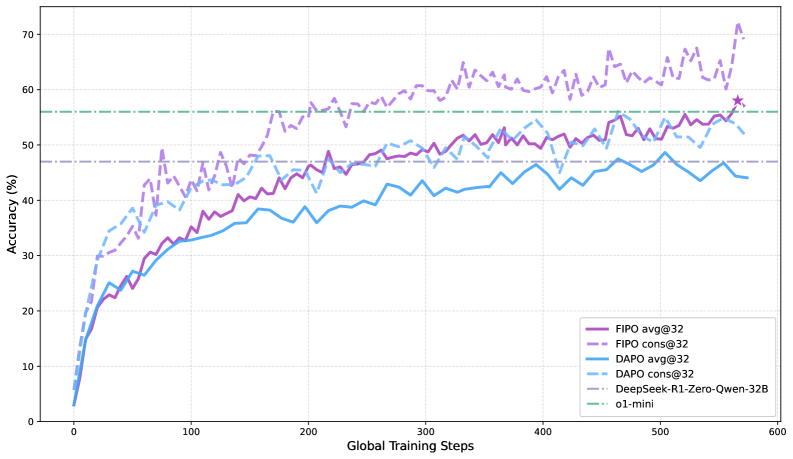
Команда Qwen из Alibaba разработала алгоритм FIPO, который решает проблему равномерного распределения наград в обучении с подкреплением, удваивая длину цепочек рассуждений до 10 000 токенов и поднимая точность на AIME 2024 до 58%. Модель начинает самостоятельно проверять свои расчеты, обходясь без дополнительных данных CoT. Пока результаты ограничены математикой, но код обещают открыть.
General Motors обучает ИИ для автономного вождения в симуляциях в 50 000 раз быстрее реального времени, используя Boxworld, VLA-модели и синтетические данные для длинного хвоста сценариев. Подход сочетает высокодетализированные симуляции, adversarial тесты и дистилляцию политики, снижая риски столкновений на 30%. Это создает основу для полностью надежных систем.
Ученые из Princeton и Варшавы увеличили глубину RL-сетей до 1024 слоев с помощью CRL, добившись 2–50x роста эффективности и новых действий вроде паркура у гуманоидов. Глубина превосходит ширину, но нужны остаточные связи, нормализация и активация. Метод обходит базовые RL в 8 из 10 задач, код открыт.
OpenAI разработала датасет IH-Challenge, обучающий ИИ-модели строгой иерархии инструкций: системные выше разработческих, пользовательских и от инструментов. Это повышает безопасность и защиту от внедрения промтов, особенно через инструменты. Датасет доступен на Hugging Face для дальнейших экспериментов.
Uber открывает подразделение AV Labs, чтобы собирать данные о вождении для партнёров вроде Waymo и делиться ими бесплатно. Машины с сенсорами выйдут на дороги 600 городов, помогая решать редкие сценарии через обработанные датасеты и теневой режим. Подход вдохновлён Tesla, но заточен под целевые нужды отрасли.