Исследователи из Китая и Гонконга представили свежую архитектуру памяти для ИИ-агентов, которая помогает сохранять данные в затяжных диалогах.
Память по-прежнему остается ахиллесовой пятой современных ИИ-агентов. В продолжительных беседах или заданиях модели натыкаются на ограничения контекстного окна или упускают важные нюансы — это явление называют "гниением контекста".
В свежей работе ученые предлагают "General Agentic Memory" (GAM) как выход из ситуации. Эта система объединяет сжатие информации с механизмом глубокого анализа, заимствуя идею "just-in-time compilation" из разработки ПО — там код оптимизируют прямо перед запуском.
Раньше системы полагались на заранее подготовленные краткие обзоры, но авторы считают, что такой подход всегда приводит к утечке данных. То, что кажется второстепенным на этапе хранения, может оказаться ключевым потом, но к тому моменту оно уже утеряно из-за сжатия.
Архитектура с двумя агентами
GAM работает на базе двух специализированных модулей: "Memorizer" и "Researcher". "Memorizer" функционирует в фоновом режиме во время общения. Он генерирует базовые обзоры, но при этом сохраняет всю историю разговора в хранилище под названием "page store". Диалог разбивается на страницы, которые помечаются контекстными метками для упрощения поиска.
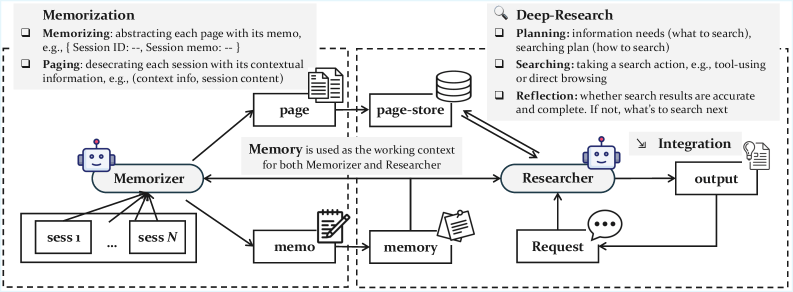
"Researcher" включается только при поступлении конкретного запроса. Вместо простого просмотра памяти он выполняет "глубокий анализ" — разбирает вопрос, составляет план поиска и применяет инструменты для изучения "page store". В арсенале три подхода: векторный поиск по тематическому сходству, BM25 для точного совпадения ключевых слов или прямой доступ по идентификаторам страниц. Процесс идет по кругу: агент проверяет результаты, оценивает полноту и, если данных мало, запускает дополнительные запросы, прежде чем выдать ответ.
Превосходство над RAG и моделями с длинным контекстом
Разработчики сравнили GAM с традиционными методами, такими как Retrieval-Augmented Generation (RAG), и моделями с обширными контекстными окнами — GPT-4o-mini и Qwen2.5-14B.
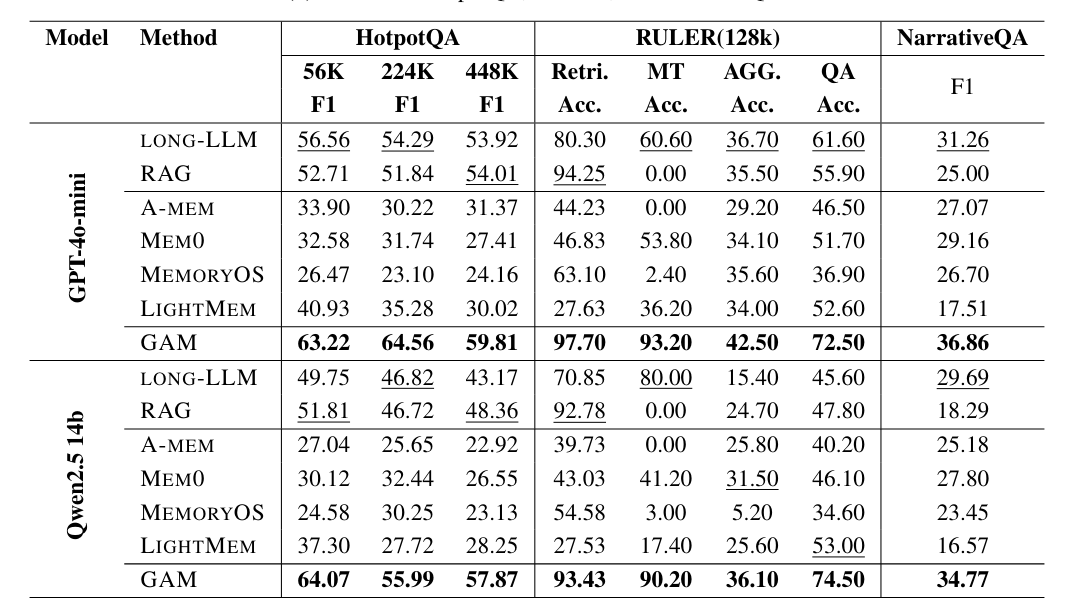
Как указано в статье, GAM обошла соперников во всех тестах. Разрыв был максимальным в сценариях, где нужно связывать данные через множество шагов. В бенчмарке RULER, который проверяет отслеживание переменных на длинных последовательностях, GAM достигла точности свыше 90 процентов, в то время как RAG и другие хранилища в основном провалились.
Авторы объясняют успех GAM ее циклическим поиском, который вылавливает детали, ускользающие от сжатых обзоров. Система также хорошо адаптируется к ресурсам: больше шагов для "Researcher" и времени на размышления повышают качество ответов.
Код проекта и данные доступны на GitHub.
Новые идеи в управлении контекстом
Другие команды тоже решают задачу с памятью. Anthropic недавно перешла к "context engineering", где активно формируют весь контекст с помощью кратких обзоров или организованных заметок, а не только улучшают промты.
Аналогично, Deepseek запустила систему OCR, которая превращает текстовые документы в сильно сжатые изображения. Такой метод экономит вычисления и токены, и может стать удобным способом долгосрочного хранения для чат-ботов — старые части бесед сохраняются как файлы картинок.
В то же время, ученые из Шанхая предложили "Semantic Operating System", которая станет пожизненной памятью для ИИ. Эта платформа управляет контекстом подобно человеческому мозгу: выбирает, что адаптировать или забыть, превращая временные данные в устойчивые, организованные воспоминания.