Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
NASA и Loft Orbital отправили на орбиту модель Google Gemma 3 для анализа изображений без дообучения. Эксперимент показал, что ИИ может обрабатывать снимки прямо на спутнике и передавать текстовые описания вместо тяжёлых файлов — это ускоряет получение важных данных, например, о лесных пожарах. Такой подход меняет способ взаимодействия учёных с космическими аппаратами.
Разбор локального пайплайна видео-саммаризации на базе SmolVLM2-2.2B. Модель запускается на видеокартах с 6 ГБ VRAM, обрабатывает кадры и выдаёт структурированный JSON с описаниями сцен, ключевыми моментами и задачами.
В Индии около 60% диких азиатских слонов обитают за пределами охраняемых зон, что приводит к опасным встречам. Для предотвращения трагедий государственные службы и местные жители внедряют системы искусственного интеллекта, способные оповещать о приближении животных за минуты или секунды.
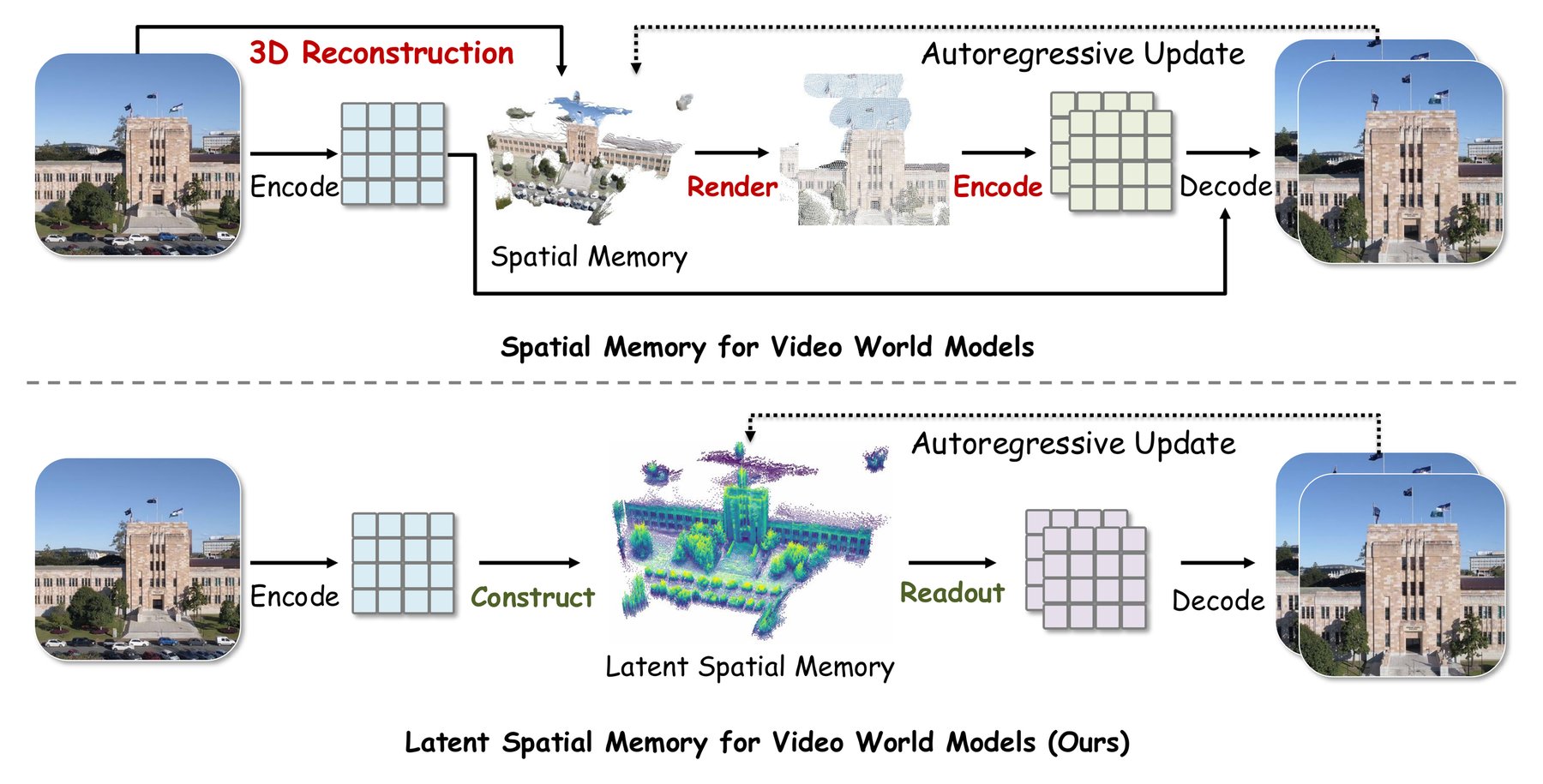
Microsoft Research представила Mirage — модель мира для видео с латентной пространственной памятью. Она обходит попиксельную память, ускоряя генерацию до 10,57 раз и снижая потребление памяти в 55 раз. Mirage сохраняет стабильность сцены при длительных перемещениях камеры, но пока не работает с движущимися объектами.
В заливе Сан-Франциско запущена система WhaleSpotter, которая с помощью ИИ и тепловизоров круглосуточно отслеживает серых китов и предупреждает суда об опасности столкновения. Технология уже снижает риск на 90%, а первые полторы недели работы принесли 6 600 обнаружений. Из-за климатических изменений киты всё чаще заходят в бухту в поисках пищи, что приводит к рекордной смертности от ударов кораблей.
Учёные создали радарную систему с машинным обучением, которая по микродоплеровским сигнатурам взмахов крыльев определяет вид насекомого. На пяти видах опылителей точность составила 85%, а при различении пчёл и ос — 96%. Технология безопасна для насекомых и может помочь в мониторинге опылителей и вредителей.
Архивариусы применяют большие языковые модели для распознавания рукописей в архивах, достигая ошибок ниже 2% против 8% у Transkribus и ускоряя процесс в 50 раз. Исследование Марка Хамфриса на 50 документах 18–19 веков подтверждает превосходство LLM по точности, скорости и стоимости. Archive Pearl и подобные инструменты демократизируют доступ к миллионам оцифрованных страниц.
BioticsAI создала ИИ-копилот для ультразвука, выявляющий аномалии плода, собрала прототип за менее 100 000 долларов и получила одобрение FDA. Компания победила на Startup Battlefield 2023 года и теперь внедряет продукт в больницы. Основатель Робхи Бустами рассказал, как интегрировали регуляторные требования с самого начала и мотивировали команду.
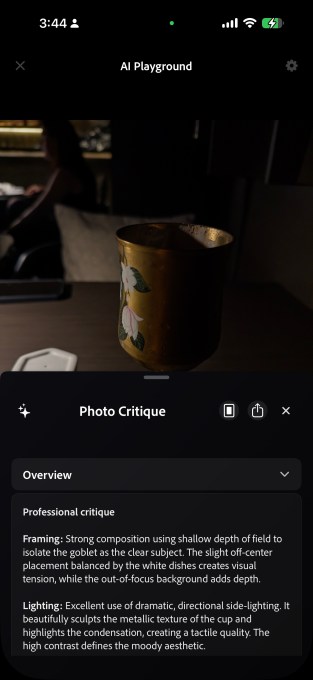
Экспериментальное iOS-приложение Adobe Project Indigo получило ИИ-инструменты: критика снимков по композиции и освещению, удаление ненужных объектов, имитация глубины резкости и перенос стилей. Все функции работают на базе больших языковых моделей и дают осмысленные рекомендации.
Анонимный художник SHL0MS продал NFT настоящего Моне под видом AI-арта, обнажив предвзятость. Тем временем рынок AI-искусства растёт: открылся первый музей генеративного искусства Dataland, а коллекционеры вроде Jediwolf собирают ранние AI-работы. Эксперты считают, что серьёзное AI-искусство — это сложный процесс, а не просто генерация по промту.
Спутник Yam-9 впервые в истории автономно нашел объекты на орбите с помощью ИИ-модели Gemma 3. Технология позволяет выполнять первичную сортировку данных прямо в космосе и открывает путь к постоянному патрулированию.
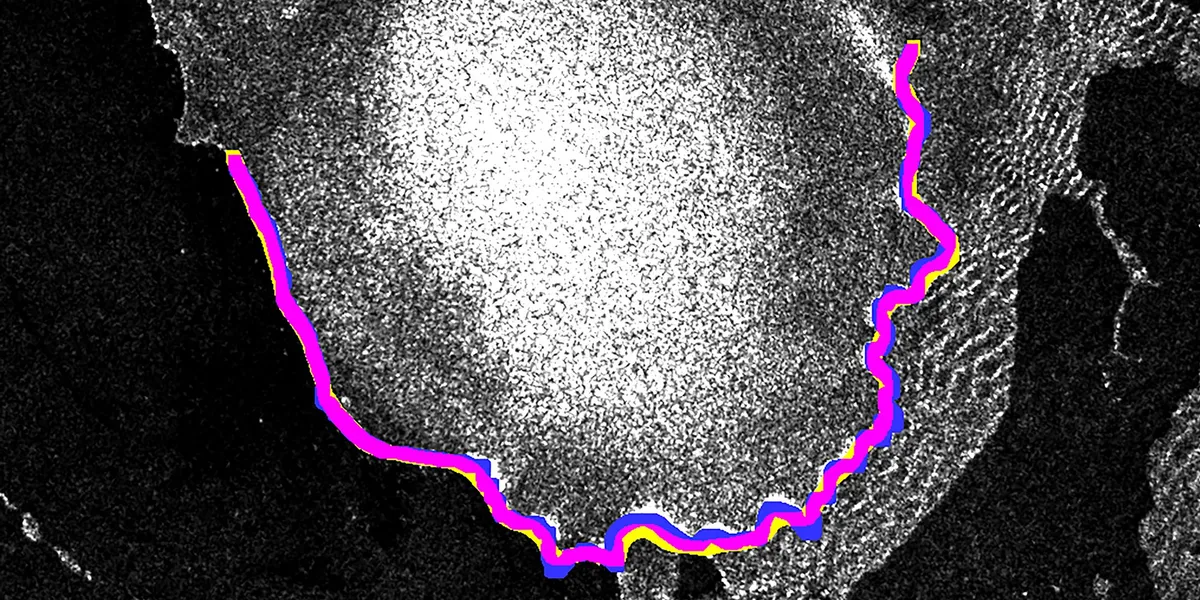
Исследователи из Университета Эрлангена-Нюрнберга разработали метод адаптации моделей глубокого обучения для отслеживания фронтов отёла ледников. Благодаря добавлению всего одного размеченного снимка, летних референсных изображений и карты подстилающих пород погрешность модели сократилась с более километра до 68,7 метров. Метод уже опробован на ледниках Шпицбергена и может быть масштабирован на Арктику, ускоряя климатические исследования.
Учёные обучили коллаборативных роботов распознавать эмоции людей с помощью визуальной языковой модели (VLM), которая учитывает мимику и контекст взаимодействия. Эксперименты показали, что VLM превосходит традиционные системы анализа лиц, но персонализированные извинения не восстанавливают утраченное из-за ошибок доверие — люди больше ценят функциональность машины, чем её эмоциональную отзывчивость.
Новое исследование демонстрирует кольца с ИИ, которые переводят американский и международный жестовые языки в текст с точностью около 88%. Система использует семь колец с акселерометрами, передающих данные по Bluetooth, и может распознавать как отдельные слова, так и предложения.
Planet Labs впервые применила ИИ для распознавания объектов на спутнике Pelican-4, выделив самолёты на аэродроме в Австралии. Технология сократит задержки обработки 30 ТБ ежедневных данных с часов до минут. В планах — сеть Owl для автономного мониторинга и будущие LLM в космосе.
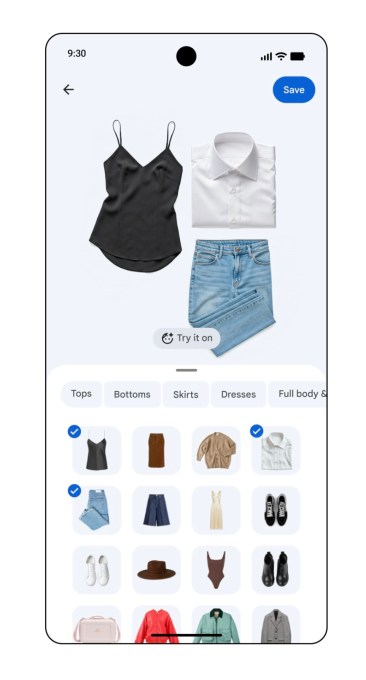
Google Photos анонсировала ИИ-функцию для цифрового гардероба на основе фото одежды из библиотеки. Пользователи смогут фильтровать вещи по категориям, создавать луки, виртуально примерять и сохранять идеи. Запуск на Android летом, на iOS в 'Коллекциях', с конкуренцией от Acloset и других приложений.