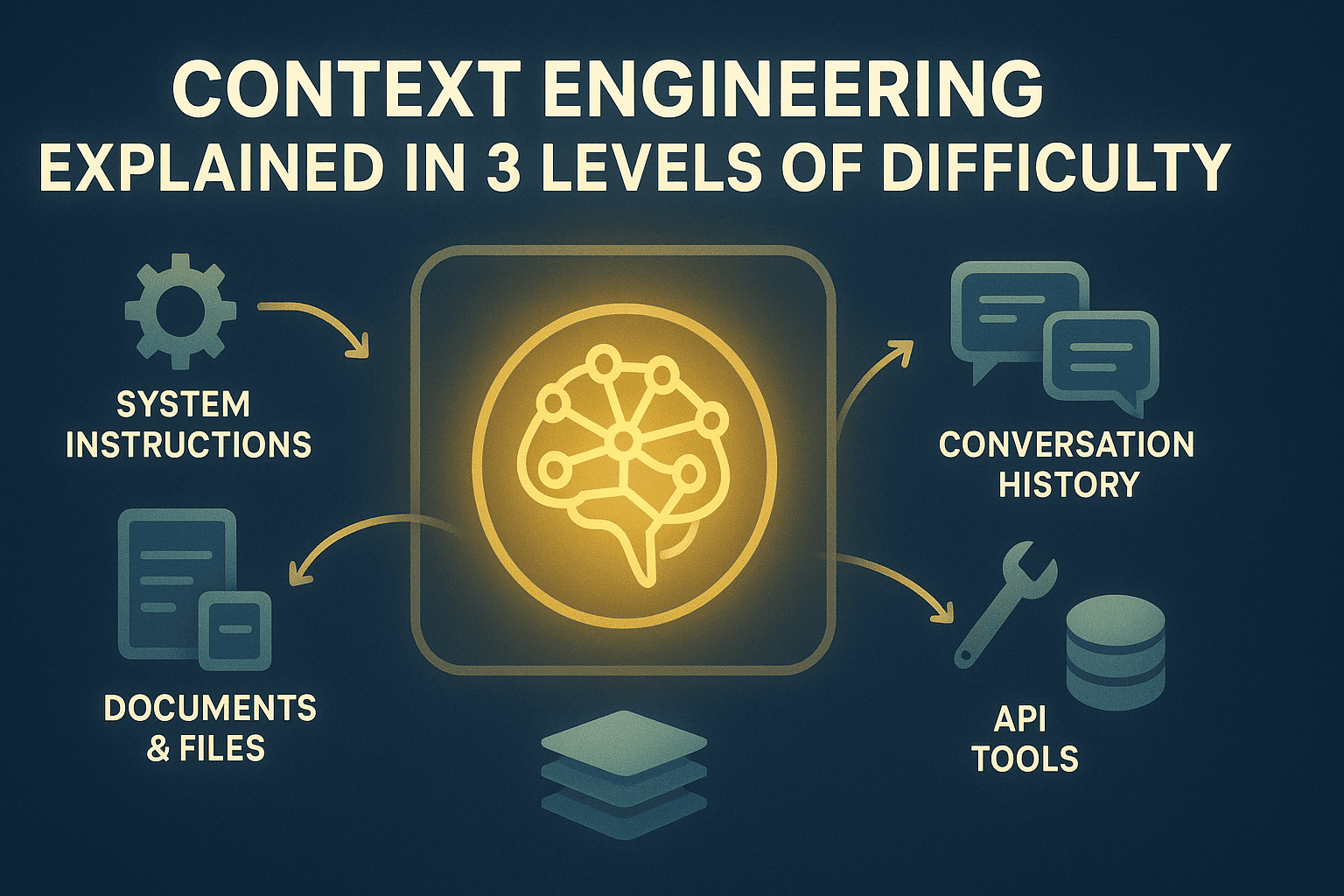
Введение
Приложения на больших языковых моделях (LLM) регулярно сталкиваются с ограничениями контекстного окна. Модель теряет ранние инструкции, упускает ключевые данные или ухудшает качество при затяжных диалогах. Причина в фиксированном лимите токенов, в то время как объем данных растет без остановки: история бесед, полученные документы, загруженные файлы, ответы API и пользовательские сведения. Без контроля важные детали обрезаются случайно или вовсе не попадают в контекст.
Инженерия контекста превращает окно контекста в управляемый ресурс с четкими правилами распределения и механизмами памяти. Разработчик определяет, какие данные включаются в контекст, в какой момент, сколько времени там остаются, а что сжимается или сохраняется во внешнем хранилище для выборочного извлечения. Такой подход организует поток информации во время работы приложения, избавляя от необходимости впихивать все подряд или мириться с падением производительности.
Статья разбирает инженерию контекста на трех уровнях:
- Осознание фундаментальной нужды в управлении контекстом.
- Внедрение рабочих методов оптимизации в реальных системах.
- Обзор сложных архитектур памяти, систем поиска и техник доработки.
Дальше эти уровни рассмотрены подробно.
Уровень 1: Узкое место контекста
У больших языковых моделей фиксированные контекстные окна. Все знания модели на момент генерации ответа должны уместиться в эти токены. Для одноразовых запросов это не проблема. Но в системах с retrieval-augmented generation (RAG), AI-агентах, выполняющих многошаговые задачи с вызовами инструментов, загрузкой файлов, историей чатов и внешними данными возникает дилемма: какую информацию оставить в фокусе, а какую выбросить?
Представьте агента, который работает несколько шагов, делает 50 вызовов API и обрабатывает 10 документов. Без целенаправленного управления контекстом такая система скорее всего даст сбой. Модель забудет важное, придумает выводы инструментов или потеряет в качестве по мере роста беседы.
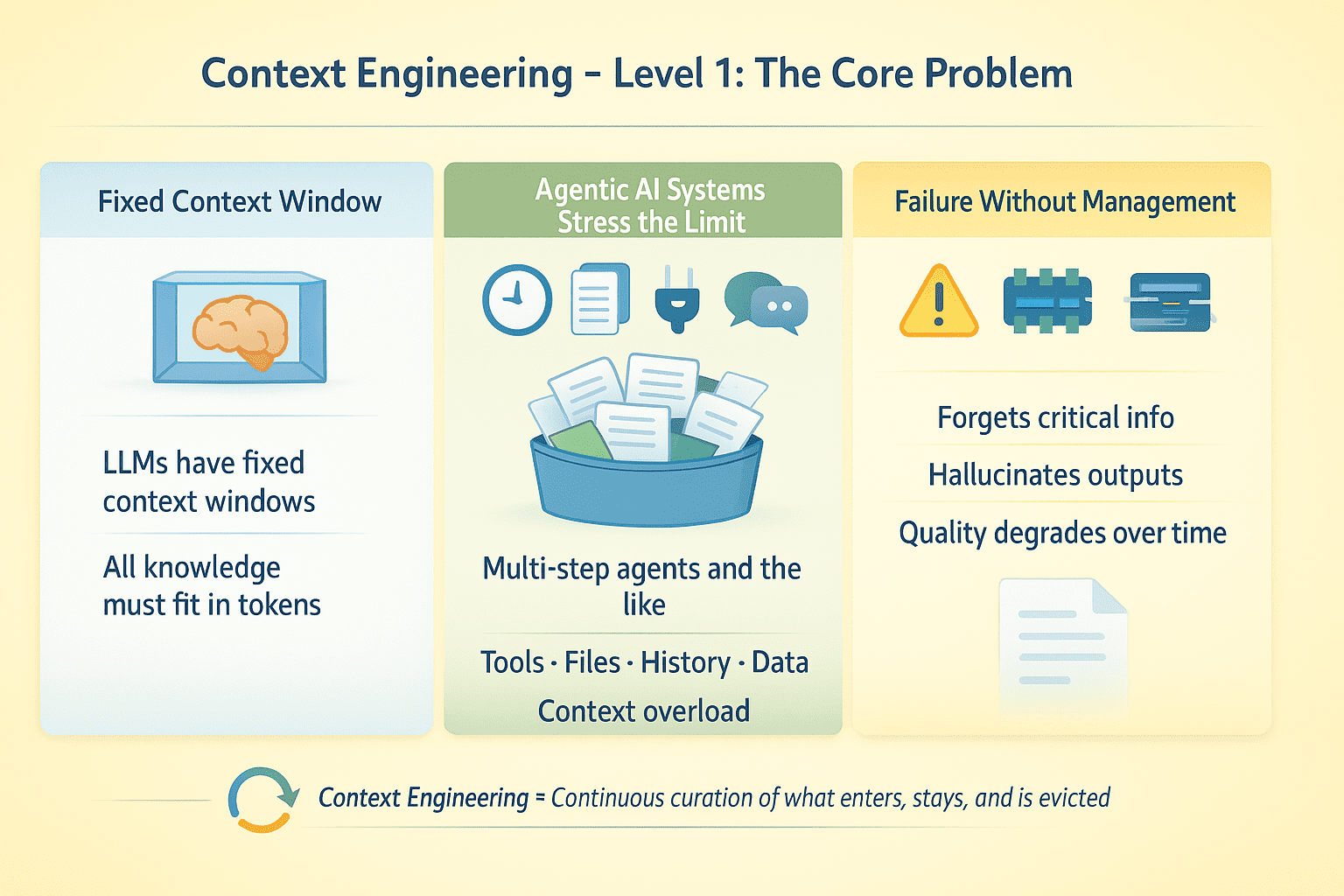
Инженерия контекста подразумевает непрерывный контроль информационной среды вокруг LLM на протяжении всего выполнения. Это касается выбора данных для контекста, момента их ввода, продолжительности хранения и правил удаления при нехватке места.
Уровень 2: Оптимизация контекста на практике
Чтобы добиться результата, нужны конкретные приемы по разным направлениям.
Бюджетирование токенов
Распределяйте окно контекста осознанно. Инструкции системы могут занимать 2K токенов. История чата, схемы инструментов, найденные документы и свежие данные быстро накапливаются. В моделях с огромным окном есть запас, но при малом приходится жестко выбирать, что сохранять, а что жертвовать.
Обрезка бесед
Оставляйте свежие реплики, убирайте промежуточные, берегите ключевой начальный контекст. Сжатие через summary снижает точность. Некоторые решения применяют семантическое сжатие — выделяют основные факты вместо хранения полного текста. Проверьте, на каком этапе агент начинает сбоить при длинных диалогах.
Контроль выходов инструментов
Объемные ответы API жрут токены. Запрашивайте только нужные поля вместо полных данных, обрезайте результаты, суммируйте перед подачей модели или используйте поэтапный подход: сначала метаданные, потом детали по релевантным пунктам.
Протокол контекста модели и поиск по требованию
Не загружайте все сразу — подключите модель к внешним источникам через протокол контекста модели (MCP). Агент сам решает, что запрашивать по нужде задачи. Фокус смещается с "впихнуть все" на "достать подходящее в подходящий момент".
Разделение структурированных состояний
Стабильные инструкции помещайте в системные сообщения. Переменные данные — в пользовательские, чтобы обновлять или удалять без правок базовых директив. Рассматривайте историю чата, выходы инструментов и документы как отдельные потоки с самостоятельными правилами управления.
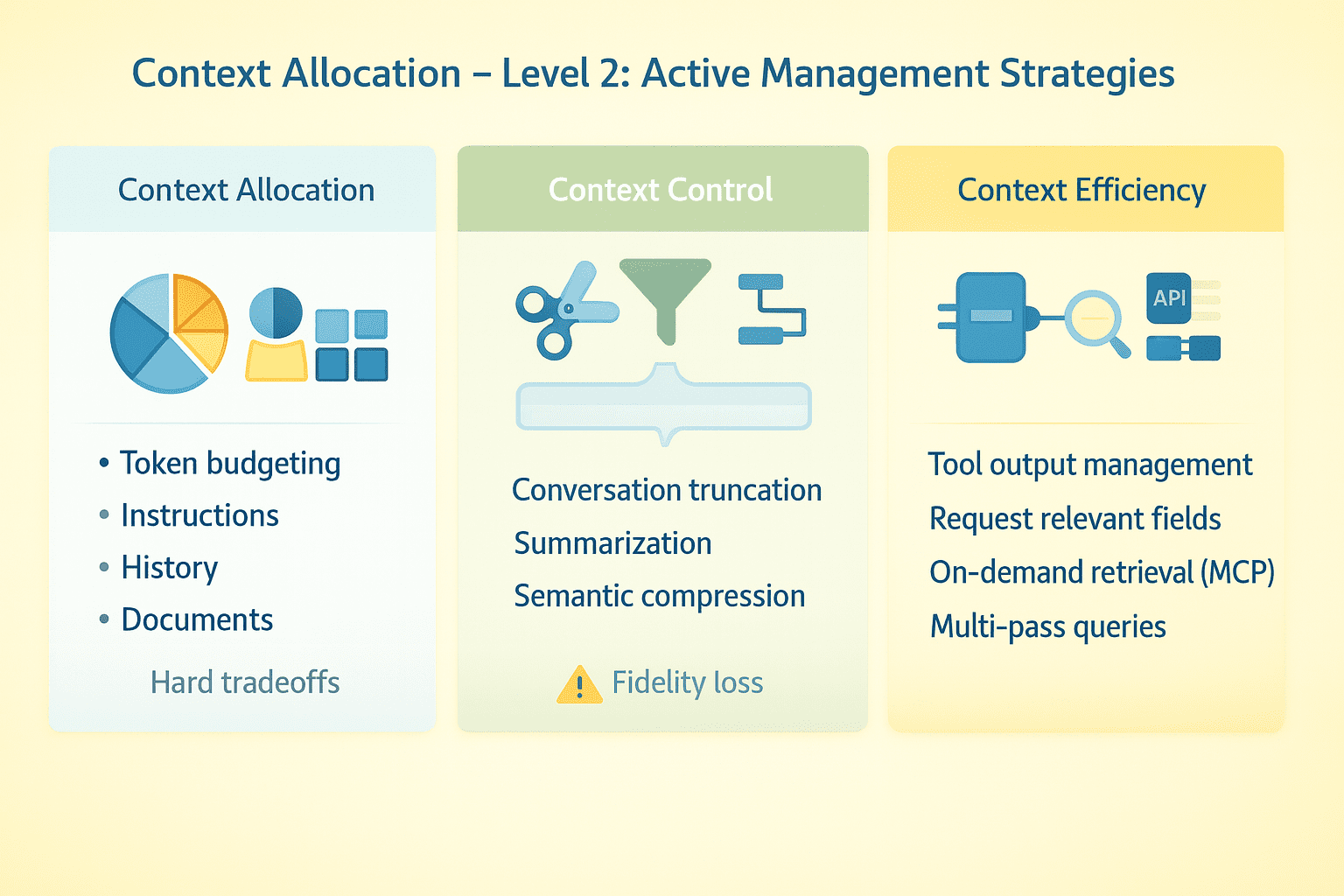
Главный сдвиг — контекст как динамический ресурс, требующий постоянного надзора на протяжении жизни агента, а не статичная настройка раз и навсегда.
Уровень 3: Инженерия контекста в продакшене
На масштабе нужны продуманные архитектуры памяти, методы сжатия и поисковые системы, работающие вместе. Вот как собирать надежные реализации.
Архитектуры памяти
Разделите память в агентных AI-системах на уровни:
- Рабочая память (текущее окно контекста).
- Эпизодическая память (сжатая история бесед и состояние задач).
- Семантическая память (факты, документы, база знаний).
- Процедурная память (инструкции).
Рабочая память оптимизируется под текущую задачу. Эпизодическая фиксирует события с сохранением связей во времени и причинно-следственных цепочек при сильном сжатии. Семантическую организуйте по темам, сущностям и релевантности для быстрого доступа.
Методы сжатия
Простое суммирование упускает детали. Лучше экстрактивное сжатие: отбирайте предложения с высокой плотностью информации, избавляясь от воды.
- Для выходов инструментов извлекайте структурированные данные (сущности, метрики, связи), а не текстовые обзоры.
- В беседах точно храните намерения пользователя и обязательства агента, сжимая цепочки рассуждений.
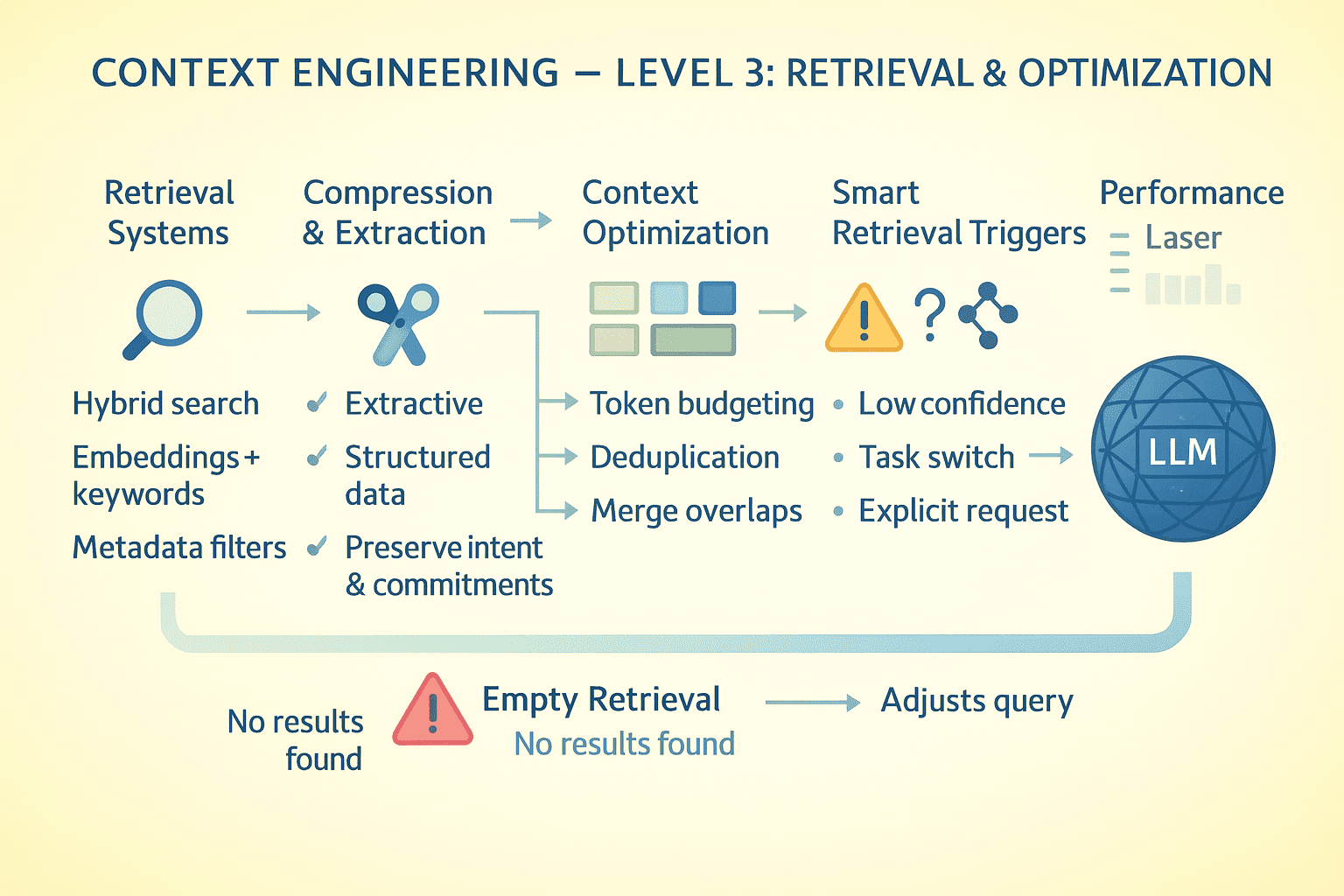
Системы поиска
При обращении к данным вне контекста качество поиска решает исход. Используйте гибридный поиск: плотные эмбеддинги для семантики, BM25 для ключевых слов и фильтры метаданных для точности.
Ранжируйте по свежести, близости к запросу и насыщенности данными. Возвращайте топ K, но показывайте близкие промахи — модель поймет контекст. Поиск интегрируется в контекст, модель видит формулировку запроса и итоги. Плохие запросы дают плохие результаты, поэтому давайте модели шанс на корректировку.
Оптимизация на уровне токенов
Постоянно анализируйте расход токенов.
- Системные инструкции жрут 5K токенов вместо 1K? Перепишите.
- Схемы инструментов многословны? Берите компактные
JSON-схемы вместо полныхOpenAPI-спецификаций. - Реплики в чате повторяются? Удаляйте дубликаты.
- Документы пересекаются? Объединяйте перед добавлением.
Каждый сэкономленный токен идет на полезную информацию.
Запуск поиска по памяти
Поиск не должен запускаться всегда — это дорого и замедляет. Настраивайте триггеры: явный запрос модели, пробелы в знаниях, смена задач или отсылка к прошлому.
Если поиск пустой, модель узнает об этом прямо: "Документов по запросу X в базе Y не найдено." Так она перефразирует запрос, сменив источник, или скажет пользователю, что данных нет.
Синтез из нескольких документов
Для анализа источников по иерархии.
- Первый этап: параллельно вытащите ключевые факты из каждого документа.
- Второй: загрузите факты в контекст и объедините.
Это экономит место вместо загрузки 10 полных текстов, сохраняя умение работать с множеством источников. При противоречиях оставьте их — пусть модель разбирается или отметит для пользователя.
Сохранение состояния беседы
Для агентов с паузами сериализуйте состояние во внешнее хранилище: сжатую историю, граф задач, выходы инструментов и кэш поиска. При возобновлении восстанавливайте минимум необходимого, не перезагружая все.
Оценка и метрики производительности
Следите за показателями. Измеряйте заполненность контекста (средний процент использования окна), частоту вытеснения (сколько раз упираетесь в лимит). Проверяйте точность поиска (доля релевантных документов). Фиксируйте сохранность информации (сколько шагов ключевые факты держатся).
Итоги
Инженерия контекста — это архитектура информации. Модель видит только то, что в окне, и ничего лишнего. Каждое решение о сжатии, поиске, кэшировании или удалении формирует среду приложения.
Без внимания к этому система начнет галлюцинировать, забывать детали или рушиться со временем. С правильным подходом LLM-приложение остается последовательным, надежным и эффективным в сложных длинных взаимодействиях, несмотря на базовые ограничения.