Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Традиционные системы радиолокации и РЭБ не справляются с модально-гибкими излучателями. Когнитивные архитектуры на основе ИИ обеспечивают автономную классификацию угроз и генерацию контрмер в реальном времени. В техническом документе рассмотрены ключевые технологии, вызовы и методы тестирования таких систем.
Подборка из пяти бесплатных курсов от Harvard, Google, fast.ai, Hugging Face и Андрея Карпаты, которая последовательно превращает новичка со знанием Python в практикующего ИИ-инженера, способного создавать LLM с нуля.
Исследователи из Принстона создали ИИ-систему, которая самостоятельно проектирует радиочастотные интегральные схемы (RFIC) без шаблонов, достигая рекордных характеристик. Используя обучение с подкреплением и диффузионные модели, алгоритм генерирует нестандартные, но эффективные топологии за считанные минуты, преодолевая ограничения традиционного «искусства» проектирования.
Статья к 70-летию искусственного интеллекта охватывает путь технологии от первых нейросетей до трансформеров и агентных систем. Рассмотрены ключевые вехи, сильные и слабые стороны, вклад IEEE в исследования, стандарты и образование. Особое внимание уделено рискам ИИ и необходимости ответственного развития.
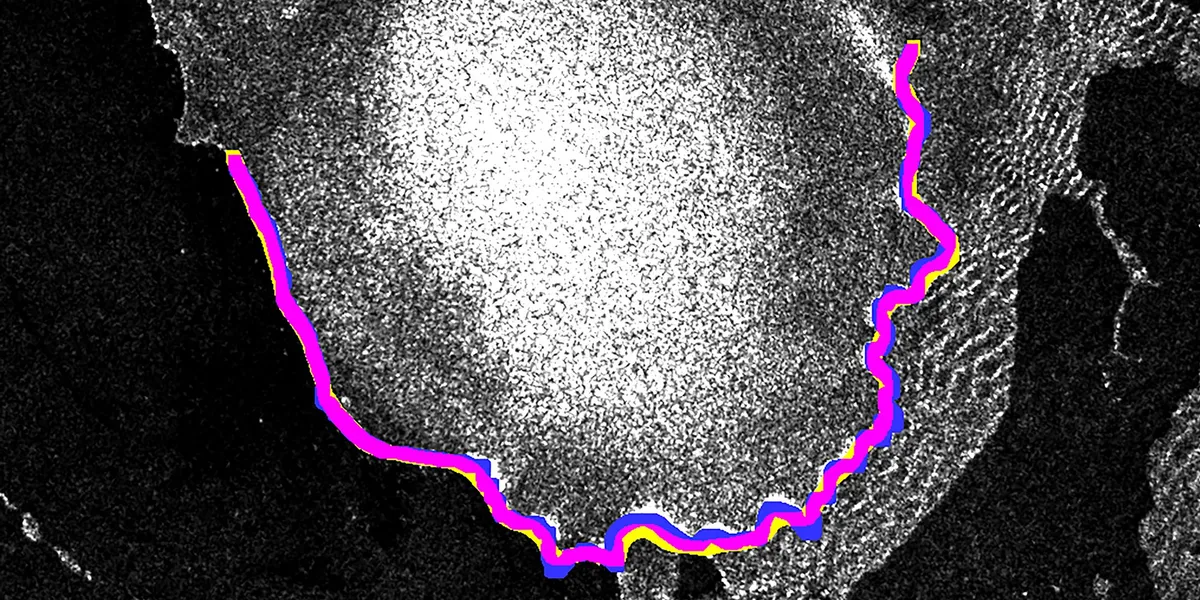
Исследователи из Университета Эрлангена-Нюрнберга разработали метод адаптации моделей глубокого обучения для отслеживания фронтов отёла ледников. Благодаря добавлению всего одного размеченного снимка, летних референсных изображений и карты подстилающих пород погрешность модели сократилась с более километра до 68,7 метров. Метод уже опробован на ледниках Шпицбергена и может быть масштабирован на Арктику, ускоряя климатические исследования.
MATLAB и Simulink предлагают инструменты для полного цикла разработки ИИ-виртуальных датчиков. Процесс включает проектирование, обучение, формальную верификацию, сжатие модели и генерацию кода. Это позволяет быстро разворачивать решения на встраиваемых процессорах.
Специалисты MIT научились использовать отходящее тепло устройств для аналоговых вычислений без электричества, выполняя умножение матрицы на вектор с точностью выше 99%. Метод перспективен для глубокого обучения, но требует доработки масштаба. Уже сейчас он помогает мониторить температуру без датчиков.
Cognichip разрабатывает ИИ для ускорения проектирования чипов, обещая сократить затраты на 75% и сроки вдвое. Компания привлекла $60 млн под руководством Seligman Ventures, собрав всего $93 млн с 2024 года. Технология использует специализированные данные и конкурирует с Synopsys, Cadence и новыми стартапами.
В статье предлагается новая метрика — коэффициент Джинна — для оценки того, насколько ИИ-агенты отклоняются от разумного выполнения пользовательских запросов. Из-за недоопределенности языка и целей ИИ склонны к неожиданным действиям, что может приводить к серьезным ошибкам. Разработка бенчмарков на основе этой метрики поможет создавать более безопасных агентов.
Лауреат премии Тьюринга Рич Саттон вместе с Хуррамом Джаведом запустил стартап Oak Lab, который займется созданием ИИ-агентов, обучающихся на собственном опыте. Саттон критикует современные методы глубокого обучения и выступает за непрерывное обучение в реальном времени. Долгосрочная цель — агент с триллионом параметров, способный учиться и планировать при мощности 20 ватт.
Макс Сперо, CEO сервиса Pangram, объяснил, что нейросети создают тексты с повторяющимися аргументами, что выдаёт их искусственное происхождение. Детектор Pangram анализирует структурные паттерны, которые оставляют языковые модели, хотя принцип его работы до конца не ясен даже разработчикам.
Кейси Харрелл с БАС почти три года использует речевой мозговой имплант, который декодирует его мысли в слова с точностью 99%. Устройство позволило ему вернуться к работе и общению с семьёй, а исследователи продолжают совершенствовать систему, стремясь восстановить полноценный голос.
Исследователи из Университета Твенте применили динамическое масштабирование напряжения и частоты (DVFS) на уровне ядер GPU и сократили энергопотребление при обучении модели GPT-3-xl на 14%, практически не замедлив процесс. Метод основан на точной настройке тактовых частот для каждой вычислительной операции, что позволяет экономить энергию без потери производительности.
Энкодеры — основа понимания ИИ, эволюционировавшие от ручного преобразования данных к мультимодальным системам для текста и изображений. Они решают задачи в рекомендациях, медицине, шопинге и мошенничестве. Дальше ждут оптимизация, персонализация и этические улучшения.
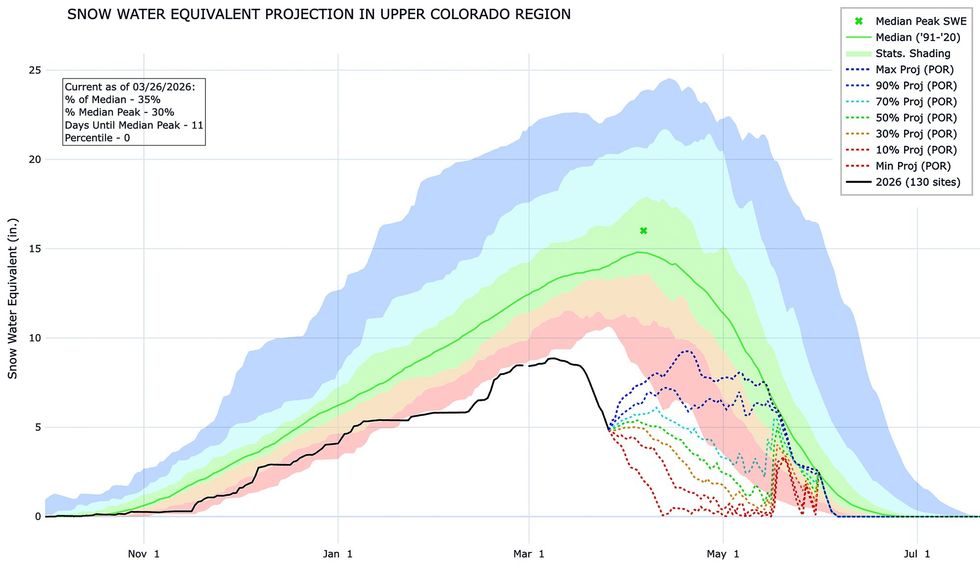
ИИ-инструменты помогают моделировать сценарии для реки Колорадо, где сток упал на 20% и переговоры провалились. Бюро по рекультивации проводит миллионы симуляций, а новые системы на базе глубокого обучения и эволюционных алгоритмов вроде Borg прогнозируют сток и засухи. Модели выявляют компромиссы, но не решают вопрос распределения потерь между штатами и секторами.
Финансовые организации переходят к безопасному ИИ, чтобы ускорить доходы и избежать рисков. Надёжное управление данными, мониторинг и защита от атак позволяют быстро выводить продукты на рынок без штрафов. Это превращает регуляции в преимущество, а не обузу.