Фреймворк OpenClaw-RL использует сигналы от каждой взаимодействия как источник для обучения в реальном времени. Личные беседы, команды в терминале и действия в графическом интерфейсе поступают в общий цикл дообучения.
Каждое взаимодействие ИИ-агента с пользователем или средой рождает последующий сигнал: ответ пользователя, результат инструмента, изменение статуса в терминале или на экране. Раньше такие данные применялись только как контекст для следующего шага, а потом отбрасывались.
Ученые из Принстонского университета считают это серьезным упущением. Их фреймворк OpenClaw-RL извлекает пользу из этих сигналов прямо во время работы. Вместо разделения личных чатов, команд в терминале, взаимодействий с GUI, задач по разработке ПО и вызовов инструментов на разные этапы обучения, система направляет все потоки в единый процесс для улучшения одной модели.
Последующие сигналы дают оценку и направление
Сигналы после действий несут два вида информации, которые раньше игнорировались. Первый — оценочные сигналы. Повторный вопрос пользователя указывает на неудовлетворенность. Прошедший автоматический тест подтверждает успех шага. Такие индикаторы служат естественной проверкой качества без ручной разметки. Старые методы использовали их постфактум, опираясь на собранные заранее данные.
Второй вид — направляющие сигналы. Фраза вроде «Сначала стоило проверить файл» четко подсказывает, что именно следовало сделать иначе, а не просто отмечает ошибку. Обычные системы подкрепления в RL сжимают подобный отзыв в одно число, теряя детали на уровне содержания.
Четыре независимых компонента обеспечивают непрерывное обучение
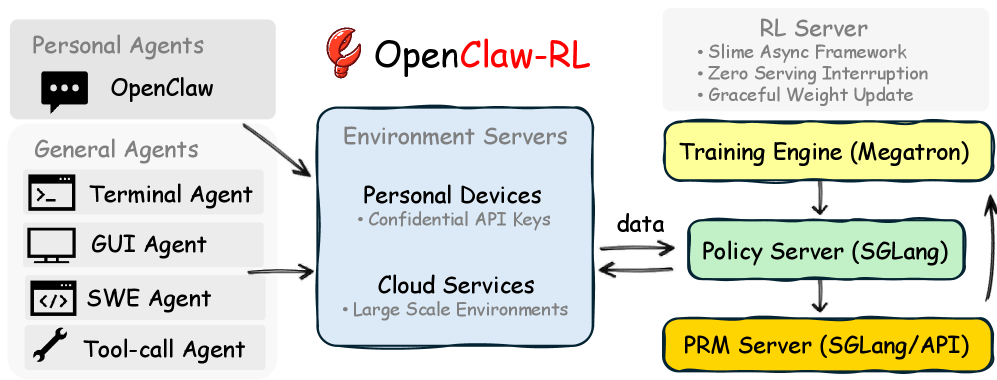
Архитектура OpenClaw-RL делится на четыре независимых блока: один обслуживает модель для запросов, другой управляет окружениями, третий оценивает качество ответов, четвертый проводит дообучение. Ни один не ждет другого — модель отвечает на новый запрос, пока оценщик анализирует предыдущий, а тренер обновляет веса параллельно.
Для личных агентов устройство пользователя подключается к серверу обучения через защищенный API. Обновления весов применяются без перебоев. Универсальные агенты масштабируются в облаке с до 128 параллельными экземплярами.
Модель учится на улучшенной версии самой себя
OpenClaw-RL сочетает два метода оптимизации. Простой Binary RL использует оценочную модель, которая классифицирует действие как хорошее, плохое или нейтральное по сигналу с помощью голосования большинством. Результат идет в обучение как стандартное подкрепление.
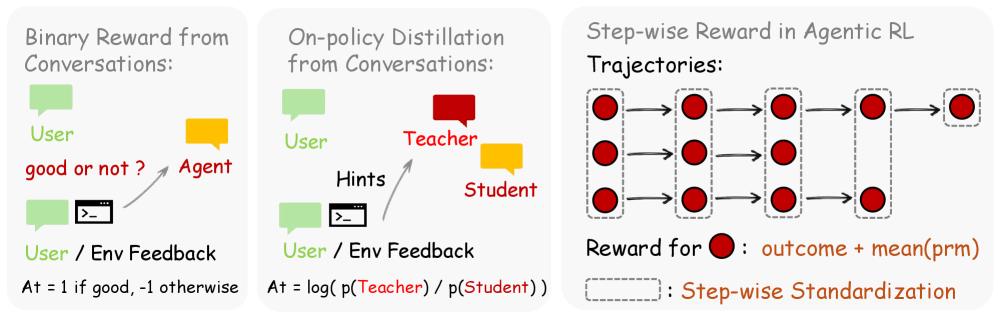
Более продвинутый метод — Hindsight-Guided On-Policy Distillation (OPD). Оценочная модель извлекает из сигнала корректирующую подсказку в 1–3 предложения и добавляет ее к исходному запросу. Затем та же модель вычисляет, насколько вероятно было бы сгенерировать каждый токен оригинального ответа, если бы подсказка была известна заранее.
Разница создает направляющий сигнал для каждого токена: модель в будущем предпочтет одни формулировки и отвергнет другие. Отдельная модель-учитель или заранее собранные данные не требуются.
Binary RL охватывает все взаимодействия широко, OPD дает точные правки на уровне токенов для информативных случаев. Комбинация методов дает наилучший эффект, по словам ученых.
Несколько десятков взаимодействий уже улучшают агента
Ученые проверили OpenClaw-RL на модели Qwen3-4B в двух симулированных сценариях. В одном языковая модель выступает учеником, использующим OpenClaw для домашки, но избегающим обнаружения как ИИ. В другом — учителем, ждущим конкретных, дружелюбных отзывов.

В сценарии ученика показатель персонализации с 0.17 подскочил до 0.76 после восьми шагов комбинированным методом. Binary RL дал 0.25, OPD — 0.25 после восьми шагов, но 0.72 после 16. В сценарии учителя — с 0.22 до 0.90. После нескольких десятков взаимодействий агент избавился от ИИ-штампов и стал писать естественно.
Для универсальных агентов фреймворк протестировали с разными моделями Qwen3 в сценариях терминала, GUI, разработки ПО и вызовов инструментов. Интеграция оценок помогла. В вызовах инструментов успех вырос с 0.17 до 0.30, в GUI — с 0.31 до 0.33.
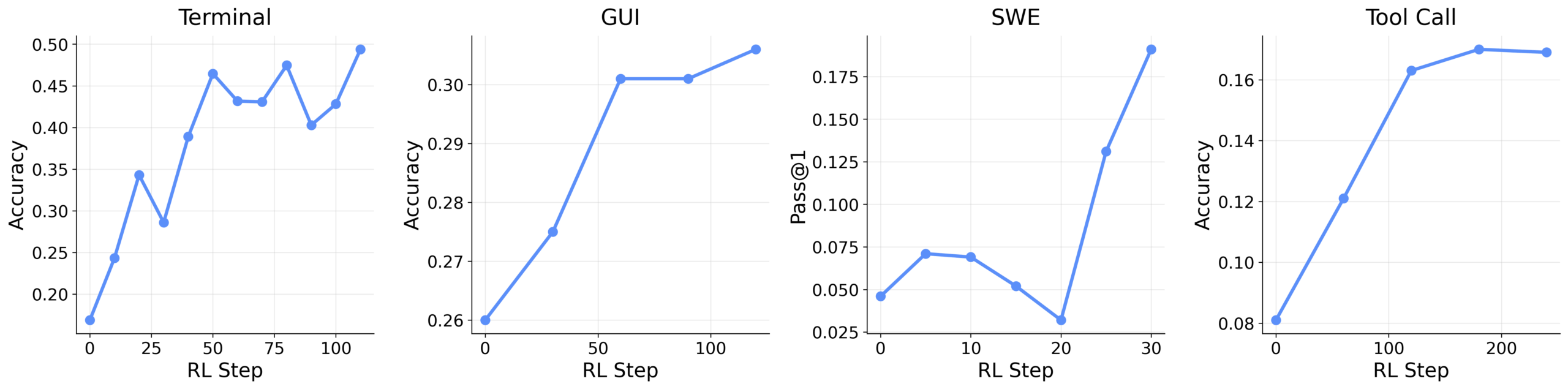
Фреймворк впервые объединяет потоки взаимодействий — от личных бесед до задач разработки — в единый цикл обучения. Код доступен на GitHub.
Проект из Принстона использует название популярного open-source агента OpenClaw и опирается на его инфраструктуру, но остается независимым исследованием без связи с основной командой платформы. Основатель OpenClaw Питер Штайнбергер передал проект фонду и перешел в OpenAI для работы над следующим поколением личных ИИ-агентов.