Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
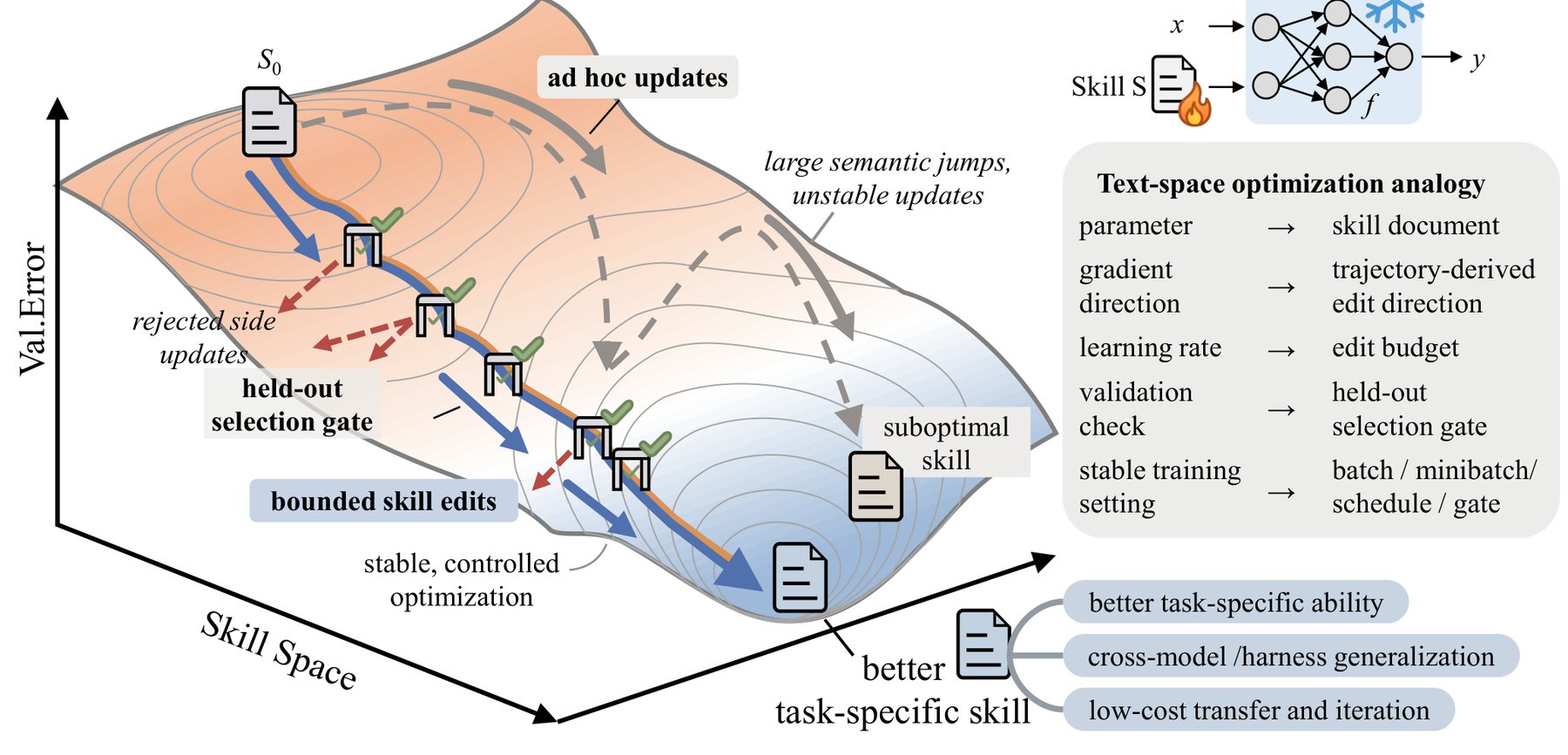
Метод SkillOpt, предложенный Microsoft и тремя университетами, обучает документы с инструкциями для ИИ-агентов подобно весам нейросетей. Это позволяет значительно улучшить производительность GPT-5.5 на процедурных задачах — в среднем на 23 балла. Обученные навыки компактны, переносимы между моделями и не требуют изменения самой модели.
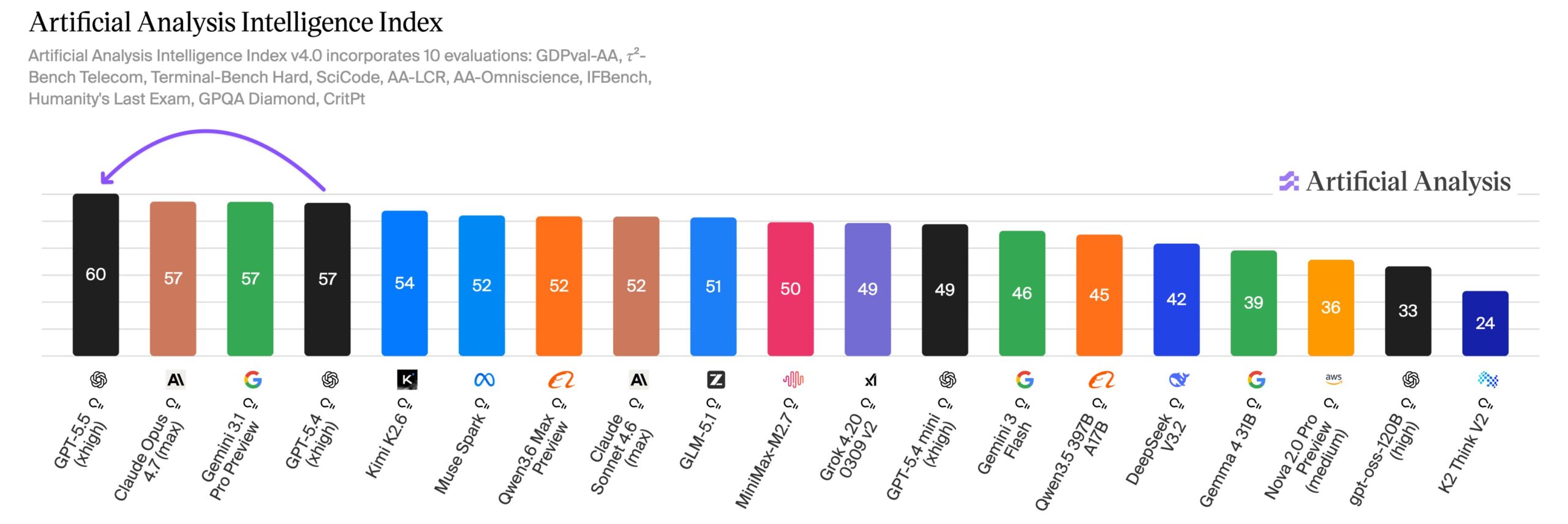
GPT-5.5 возглавила Intelligence Index Artificial Analysis с 60 очками, опередив Claude Opus 4.7 и Gemini 3.1 Pro Preview на три пункта. Удвоение цены API смягчено экономией 40% токенов, итого рост на 20%, но галлюцинаций стало 86% — хуже конкурентов. Бенчмарки хвалят цену-производительность, однако в программировании и галлюцинациях модель не без изъянов.
Сооснователь OpenAI Грег Брокман заявил, что модели GPT reasoning имеют прямой путь к AGI, и споры об этом завершены. OpenAI свернула Sora, сосредоточившись на GPT из-за ресурсов, несмотря на ценность world models. Исследователи вроде ЛеКуна, Хассабиса, Шолле и других сомневаются в текстовых LLM и предлагают альтернативы вроде симуляций.
OpenAI представила метрику CoT controllability для оценки контроля цепочки мыслей в моделях ИИ вроде GPT-5.4 Thinking, где успех составляет всего 0,3%. Низкие показатели радуют, поскольку затрудняют маскировку вредных намерений от систем мониторинга. Исследование с открытым инструментом CoT-Control подтверждает: модели плохо справляются с таким контролем.
OpenAI отключает доступ к пяти старым моделям ChatGPT, включая проблемную GPT-4o, которая лидирует по подхалимству и фигурирует в исках о вреде для психики. Несмотря на низкий процент использования (0,1%), это затрагивает сотни тысяч человек. Пользователи протестуют, ссылаясь на эмоциональную привязанность к модели.
OpenAI 13 февраля 2026 года убирает из ChatGPT GPT-4o, GPT-4.1, GPT-4.1 mini и o4-mini из-за малого использования — всего 0,1% ежедневно. Модели останутся в API, а фокус сместится на GPT-5.1 и GPT-5.2 с настройкой стиля. Фанаты старой модели могут не оценить замену.
Модель GPT-5.2 Pro от OpenAI установила рекорд на сложном бенчмарке FrontierMath, решив 15 из 48 задач на Tier 4 с результатом 31%. Это опережает Gemini 3 Pro и подтверждает полезность ИИ в математике, хотя Теренс Тао предостерегает от поспешных оценок. Математики отметили сильные стороны решений, но указали на пробелы в объяснениях.
Теренс Тао сообщил, что GPT-5.2 Pro самостоятельно решил задачу Эрдёша №728, но подчеркнул: ценность в скорости создания текстов, а не в сложности проблемы. Он предупреждает учитывать контекст и отмечает, что сложные вопросы требуют совместной работы ИИ и людей. Лишь малая доля задач готова для полной автономии моделей.
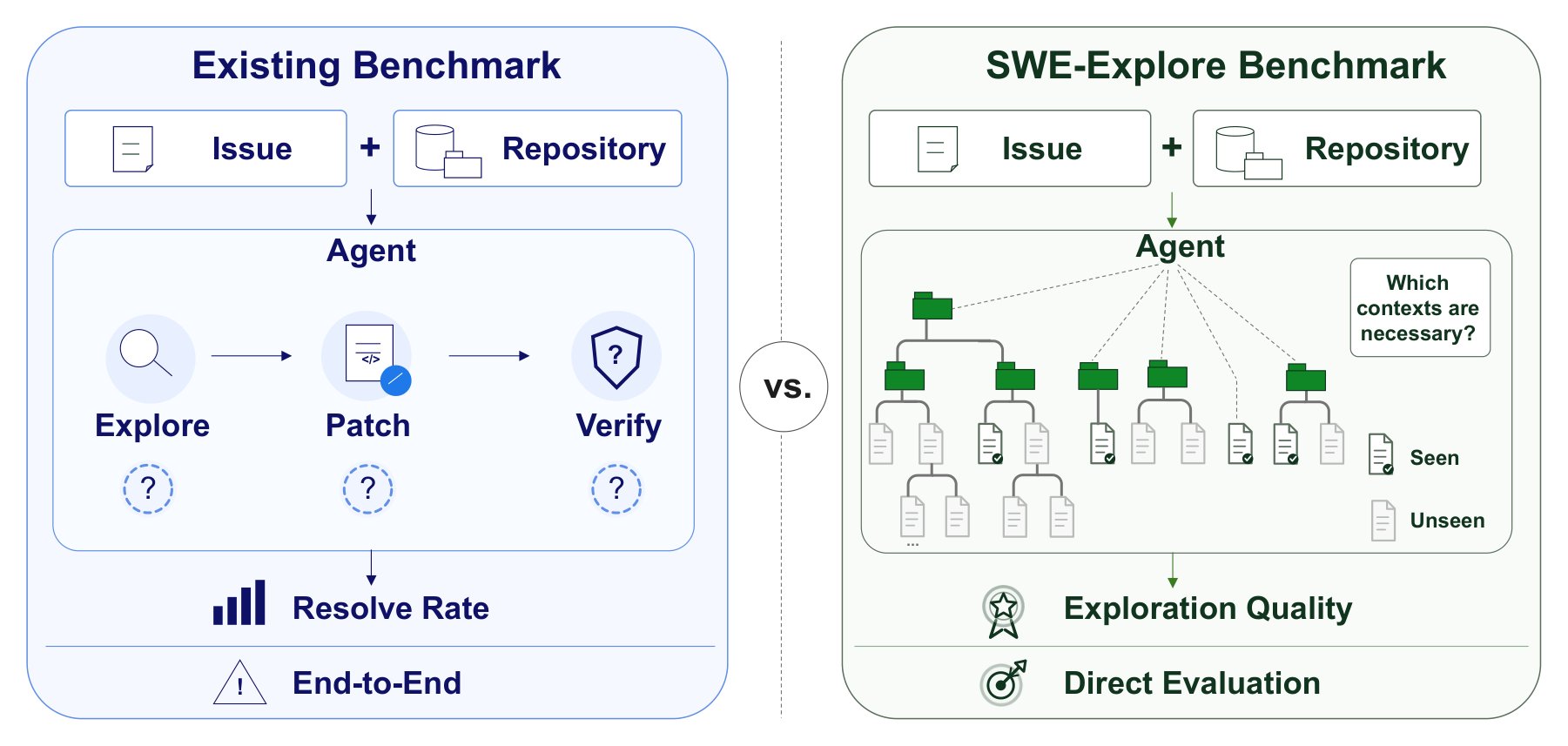
Новый бенчмарк SWE-Explore оценивает способность ИИ-агентов находить релевантный код, изолируя этап поиска от исправления. Исследование показало: агенты хорошо определяют файл, но покрывают лишь 14–19% значимых строк. При недостатке контекста (менее 50% ключевых зон) исправления почти всегда проваливаются.
Модель GPT-5.4 Pro от OpenAI решила открытую проблему Эрдёша №1196 за 80 минут и подготовила LaTeX-документ. Теренс Тао и Кевин Баррето отметили новую связь целых чисел с марковскими процессами. Это пример, как ИИ находит скрытое знание в известных данных.
Сотрудники OpenAI своими постами в X вызвали обсуждения новой омни-модели как преемницы GPT-4o. Исследователь Brandon McKinzie поддержал идею улучшений. Компания параллельно создает аудио BiDi для естественных прерываемых диалогов с прототипом, который пока нестабилен.
OpenAI выпустила GPT-5.4 — мощную модель для профзадач с контекстом 1 млн токенов и версиями Pro и Thinking. Она бьет рекорды в бенчмарках вроде OSWorld и APEX-Agents, снижает ошибки на 33% и вводит Tool Search для инструментов. Новая оценка подтверждает безопасность цепочки мыслей.
Китайская Zhipu AI открыла GLM-5 с 744 млрд параметров под лицензией MIT — модель конкурирует с Claude Opus 4.5 и GPT-5.2 в кодинге и агентных задачах, генерирует документы и работает на китайском железе. Китайские лаборатории ускоряют темпы, сокращая отставание от Запада.
OpenAI и Ginkgo Bioworks создали автономную лабораторию, где GPT-5 управляет оптимизацией бесклеточного синтеза белков. За шесть циклов затрат снизились на 40 процентов, выход вырос на 27 процентов, но есть ограничения по применимости и необходимость человеческого контроля. Проект поднимает вопросы биобезопасности.
GPT-5.2 Pro от OpenAI решил проблему №281 Пола Эрдёша из теории чисел, что Теренс Тао назвал одним из самых убедительных примеров успеха ИИ в математике. Однако новая база данных выявляет, что попытки ИИ обычно терпят неудачу в 98–99% случаев, особенно на сложных задачах. Тао подчёркивает полезность ИИ как инструмента, но предупреждает о риске переоценки его возможностей.
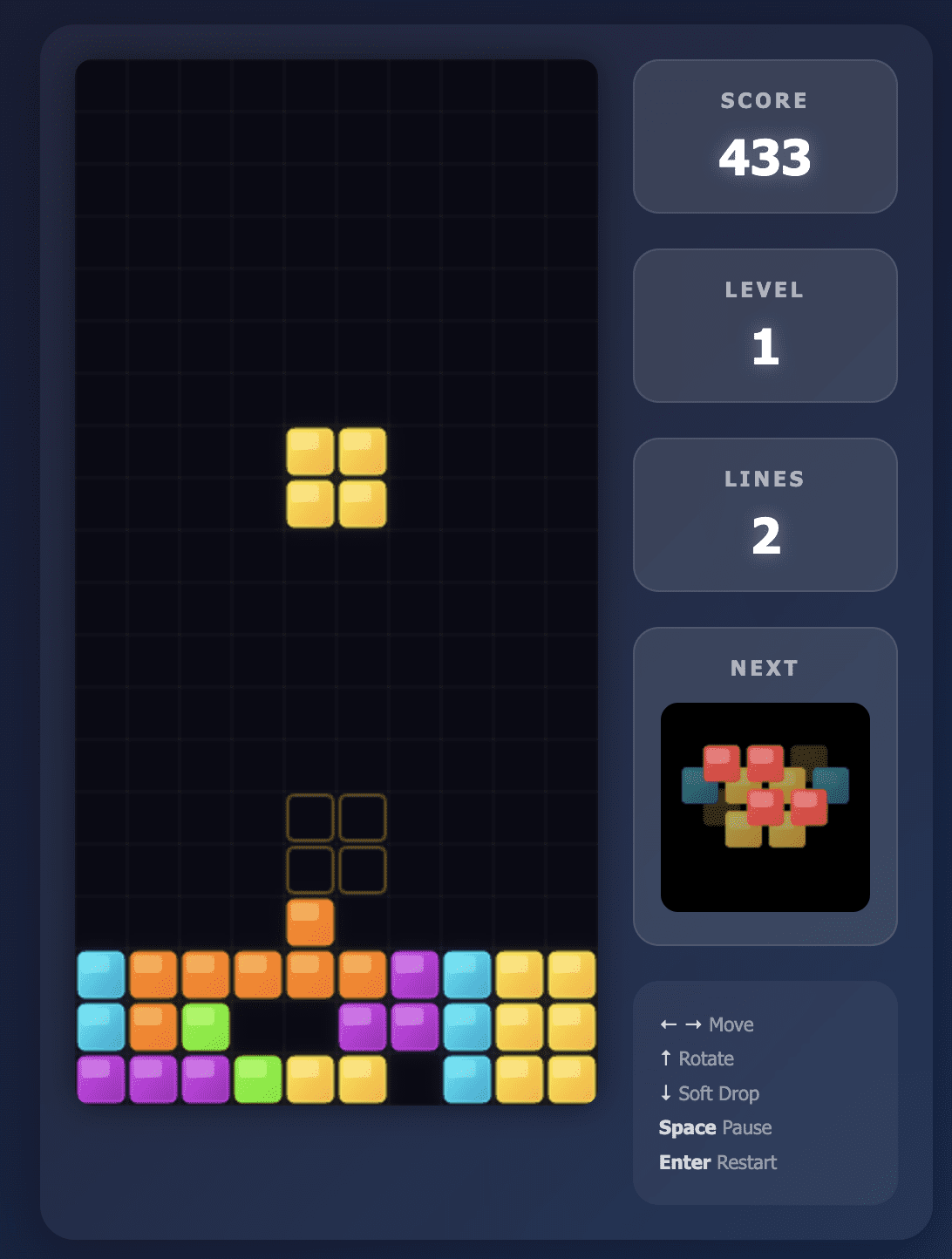
Три топовые ИИ-модели протестировали на создании Тетриса одним промтом: Claude Opus 4.5 выдала идеальную версию сразу, GPT-5.2 Pro потребовала правок и дала посредственный результат, DeepSeek V3.2 оказалась дешевой, но с серьезными багами. Opus 4.5 показал лучший баланс цены, скорости и качества. Для кодинга на каждый день она оптимальна.