Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Amazon Web Services анонсировала прекращение приёма новых клиентов в краудсорсинговый сервис Mechanical Turk с 30 июля 2026 года. Платформа, запущенная в 2005 году как «искусственный искусственный интеллект», переходит в режим поддержки. ИИ-лаборатории теперь предпочитают специализированные компании вроде Scale AI.
Sysdig зафиксировала первую атаку вымогателя, где ИИ-агент автоматически взламывал серверы и шифровал данные, однако выбор цели и подготовка инфраструктуры остались за человеком. Эксперты отмечают скорость и прозрачность действий агента, но полная автономность пока недостижима.
Методологии Lean Six Sigma и BPM эволюционируют за счёт внедрения искусственного интеллекта. Рынок ИИ-оптимизации процессов может превысить 113 миллиардов долларов, а 88% руководителей наращивают инвестиции. Компании с устоявшейся процессной дисциплиной получат наибольшую выгоду.
Эмили Бендер развеивает мифы о метафоре «стохастических попугаев» из своей знаменитой статьи 2021 года. Она поясняет, что метафора относится только к большим языковым моделям, а не ко всему ИИ, и критикует использование термина «искусственный интеллект» как вводящего в заблуждение.
Технические специалисты уверены в способности ИИ-агентов выполнять рутинные задачи и задачи по обработке данных. Однако для сложных решений необходим бизнес-контекст и контроль человека. Отчет основан на опросе 300 экспертов.
Прем Натараджан, бывший руководитель Alexa AI в Amazon, стал Chief Scientist в Capital One. Он объясняет, почему банки — новая арена для прорывных ИИ-исследований, где решаются сложнейшие задачи масштаба и точности, а внедрение агентного ИИ уже меняет сервис для 100 миллионов клиентов.
Статья о применении генеративного ИИ в моделировании природных катастроф: диффузионные модели создают множество сценариев для более точной оценки рисков, но сталкиваются с проблемой галлюцинаций и противоречием интересам страховщиков, которые предпочитают заниженные оценки убытков.
Искусственный интеллект стремительно проникает в математику: ИИ-системы доказывают теоремы уровня PhD, опровергают гипотезы и формализуют доказательства. Математики обсуждают, останется ли место человеку в этой науке, и ищут баланс между использованием ИИ как инструмента и совместной работой в эпоху «большой математики».
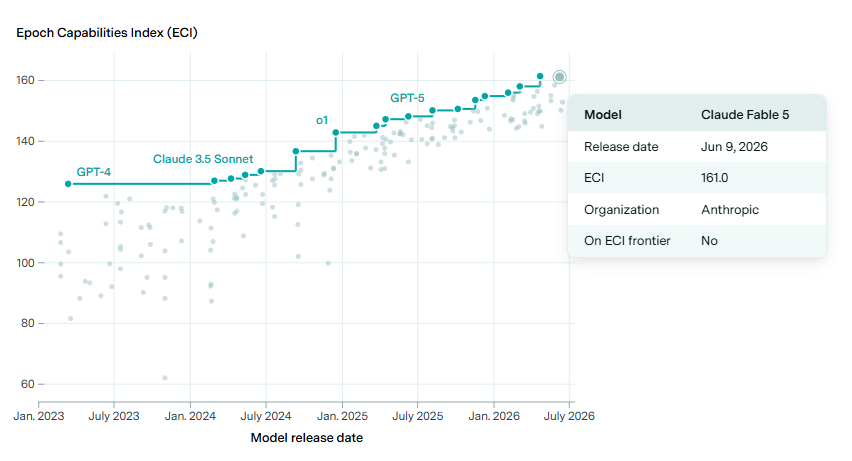
GPT-4 удерживался на вершине Epoch Capabilities Index около года, что гораздо дольше последующих моделей. С февраля 2024 года лидер менялся 17 раз, а среднее время пребывания на вершине сократилось до семи недель. Это отражает усиление конкуренции и ускорение прогресса в сфере языковых моделей.
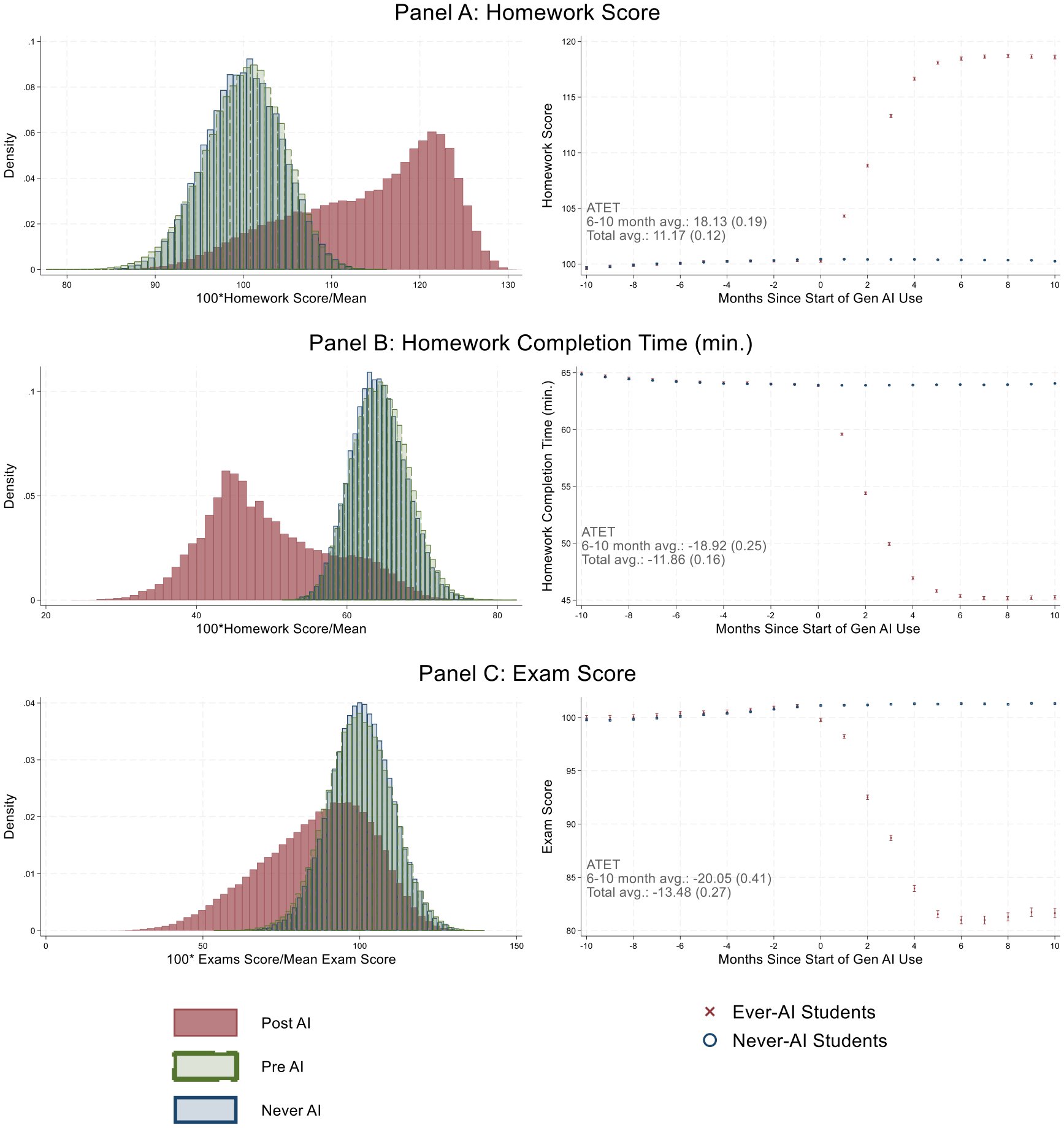
Масштабное исследование с участием 26 000 студентов показало, что использование ИИ улучшает оценки за домашние задания, но ухудшает результаты экзаменов. Основной ущерб для знаний становится заметен лишь спустя два года, особенно сильно страдают социальные науки.
Humanity’s Last Exam (HLE) — сложный бенчмарк для ИИ с вопросами из сотен дисциплин. Даже лучшие модели набирают лишь 45–50%. Мнения экспертов разделились: одни считают его необходимым, другие — отвлекающим манёвром, но полезность теста не отрицается.
Новый отчёт Ramp и Revelio Labs показывает: компании с высокими расходами на ИИ растят штат быстрее — включая позиции начального уровня. Однако данные смещены в пользу технологических фирм с ресурсами; авторы признают: ИИ не всегда создаёт рабочие места универсально.
Модель ИИ Conlang Crafter способна генерировать новые искусственные языки строго соблюдая заданные правила Она превосходит обычные большие языковые модели по разнообразию вдвое а по согласованности почти на 70 % Разработчики планируют использовать её для проверки гипотезы Сепира‑Уорфа.
Бывший руководитель AI в Databricks Навин Рао запустил Unconventional AI, представив модель Un0 на новой осцилляторной архитектуре. Компания утверждает, что такой подход сократит энергопотребление инференса в 1000 раз. Стартап планирует выпустить реальный чип и построить полный стек инференса, что может решить проблему нехватки энергии для масштабирования ИИ.
Исследователи из Принстона создали ИИ-систему, которая самостоятельно проектирует радиочастотные интегральные схемы (RFIC) без шаблонов, достигая рекордных характеристик. Используя обучение с подкреплением и диффузионные модели, алгоритм генерирует нестандартные, но эффективные топологии за считанные минуты, преодолевая ограничения традиционного «искусства» проектирования.
Макс Сперо, CEO сервиса Pangram, объяснил, что нейросети создают тексты с повторяющимися аргументами, что выдаёт их искусственное происхождение. Детектор Pangram анализирует структурные паттерны, которые оставляют языковые модели, хотя принцип его работы до конца не ясен даже разработчикам.