Обучение с подкреплением сталкивается с ограничениями в моделях рассуждений, так как все токены получают равную награду. Алгоритм FIPO от команды Qwen Alibaba устраняет этот недостаток, распределяя награды по шагам в зависимости от их влияния на дальнейший процесс, что позволяет удвоить протяженность цепочек мышления.
При обучении больших языковых моделей рассуждению через механизм с подкреплением обычно выносится простое решение о успехе или неудаче в конце сгенерированного ответа. Эта награда равномерно распределяется по всем токенам последовательности, независимо от того, является ли токен поворотным моментом логики или простой запятой.
Разработчики из Qwen считают, что такая грубая схема распределения наград — главная причина, по которой модели рассуждений достигают предела при использовании популярных методов вроде GRPO (Group Relative Policy Optimization). Цепочки рассуждений вырастают до определенной длины и затем перестают развиваться.
FIPO (Future-KL Influenced Policy Optimization) призван преодолеть этот барьер. Вместо оценки каждого токена по отдельности алгоритм смотрит вперед: как генерация этого токена меняет поведение модели в последующих шагах?
FIPO вычисляет суммарный сдвиг вероятностей по всем токенам, идущим дальше, и использует этот показатель для точного распределения наград. Шаги, запускающие продуктивную цепочку рассуждений, получают больше; те, что уводят в тупик, — меньше.
FIPO на уровне методов PPO без дополнительной модели
Раньше проблему равномерных наград пытались решить с помощью методов на базе PPO, где отдельная модель оценки определяла пользу для каждого токена.
Такая вспомогательная модель обычно требует предварительного обучения на длинных данных цепочек рассуждений, что приводит к утечке внешних знаний. Авторы отмечают: сложно понять, идут ли улучшения от самого алгоритма или от предобученного помощника. FIPO обходитсь без него и показывает сопоставимые результаты.
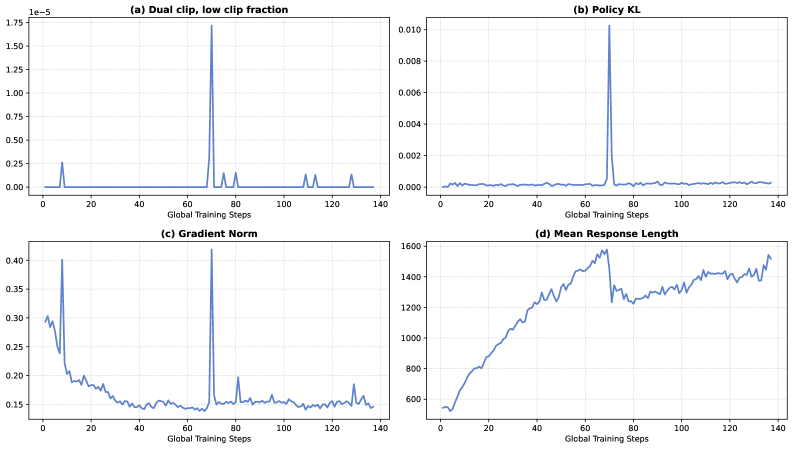
Для стабильности обучения FIPO включает защитные механизмы. Фактор дисконтирования придает больший вес близким токенам, чем дальним, поскольку влияние последних предсказать сложнее.
Алгоритм также отсекает токены с чрезмерным расхождением модели между шагами обучения. Без этого фильтра возникали серьезные нестабильности: процесс сходил с рельсов, а длина ответов резко падала.
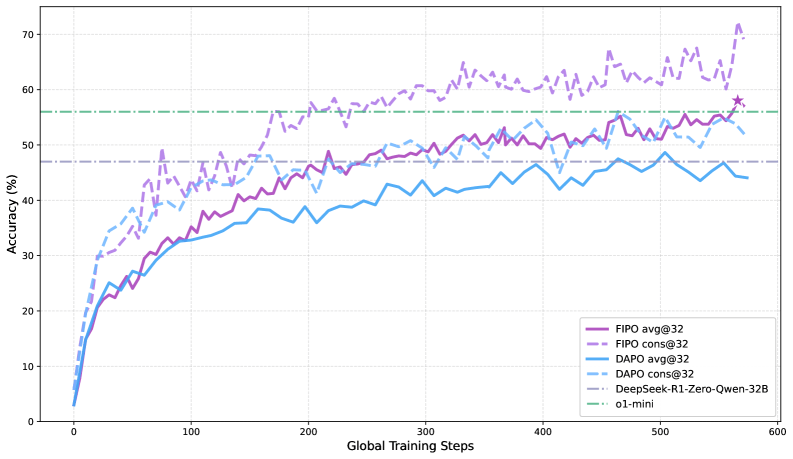
Длина цепочек рассуждений удваивается, точность растет
Тестирование прошло на Qwen2.5-32B-Base — модели без предварительного опыта с синтетическими длинными данными CoT. Обучение велось исключительно на публичном датасете DAPO (Decoupled Clip and Dynamic sAmpling Policy Optimization) — варианте GRPO с открытым кодом, чтобы обеспечить честное сравнение.
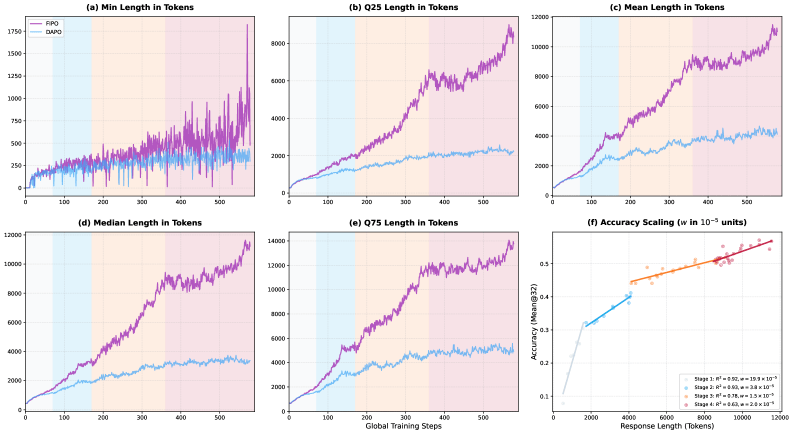
Результаты однозначны. Средняя длина цепочки рассуждений у DAPO застревает на 4000 токенах, FIPO выходит за 10 000. На математическом бенчмарке AIME 2024 точность подскакивает с 50% до 56%, с пиком в 58%. Это опережает DeepSeek-R1-Zero-Math-32B (около 47%) и o1-mini от OpenAI (около 56%). На более сложном AIME 2025 показатели поднимаются с 38% до 43%.
Авторы подчеркивают: рост касается не отдельных выбросов, а всего распределения длин ответов — от коротких до длинных. Это указывает на кардинальное изменение подхода модели к задачам.
Модель начинает проверять себя сама
В статье описаны четыре фазы эволюции модели во время обучения. Сначала она выдает поверхностные шаблоны планирования — контуры без настоящей математики, завершающиеся галлюцинированным ответом. На второй фазе, где застревают модели на DAPO, идет чистая линейная цепочка рассуждений с остановкой на первом найденном решении.
На третьей фазе модель самостоятельно перепроверяет промежуточные результаты. Достигнув ответа, она переключается на другой метод — скажем, с алгебры на геометрию — для подтверждения. К четвертой фаза модель проводит систематическую многопроходную верификацию: пересчитывает большие квадраты поэтапно и повторно проходит полную дедукцию.
Такое поведение напоминает стратегии масштабирования на этапе вывода в o-серии OpenAI и DeepSeek-R1, но FIPO достигает его чисто через обучение с подкреплением, без синтетических данных CoT.
Пока только начало
FIPO проверили только на математических задачах, на одном датасете и на базовых моделях без предобучения на длинных CoT. Длинные последовательности повышают вычислительные затраты. Команде предстоит много дополнительных тестов.
Остается открытым вопрос, перейдут ли улучшения в другие области вроде кода или символической логики. Есть и разрыв в производительности по сравнению с дистилляцией из более крупных учителей: чистое обучение с подкреплением уступает прямому переносу знаний от сильной модели.
Разработчики обещают открыть код системы обучения со всеми настройками.