Введение
Фундаментальные модели появились задолго до ChatGPT. Еще раньше предобученные сети продвигали развитие в компьютерном зрении и обработке естественного языка, помогая с сегментацией изображений, классификацией и пониманием текста.
Сегодня такой подход меняет прогнозирование временных рядов. Эти модели обучают заранее на огромных и разнообразных наборах временных данных. В результате они дают точные прогнозы без дополнительной настройки для конкретных задач — по разным областям, частотам и горизонтам. Часто они превосходят глубокие сети, которые требуют часов обучения только на исторических данных.
Если вы по-прежнему полагаетесь в основном на классические статистические методы или модели, заточенные под один датасет, то упускаете ключевой сдвиг в создании систем прогнозирования.
Здесь мы разберем пять фундаментальных моделей для временных рядов. Выбор основан на их производительности, популярности по скачиваниям на Hugging Face и удобстве в реальных задачах.
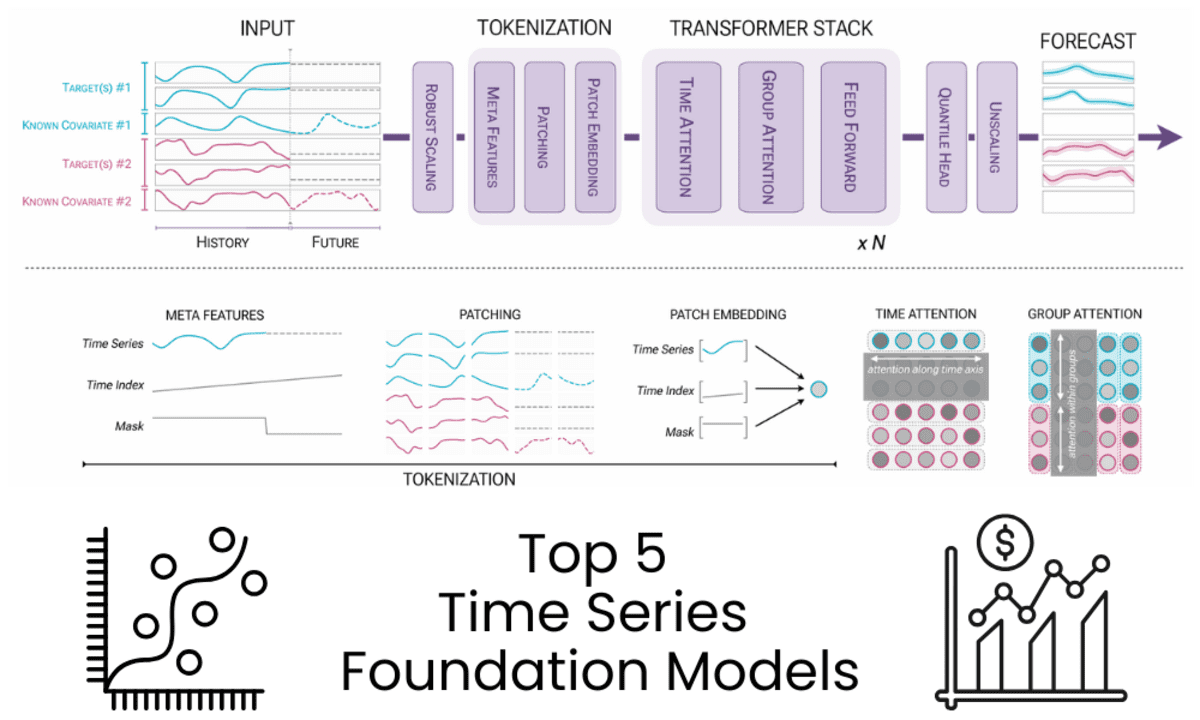
1. Chronos-2
Chronos-2 — это модель с 120 млн параметров, использующая только энкодер для прогнозирования без дообучения. Она работает с однородными, многомерными рядами и учитывает ковариаты в единой архитектуре, выдавая вероятностные прогнозы на несколько шагов вперед без специальной подготовки под задачу.
Основные возможности:
- Архитектура энкодера, вдохновленная T5
- Прогнозирование без дообучения с квантильными выходами
- Поддержка прошлых и известных будущих ковариат
- Длина контекста до 8192, горизонт прогноза до 1024
- Быстрый вывод на CPU и GPU с высокой пропускной способностью
Применение:
- Масштабное прогнозирование по множеству связанных рядов
- Прогнозы с учетом ковариат для спроса, энергетики и ценообразования
- Быстрое прототипирование и запуск в продакшн без обучения модели
Идеальные сценарии:
- Производственные системы прогнозирования
- Исследования и бенчмаркинг
- Сложное многомерное прогнозирование с ковариатами
2. TiRex
TiRex — предобученная модель с 35 млн параметров на базе xLSTM для прогнозирования без дообучения на длинных и коротких горизонтах. Она выдает точные прогнозы точечные и вероятностные сразу, без настройки под данные задачи.
Основные возможности:
- Архитектура на базе предобученного xLSTM
- Прогнозирование без дообучения на конкретных датасетах
- Точечные прогнозы и оценки неопределенности на основе квантилей
- Хорошие результаты на бенчмарках длинных и коротких горизонтов
- Опциональное ускорение на CUDA для GPU
Применение:
- Прогнозирование без дообучения для новых или неизвестных датасетов
- Долгосрочные и краткосрочные прогнозы в финансах, энергетике и операциях
- Быстрый бенчмаркинг и деплой без обучения модели
3. TimesFM
TimesFM — предобученная фундаментальная модель от Google Research для прогнозирования без дообучения. Открытая версия timesfm-2.0-500m использует только декодер для однородных рядов, поддерживая длинные исторические контексты и гибкие горизонты без настройки.
Основные возможности:
- Фундаментальная модель декодера с чекпоинтом 500 млн параметров
- Прогнозирование однородных временных рядов без дообучения
- Длина контекста до 2048 точек, с поддержкой за пределами обучения
- Гибкие горизонты прогноза с опциональными индикаторами частоты
- Оптимизация для быстрых точечных прогнозов в масштабе
Применение:
- Масштабное прогнозирование однородных рядов по разным датасетам
- Долгосрочные прогнозы для операционных и инфраструктурных данных
- Быстрые эксперименты и бенчмаркинг без обучения модели
4. IBM Granite TTM R2
Granite-TimeSeries-TTM-R2 — семейство компактных предобученных моделей от IBM Research в рамках TinyTimeMixers (TTM). Они заточены под многомерное прогнозирование, показывают сильные результаты в zero-shot и few-shot режимах при размерах от 1 млн параметров, подходят для исследований и сред с ограниченными ресурсами.
Основные возможности:
- Компактные предобученные модели от 1 млн параметров
- Сильные результаты в zero-shot и few-shot для многомерных рядов
- Специализированные модели под конкретные длины контекста и горизонта
- Быстрый вывод и дообучение на одном GPU или CPU
- Поддержка экзогенных переменных и статических категориальных признаков
Применение:
- Многомерное прогнозирование в средах с низкими ресурсами или на краю
- Zero-shot базовые линии с опциональным легким дообучением
- Быстрый деплой для операционного прогнозирования с малым объемом данных
5. Toto Open Base 1
Toto-Open-Base-1.0 — модель декодера для многомерного прогнозирования в задачах мониторинга и наблюдаемости. Оптимизирована под высокомерные, разреженные и нестационарные данные, показывает отличные zero-shot результаты на бенчмарках GIFT-Eval и BOOM.
Основные возможности:
- Трансформер-декодер с гибкими длинами контекста и предсказаний
- Прогнозирование без дообучения
- Эффективная работа с высокомерными многомерными данными
- Вероятностные прогнозы на базе смеси Student-T
- Предобучение на более чем двух триллионах точек временных рядов
Применение:
- Прогнозирование метрик в наблюдаемости и мониторинге
- Высокомерная телеметрия систем и инфраструктуры
- Zero-shot прогнозирование для масштабных нестационарных рядов
Итоги
В таблице ниже сравниваются ключевые характеристики рассмотренных фундаментальных моделей временных рядов: размер, архитектура и возможности прогнозирования.
| Модель | Параметры | Архитектура | Тип прогнозирования | Ключевые сильные стороны |
|---|---|---|---|---|
| Chronos-2 | 120M | Только энкодер | Одномерные, многомерные, вероятностные | Высокая точность zero-shot, длинный контекст и горизонт, высокая пропускная способность вывода |
| TiRex | 35M | На базе xLSTM | Одномерные, вероятностные | Легковесная модель с сильными результатами на коротких и длинных горизонтах |
| TimesFM | 500M | Только декодер | Одномерные, точечные прогнозы | Работает с длинными контекстами и гибкими горизонтами в масштабе |
| Granite TimeSeries TTM-R2 | 1M–малые | Специализированные предобученные модели | Многомерные, точечные прогнозы | Крайне компактные, быстрый вывод, сильные zero- и few-shot результаты |
| Toto Open Base 1 | 151M | Только декодер | Многомерные, вероятностные | Оптимизирована под высокомерные нестационарные данные наблюдаемости |