
Большинство алгоритмов подкрепляющего обучения применяют всего 2–5 слоев сети, но исследователи добились 2–50-кратного роста производительности, увеличив глубину до 1024 слоев в самонаправленном агенте, и при этом наблюдают появление совершенно новых действий.
В обработке текста и изображений увеличение масштаба моделей привело к прорывам. А вот в подкрепляющем обучении (RL), где агенты ИИ постигают навыки методом проб и ошибок, похожий эффект до сих пор не удавалось повторить, отмечают ученые из Принстонского университета и Варшавского технологического университета. Обычно в RL-сетях всего 2–5 слоев, в то время как языковые модели вроде Llama 3 используют сотни.
Исследователи доказали: большее число слоев повышает эффективность в 2–50 раз в зависимости от задания. В самых сложных тестах — когда гуманоид должен пробираться по лабиринту, — систему проверили с 1024 слоями. Секрет в алгоритме Contrastive RL (CRL), который заимствует идеи успешного масштабирования языковых моделей для RL.
Контрастное обучение помогает справляться с редкой обратной связью в RL
Главное препятствие для масштабирования RL — агент получает гораздо меньше сигналов, чем языковая модель. В обучении языков каждое слово дает подсказку. Агент RL же чаще всего узнает лишь итог: достиг цели или нет.
CRL прививает агенту базовый навык: отличать ходы, ведущие к цели, от бесполезных. Обучается это на собственных опытах, без подсказок от людей или заданных наград. По сути, агент бесконечно отвечает на вопрос: этот шаг подходит для пути к цели или нет? Подходящие пары сближают в пространстве, неподходящие — отдаляют.
Чтобы глубокие сети оставались устойчивыми при тренировке, ученые применили три проверенных приема: остаточные связи против потери данных, нормализацию для ровных шагов обучения и особую функцию активации. Глубина работает, только если все три элемента вместе, подчеркивают авторы.
Гуманоидные агенты учатся ходить прямо и перепрыгивать стены
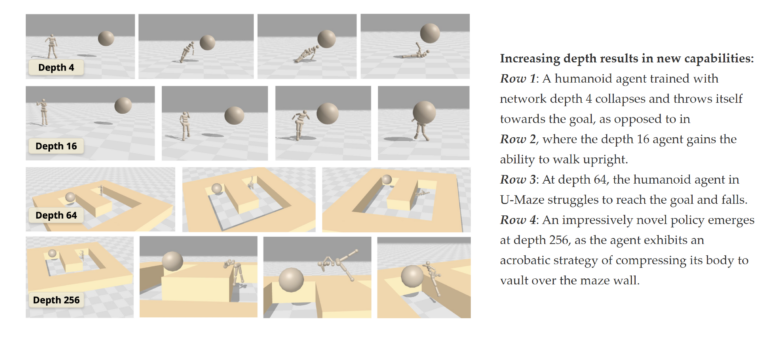
Один из ключевых выводов: эффективность резко растет после преодоления порога глубины. С гуманоидным агентом в симуляции модель на 4 слоя просто кидается к цели. На 16 слоях появляется умение ходить прямо. А на 256 слоях агент придумывает акробатику и перелетает через препятствия. Это первые такие действия в goal-conditioned RL для гуманоидов, отмечают исследователи.
В 8 из 10 заданий CRL с масштабированием глубины обходит все базовые goal-conditioned RL. На самой трудной задаче выигрыш над стандартной сетью превышает 1000 раз.
Глубина эффективнее ширины, но требуется подходящий алгоритм
Раньше в RL масштабировали ширину — число нейронов в слое. Но глубина оказывается мощнее: удвоение до 8 слоев побеждает самые широкие сети при меньшем числе параметров. Классические RL-методы от лишней глубины не выигрывают в экспериментах. Самонаправленный подход CRL решает дело.
Минус — растущие вычисления: глубокие сети тренируются дольше. Пока все в симуляциях. Неясно, как метод перенесется на новые сценарии. Есть тест на inédитых целях, но полные пробы в разнообразии условий впереди. В оффлайн-режиме без взаимодействия с миром лишняя глубина не помогает. Код открыт.
Еще в 2022 году ученые из Гёте-университета во Франкфурте показали, что законы масштабирования из больших языковых моделей подходят и для RL вроде AlphaZero. Производительность росла по степенному закону с размером сети. Новая работа подтверждает: scaling в RL возможен, и глубина сети — ключевой фактор, а не просто общий размер.