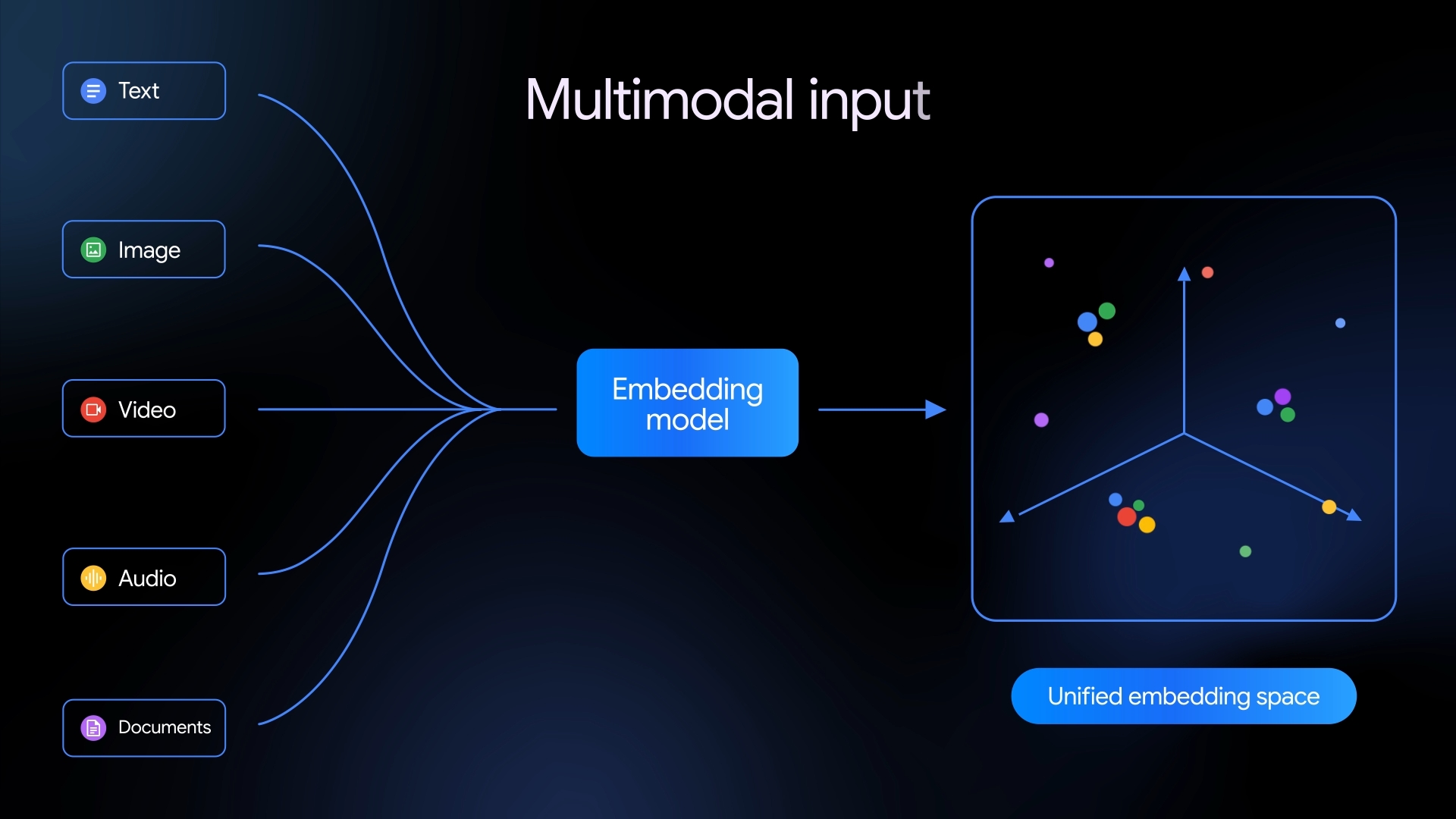
Первая нативно мультимодальная модель эмбеддингов от Google переводит текст, изображения, видео, аудио и документы в общее семантическое пространство, что упрощает сложные ИИ-пайплайны.
В июле 2025 года Google выпустил gemini-embedding-001 — модель эмбеддингов только для текста, которая поддерживает более 100 языков и заняла лидирующую позицию в MTEB Multilingual Leaderboard. С Gemini Embedding 2 компания пошла дальше: новая модель на базе архитектуры Gemini теперь также размещает изображения, видео, аудио и PDF-документы в том же векторном пространстве, что и текст.
Эмбеддинги представляют собой числовые описания данных, которые отражают их смысл. Они лежат в основе таких задач, как семантический поиск, генерация с дополнением из поиска (RAG), анализ тональности и кластеризация данных. Общее векторное пространство позволяет напрямую сравнивать разные типы контента, минуя отдельные модели или дополнительные этапы обработки.
Прямая обработка аудио без промежуточной транскрипции
Google сообщает, что Gemini Embedding 2 принимает до 8192 токенов текста — в четыре раза больше, чем лимит в 2048 токенов у предшественника. За раз можно подать до шести изображений в форматах PNG и JPEG. Видео ограничены 120 секундами, а PDF-документы — шестью страницами.
Особо стоит выделить аудио: модель анализирует его напрямую, без предварительного преобразования в текст. Раньше такие подходы обычно включали этап распознавания речи, на котором терялась часть информации. Gemini Embedding 2 обходит этот шаг.
Есть ещё функция "смешанного ввода": разработчики могут комбинировать разные модальности в одном запросе, например, объединять изображение с текстовым описанием. По словам Google, это помогает модели лучше улавливать связи между типами данных, чем при раздельной обработке.
Как и предыдущая версия, Gemini Embedding 2 применяет Matryoshka Representation Learning (MRL). Этот метод организует данные слоями, чтобы размер выходных векторов можно было уменьшать динамически — словно меньшие представления вложены в большие, как в матрёшке.
Стандартный размер — 3072 измерения, но Google советует 1536 или 768 для баланса качества и затрат на хранение. Модель захватывает семантику более чем на 100 языках.
Тесты подтверждают преимущество по всем модальностям
Google подкрепляет заявления сравнениями с Amazon Nova 2 Multimodal Embeddings, Voyage Multimodal 3.5 и своими прошлыми моделями. Новая версия лидирует во всех проверенных категориях: текст, изображения, видео и разговорный язык.
Разрыв максимален в задачах с текстом и видео: Gemini Embedding 2 набирает до 68,8 баллов, Amazon Nova 2 — 60,3, Voyage Multimodal 3.5 — 55,2. В сравнении текста и изображений Google тоже впереди с 93,4 против 84,0 у Amazon.

Первые партнёры по раннему доступу уже применяют модель в мультимодальных проектах. Эмбеддинги используются в продуктах Google — от инженерии контекста на базе RAG до управления большими данными и традиционного поиска.
Gemini Embedding 2 доступна через Gemini API и Vertex AI. Google подготовил интерактивные ноутбуки в Colab и обеспечил совместимость с фреймворками и векторными базами вроде LangChain, LlamaIndex, Haystack, Weaviate, Qdrant, ChromaDB и Vector Search. Компания запустила простую демку для семантического поиска по разным модальностям, чтобы разработчики могли протестировать возможности.
В конце февраля поисковик на ИИ Perplexity открыл две модели эмбеддингов под лицензией MIT. Это pplx-embed-v1 и pplx-embed-context-v1 — только для текста, но с акцентом на минимальный расход памяти и двунаправленное понимание текста.
На бенчмарке MTEB retrieval самая большая модель Perplexity сравнялась с Qwen3 от Alibaba и обошла gemini-embedding-001 от Google, при этом тратя гораздо меньше памяти.