Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Google официально представила на конференции I/O масштабный редизайн поисковой строки, превращая её из поля для ключевых слов в мультимодальный ИИ-интерфейс для бесед. Одновременно компания объединила функции AI Overviews и AI Mode в единый бесшовный поисковый опыт и показала рекордные темпы роста ИИ-поиска — 1 млрд пользователей в месяц для AI Mode и 2,5 млрд для обзоров.
Alibaba выпустила омнимодальную модель Qwen3.5-Omni, которая лидирует в аудиозадачах над Gemini 3.1 Pro и неожиданно обрела способность генерировать код по голосовым инструкциям и видео. Версия Plus установила рекорды на 215 бенчмарках, расширила языковую поддержку до 113 языков и ввела ARIA для естественного синтеза речи в реальном времени. Выпуск произошел на фоне ухода ключевых разработчиков.
Энкодеры — основа понимания ИИ, эволюционировавшие от ручного преобразования данных к мультимодальным системам для текста и изображений. Они решают задачи в рекомендациях, медицине, шопинге и мошенничестве. Дальше ждут оптимизация, персонализация и этические улучшения.
Исследователи создали LPM 1.0 — ИИ для генерации видео в реальном времени из одного фото с лип-синком, мимикой и эмоциями, стабильных до 45 минут. Модель различает состояния разговора, работает с фотореализмом, аниме и 3D без дообучения. Пока проект закрыт, без релиза из-за deepfake-рисков.
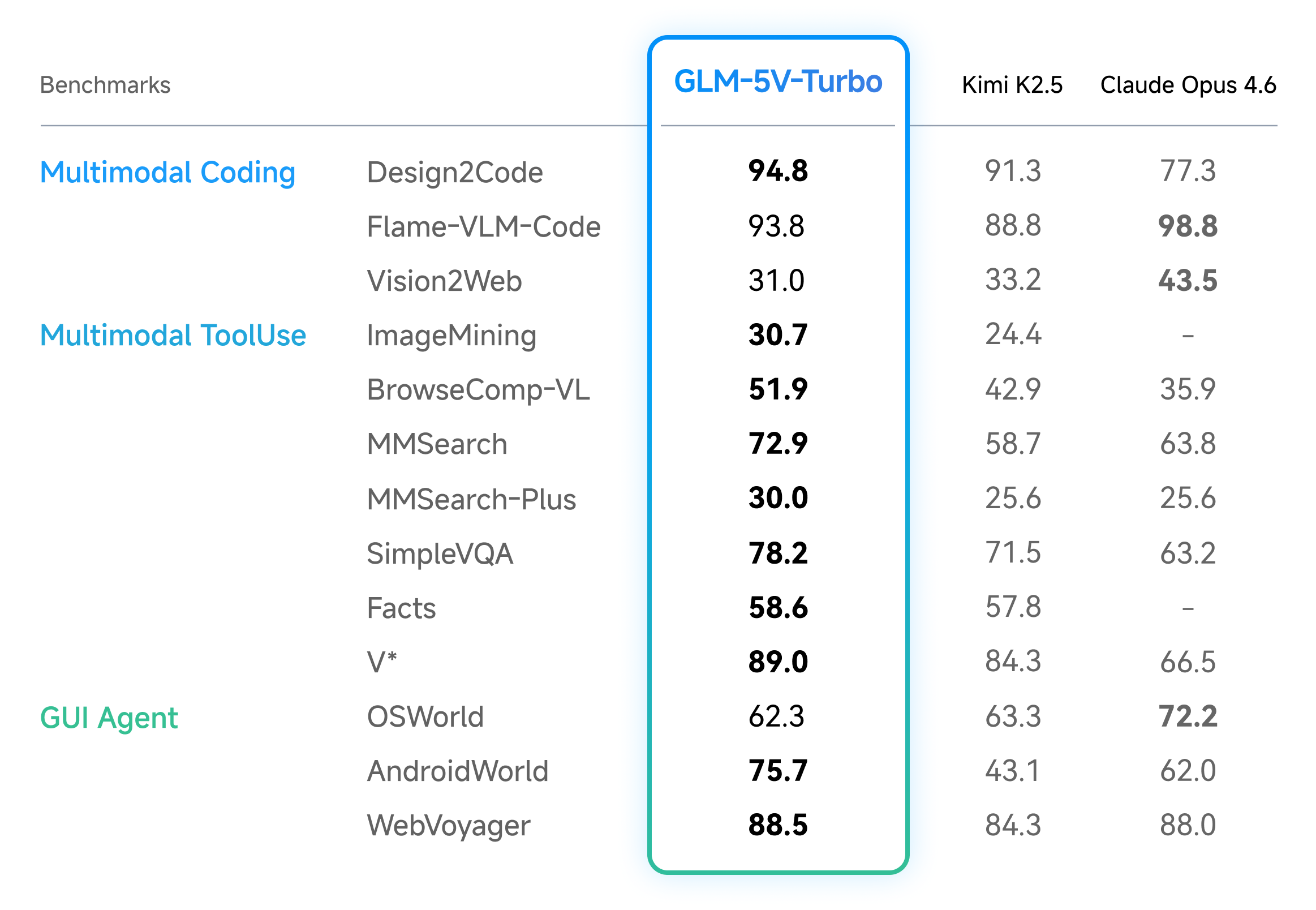
Zhipu AI представила GLM-5V-Turbo — мультимодальную модель, которая превращает дизайн-макеты в исполняемый фронтенд-код и интегрируется в агенты вроде OpenClaw. Она лидирует в бенчмарках по мультимодальному кодингу и GUI-задачам, сохраняя силу в текстовых тестах. Модель доступна через API по цене $1.20/млн входных и $4/млн выходных токенов.
Китай в 15-м Пятилетнем плане обозначил цели по ИИ до 2030 года: от чипов и моделей до инфраструктуры и регуляций. Фокус на вычислительных кластерах, мультимодальном ИИ и применении в экономике, услугах, госуправлении. Страна делает ставку на открытые эффективные модели, отличаясь от западного пути.
Google DeepMind представила демо Gemini 3.1 Flash-Lite: модель создает веб-страницы по текстовому запросу почти в реальном времени. Она в 2,5 раза быстрее Gemini 2.5 Flash с генерацией свыше 360 токенов в секунду, но цена вывода выросла до $1,50 за миллион. Подходит для быстрых прототипов интерфейсов, превосходит Claude Opus 4.6 в мультимодальных задачах.
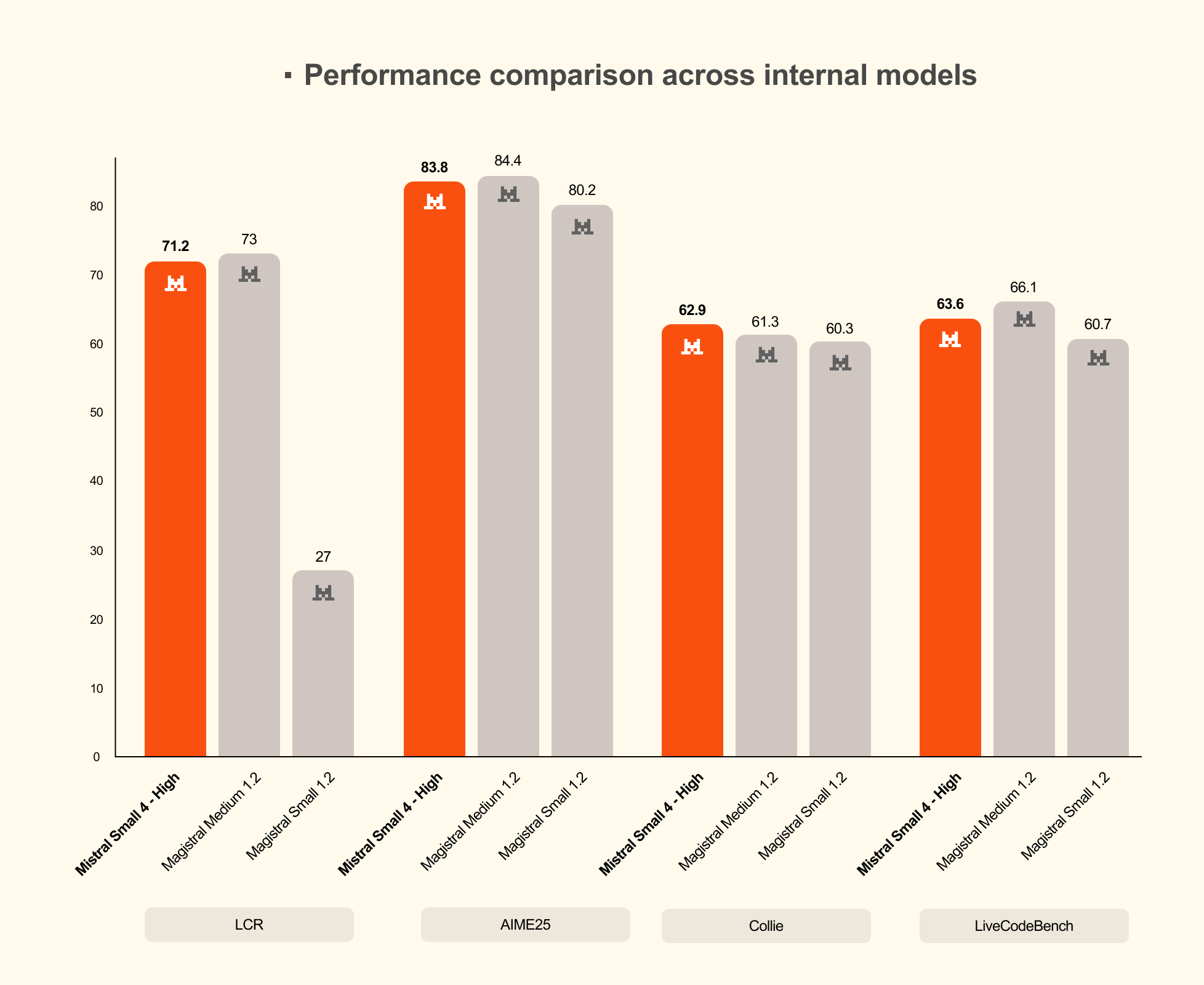
Mistral AI выпустила Small 4 — компактную модель с 119 млрд параметров, где активируется только 6 млрд из 128 экспертных модулей за запрос. Она на 40% быстрее предыдущей версии и втрое производительнее, поддерживая текст, логику и изображения. Новинка доступна под Apache 2.0 на Hugging Face, Mistral API и Nvidia, а компания присоединяется к Nemotron Coalition.
Учёные обучили коллаборативных роботов распознавать эмоции людей с помощью визуальной языковой модели (VLM), которая учитывает мимику и контекст взаимодействия. Эксперименты показали, что VLM превосходит традиционные системы анализа лиц, но персонализированные извинения не восстанавливают утраченное из-за ошибок доверие — люди больше ценят функциональность машины, чем её эмоциональную отзывчивость.
Nvidia выпустила открытую мультимодальную модель Nemotron 3 Nano Omni для текста, изображений, видео и аудио, ориентированную на агентные задачи. Она использует гибрид Mamba-Transformer с MoE и обучающие данные от Qwen, GPT-OSS и других, показывая высокие результаты на бенчмарках вроде OSWorld с точностью 47,4%. Релиз включает веса, данные и пайплайны под коммерческой лицензией.
NotebookLM эволюционировал в мультимодальную студию для креативных архитекторов, охватывающую весь цикл проектов от исследований до презентаций. Ключевые функции включают Deep Research для поиска данных, карты ума для визуализации идей, визуальную студию для слайдов, аудио-видеообзоры и масштабные блокноты на 1 миллион токенов. Это ускоряет процессы и повышает эффективность проектирования систем.
Бенчмарк ProactiveBench показал: из 22 мультимодальных ИИ-моделей почти ни одна не просит помощи при нехватке визуальных данных, предпочитая ошибаться. Дообучение с подкреплением GRPO поднимает точность до 38,6%, но проблема неопределенности остается острой. Исследователи открыли код бенчмарка для дальнейшей работы.
Microsoft AI выпустила три базовые модели ИИ: MAI-Transcribe-1 для транскрипции речи на 25 языках, MAI-Voice-1 для генерации аудио и MAI-Image-2 для видео. Они дешевле аналогов от Google и OpenAI, разработаны командой супер-интеллекта под Мустафу Сулемана. Компания сохраняет партнерство с OpenAI, инвестировав более 13 млрд долларов.
Google сделал Search Live доступным по всему миру для пользователей из более 200 стран. Функция позволяет общаться с поиском голосом и камерой, используя модель Gemini 3.1 Flash Live для естественных бесед. Доступно в AI-режиме приложения Google и через Lens.
Финансовые специалисты автоматизируют сложные процессы с мультимодальным ИИ, где Gemini 3.1 Pro лидирует в обработке документов с таблицами, давая прирост 13-15%. Пайплайны строят на двух моделях и событийном подходе для скорости и масштаба. Важно проверять выводы ИИ в финансовой сфере.
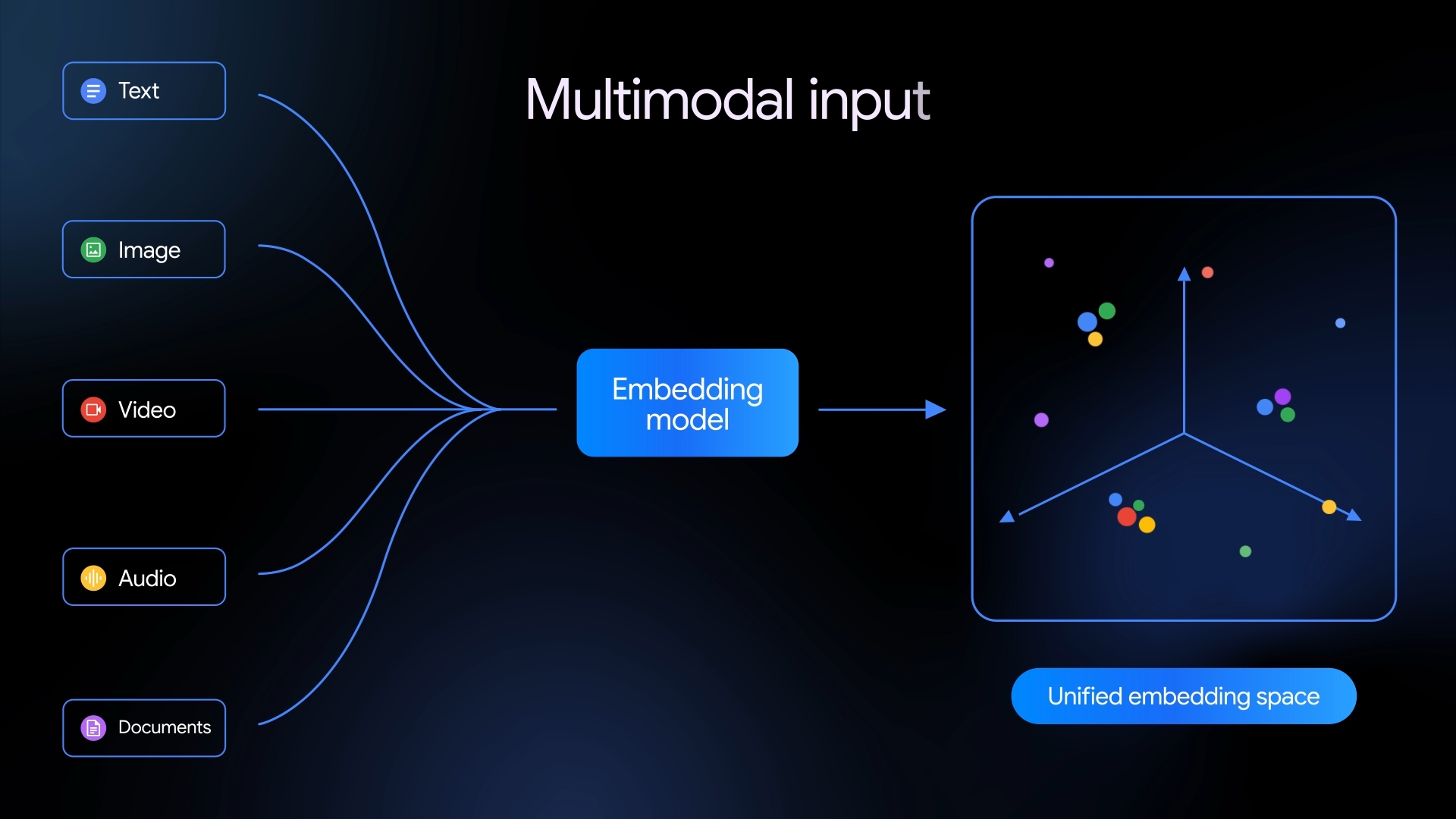
Google анонсировал Gemini Embedding 2 — мультимодальную модель эмбеддингов, которая объединяет текст, изображения, видео, аудио и PDF в единое пространство. Она лидирует в бенчмарках над Amazon Nova 2 и Voyage 3.5, поддерживает смешанные запросы и нативную обработку аудио. Модель доступна в Gemini API и Vertex AI с готовыми интеграциями.