Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Эксперты выделяют четыре фундаментальных аспекта ИИ-архитектуры: подготовку данных, контекстную инженерию, управление и вовлечённость человека. Эти компоненты обеспечивают надёжное масштабирование и помогают перейти от экспериментов к промышленному внедрению.
DataRobot упрощает путь от IDE до продакшен-агента: готовая интеграция с Cursor, протокол MCP и агентная поверхность заменяют долгую самостоятельную сборку пайплайнов.
Пять книг помогут разработчикам агентных ИИ-систем в 2026 году: от продакшен-инженерии и LLMOps до промт-дизайна и мультиагентных архитектур. Они фокусируются на практических аспектах, таких как оценка, масштабирование и отладка. Материалы дополняют друг друга для создания надежных автономных систем.
Галлюцинации в LLM решают как системную задачу семью методами: от RAG и обязательных цитат до инструментов, верификации и мониторинга. Подходы опираются на данные, проверки и отказы, повышая надежность приложений. Непрерывная оценка предотвращает регресс качества.
Encyclopedia Britannica и Merriam-Webster подали иск против OpenAI за использование почти 100 000 статей в обучении ИИ без разрешения, а также за копирование контента в ответах и галлюцинации. Это часть волны судебных дел от издателей вроде New York Times и газет США и Канады. Прецедентов по обучению моделей на защищенных данных мало, но пример Anthropic показывает риски.
ИИ-агент от Codewall за два часа взломал платформу Lilli McKinsey через SQL-инъекцию в JSON-полях, получив доступ к 46,5 млн чат-сообщений, промтам и RAG-данным. Уязвимость позволяла незаметно менять поведение ИИ без следов. McKinsey оперативно устранила дыру, но случай подчеркивает новые угрозы для промтов как ключевых активов.
Графовые базы данных усиливают RAG-системы, добавляя понимание связей между данными для сложных запросов и многошагового вывода. Гибридный подход сочетает векторный поиск с графовым обходом, а пошаговое внедрение охватывает подготовку данных, схему, индексацию и оркестрацию. Важны безопасность, управление и compliance для продакшена.
Предприятия тратят миллиарды на генеративный ИИ, но большинство пилотов не выходит за рамки тестов из-за проблем с инфраструктурой. Композитный и суверенный ИИ помогает масштабировать проекты, сохраняя данные под контролем и снижая затраты — к 2027 году такой подход выберут 75% компаний. Эксперты объясняют, почему пилоты работают в теории, но терпят крах в реальности.
Автор делится личным опытом создания ИИ-ассистента на Python с использованием LangChain и GPT-4o. Подробно разбираются архитектура, код, настройка памяти и инструментов для веб-поиска и чтения файлов. Готовый ассистент помогает с исследованием, черновиками и обработкой документов, ощутимо экономя время.
Обзор 10 Python-библиотек упрощает разработку приложений на LLM: от базовой загрузки моделей в Transformers до мультиагентных систем в CrewAI и оценки в DeepEval. Каждая решает конкретные задачи вроде RAG, инференсии или дообучения. Таблица суммирует применение и ценность для ускорения перехода от экспериментов к продакшену.
Системы RAG развивают LLM, устраняя галлюцинации и проблемы с актуальными знаниями. Статья разбирает семь шагов: от очистки данных и разбиения на чанки до векторизации, хранения, извлечения контекста и генерации ответов. Это позволяет создавать надежные ИИ-приложения на свежих данных.
DataRobot подтвердила NVIDIA RTX PRO 4500 с архитектурой Blackwell как оптимальный движок для платформы Agent Workforce. Карта с 32 ГБ GDDR7 идеальна для локального запуска агентов, низких задержек и защиты данных в логистике с cuOpt и RAG с NeMo Retriever. Платформа добавляет инструменты runtime и build для безопасного управления.
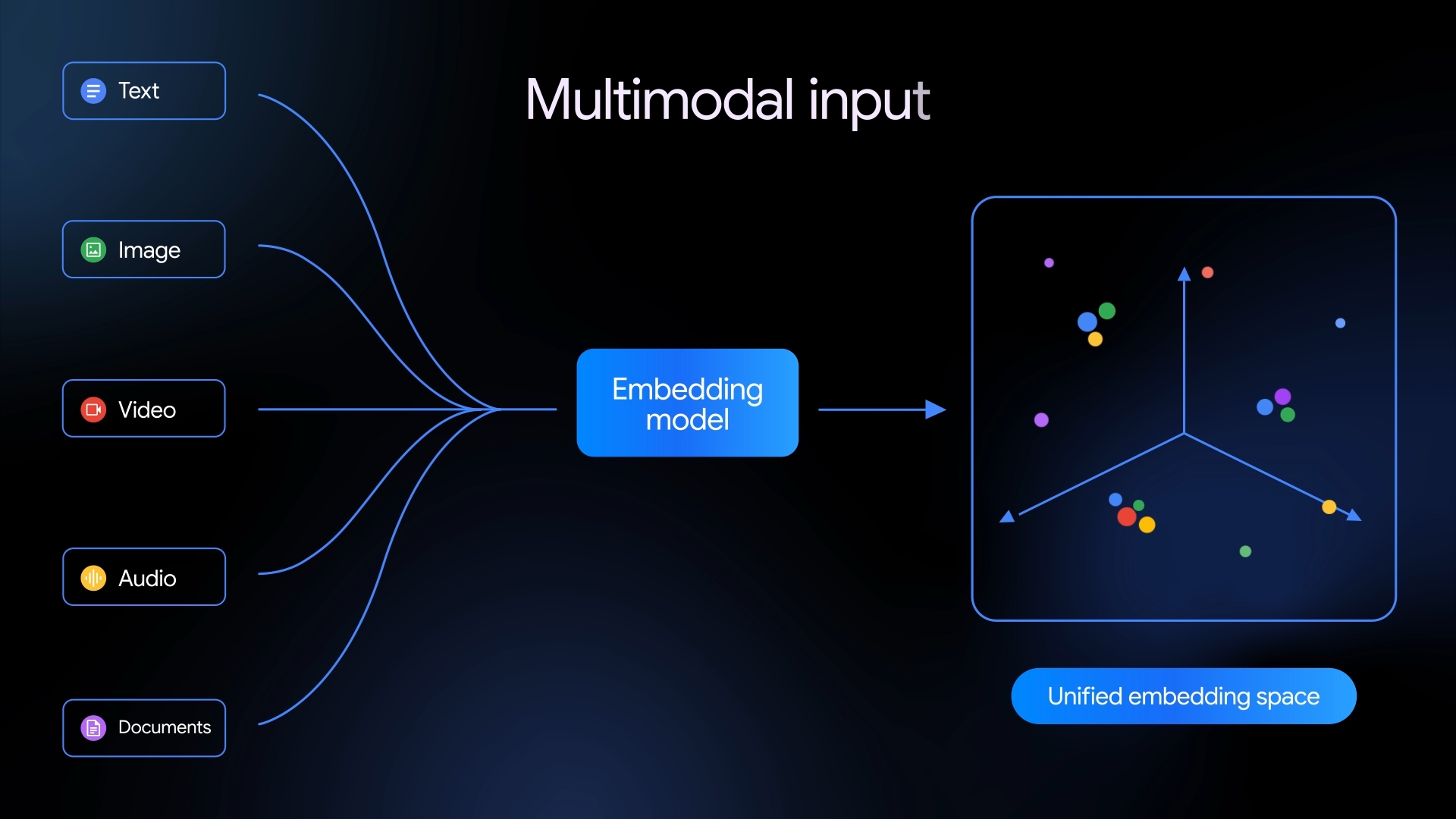
Google анонсировал Gemini Embedding 2 — мультимодальную модель эмбеддингов, которая объединяет текст, изображения, видео, аудио и PDF в единое пространство. Она лидирует в бенчмарках над Amazon Nova 2 и Voyage 3.5, поддерживает смешанные запросы и нативную обработку аудио. Модель доступна в Gemini API и Vertex AI с готовыми интеграциями.
Статья разбирает изменения в инженерии данных из-за LLM: от подготовки массивов для обучения до RAG-архитектуры, векторных баз и мониторинга. Ключевые аспекты — объем, разнообразие и качество данных, инструменты вроде LangChain, Pinecone и Spark. Это позволяет создавать эффективные ИИ-приложения.
Подробный план самообучения поможет освоить инженерию ИИ от основ Python до продвинутых агентных систем и LLMOps. Каждый шаг включает ресурсы, проекты и ключевые навыки для построения реального портфолио. Следуя roadmap, можно войти в профессию без степени по ИИ.
Сравниваем роли специалиста по данным и инженера ИИ: обязанности, навыки, рынок труда и зарплаты. Разбираем, как выбрать путь по интересам и подготовиться к 2026 году. Обе профессии востребованы, но акценты разные — анализ данных или создание ИИ-продуктов.