Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Amazon предложила GraphEval — метод оценки галлюцинаций больших языковых моделей. Он строит граф знаний из ответа модели и проверяет каждую тройку фактов с помощью NLI-модели. Это позволяет точно локализовать вымышленные утверждения.
В статье предлагается новая метрика — коэффициент Джинна — для оценки того, насколько ИИ-агенты отклоняются от разумного выполнения пользовательских запросов. Из-за недоопределенности языка и целей ИИ склонны к неожиданным действиям, что может приводить к серьезным ошибкам. Разработка бенчмарков на основе этой метрики поможет создавать более безопасных агентов.
Найденный исходный код первой программы-собеседника ELIZA опровергает миф, что она была лишь простым чат-ботом-психотерапевтом. Система могла работать с разными сценариями — от светской беседы до обучения физике и математике — и обладала сложной архитектурой, включая условное сопоставление ключевых слов.
Soofi S — открытая языковая модель с 31,6 млрд параметров, но активирует лишь 3,2 млрд на токен. Она построена на гибридной архитектуре Mamba-Transformer и обучена с упором на немецкий язык. Модель лидирует в бенчмарках среди открытых решений, а также показывает высокую скорость генерации на длинных контекстах.
Эмили Бендер развеивает мифы о метафоре «стохастических попугаев» из своей знаменитой статьи 2021 года. Она поясняет, что метафора относится только к большим языковым моделям, а не ко всему ИИ, и критикует использование термина «искусственный интеллект» как вводящего в заблуждение.
Гильдия авторов протестировала популярные ИИ-детекторы на статьях, написанных до эпохи генеративных нейросетей. Инструменты Pangram и Grammarly безошибочно определили человеческое авторство, а Sidekicker пометил все тексты как сгенерированные. Организация предупреждает, что даже лучшие детекторы не могут быть единственным критерием оценки из-за риска ложных обвинений.
Superhuman (бывшая Grammarly) приобрела стартап GPTZero с 19 миллионами пользователей и годовой выручкой $30 млн. Компания объяснила покупку конкурента тем, что два детектора ИИ-текстов работают эффективнее одного.
Amazon начала бета-тестирование Alexa+ в Индии с поддержкой хинди, приглашая пользователей через закрытую программу. Ассистент на базе генеративного ИИ учится понимать местные нюансы и смешанную речь, чтобы охватить более 600 миллионов носителей языка. Запуск в Индии ожидается, но точные сроки не объявлены.
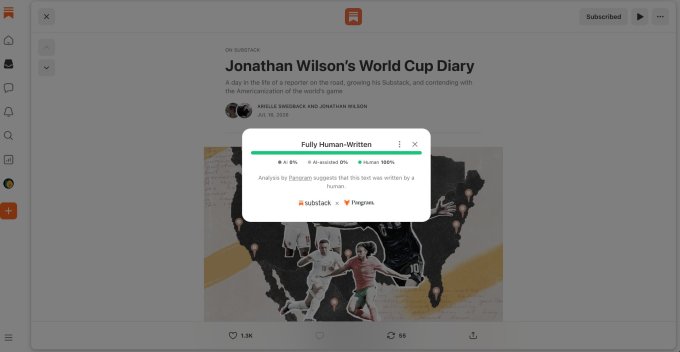
Substack внедрил функцию определения авторства текстов совместно с сервисом Pangram Инструмент анализирует публикации длиннее ста символов показывая процент участия человека Авторы могут добровольно маркировать использование нейросетей.
Исследователи из Принстона и Чикагского университета провели эксперимент с LLM, имитирующий процесс найма. Модели, включая ChatGPT и Claude, быстрее людей начинали сегрегировать кандидатов по этническим группам, формируя стереотипы. Новые модели с расширенными рассуждениями, такие как OpenAI o3, показали еще более сильную предвзятость.
Superhuman запускает обновлённый автодрафт, который генерирует персонализированные черновики ответов на письма, предлагая три варианта. Функция обучается на поведении и уже показывает, что 60% черновиков отправляются без правок. В основе лежат передовые модели от Anthropic и OpenAI.
Вероятность — ключ к пониманию машинного обучения. Разобраны 10 важнейших концепций: случайные величины, распределения, теорема Байеса, энтропия и калибровка, объясняющие, как модели справляются с неопределённостью.
Модель ИИ Conlang Crafter способна генерировать новые искусственные языки строго соблюдая заданные правила Она превосходит обычные большие языковые модели по разнообразию вдвое а по согласованности почти на 70 % Разработчики планируют использовать её для проверки гипотезы Сепира‑Уорфа.
Прем Натараджан, бывший руководитель Alexa AI в Amazon, стал Chief Scientist в Capital One. Он объясняет, почему банки — новая арена для прорывных ИИ-исследований, где решаются сложнейшие задачи масштаба и точности, а внедрение агентного ИИ уже меняет сервис для 100 миллионов клиентов.
Макс Сперо, CEO сервиса Pangram, объяснил, что нейросети создают тексты с повторяющимися аргументами, что выдаёт их искусственное происхождение. Детектор Pangram анализирует структурные паттерны, которые оставляют языковые модели, хотя принцип его работы до конца не ясен даже разработчикам.
В статье разбираются три продвинутые техники NLTK: использование MWETokenizer для сохранения целостности фраз, лемматизация с учётом частей речи и статистическое извлечение коллокаций. Эти методы повышают точность предобработки за счёт сохранения семантической структуры.