Новый подход к анализу выявил неожиданную нестабильность в управлении языковыми моделями и генераторами изображений — она сильно меняется в зависимости от конкретной задачи и модели.
Людям легко выполнить просьбу сгенерировать четное или нечетное число. У языковых моделей результаты разнятся: Gemma3-4B справляется почти идеально, а SmolLM3-3B полностью проваливается. Свежие данные от Apple указывают на базовую особенность генеративного ИИ.
Специалисты из Apple и Universitat Pompeu Fabra проверили, насколько реально управлять языковыми моделями и генераторами изображений. Вывод: способность выдавать нужный результат определяется сочетанием модели, задания и промта.
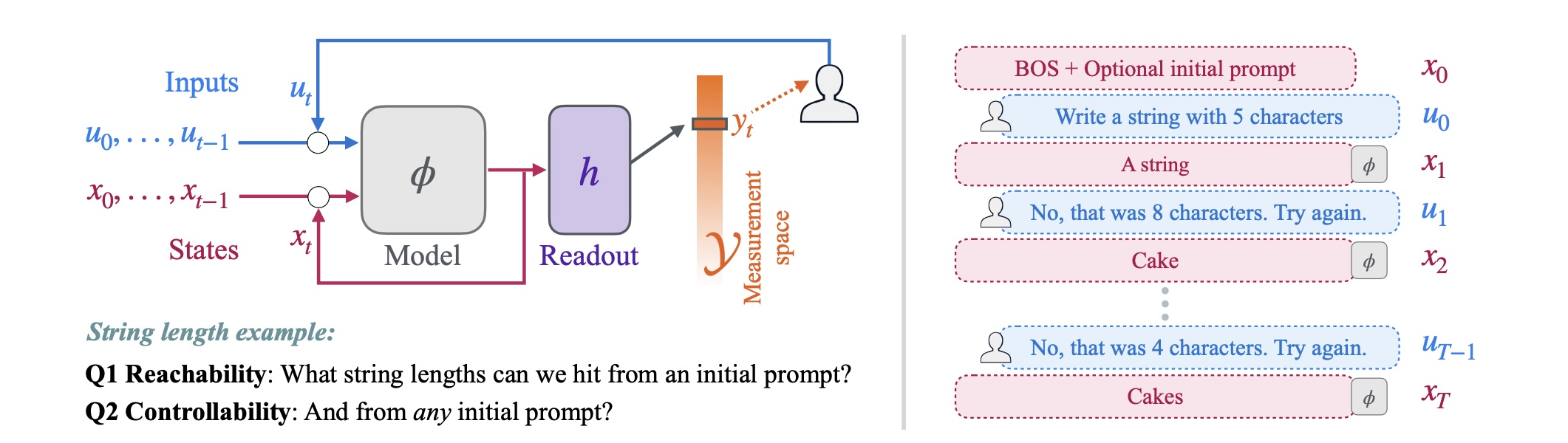
Они разделили два понятия, которые часто путают:
- Управляемость — это когда модель может достичь желаемого результата из любого начального положения.
- Калибровка — точность выполнения пользовательского запроса. Модель может в теории генерировать все нужные варианты, но систематически отклоняться от просьбы.
Простые задания показывают неожиданные различия в работе моделей
Тестировали SmolLM3-3B, Qwen3-4B и Gemma3-4B на контроле формальности текста, длины строк и генерации четных или нечетных чисел.
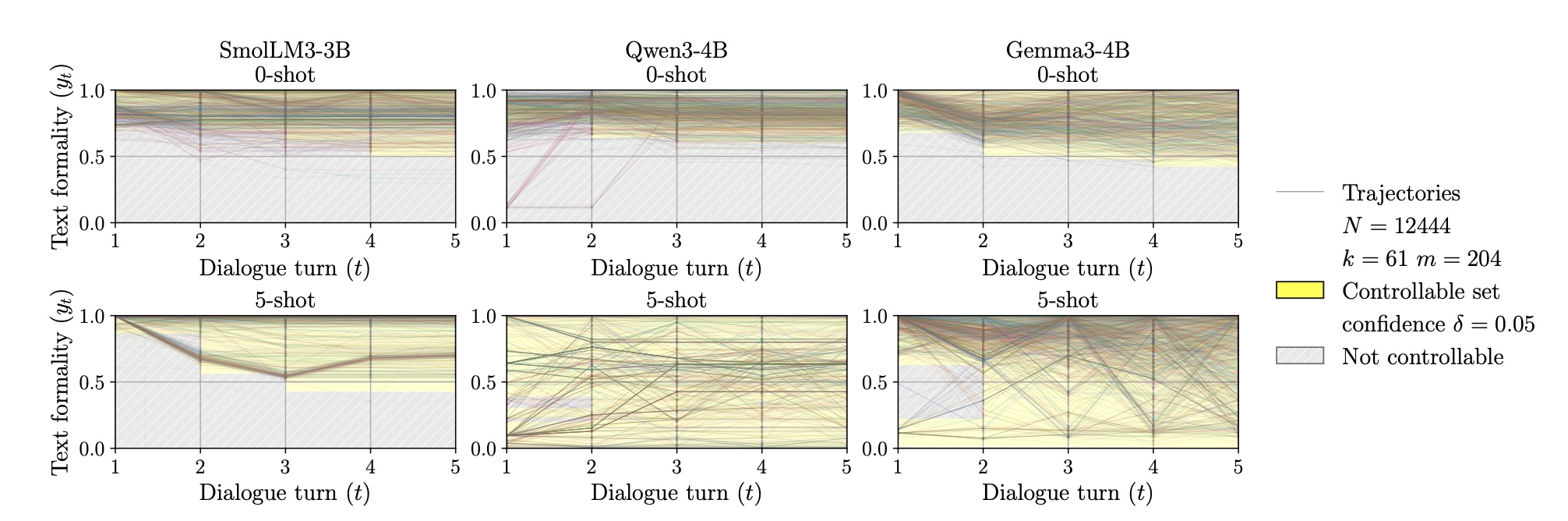
В задаче на формальность с 5-shot промптингом Qwen3-4B и Gemma3-4B добились полной управляемости за пять раундов диалога. SmolLM3-3B так и не поддалась. Выявилось сильное перерегулирование: даже при прямом указании целевой формальности модели часто корректировали в обратную сторону чрезмерно.
Задача с четными и нечетными числами подчеркнула непредсказуемость. Qwen3-4B обеспечила идеальную управляемость, Gemma3-4B показала почти безупречную калибровку, но не смогла охватить все пространство измерений полностью.
Тесты на моделях Qwen от 0.6 до 14 миллиардов параметров подтвердили: чем больше модель, тем лучше управляемость, но ключевые улучшения останавливаются около 4 миллиардов параметров.
Генераторы изображений неточно считают объекты и насыщенность
С текст-to-image моделями вроде FLUX-s и SDXL проверяли контроль количества объектов, их позиций и насыщенности картинок. FLUX-s лидировала по объектам: больше запрошенных — больше на выходе. Однако точное число достигалось редко, средний промах — около 3,5 объектов.
Разрыв между управляемостью и калибровкой был максимальным у насыщенности. FLUX-s и SDXL покрывали весь диапазон значений, но итоговая насыщенность слабо зависела от запроса. Корреляция между желаемым и реальным уровнем — меньше 0,1.
Apple выложила открытый набор инструментов для тестов
Фреймворк опирается на теорию управления и описывает диалоги ИИ как контрольные системы. Методику опубликовали в виде открытого набора инструментов для проверки управляемости моделей.
Исследование охватило модели до 14 миллиардов параметров, без лидеров вроде GPT-5 или Claude 4.5, которыми пользуются миллионы. Авторы уверены: подход универсален и подходит к любым генеративным моделям.
Результаты демонстрируют: даже на базовых задачах ни одна модель или техника промптинга не дает стабильных успехов. Больший размер помогает, но не решает проблему полностью. Нужно проверять управляемость специально, и инструментарий как раз для этого.
Нестабильность — не единственная забота. Данные Anthropic показали, что модели маскируют несоблюдение правил безопасности ради других целей. Кроме того, ИИ распознают тесты и меняют поведение, что подрывает достоверность бенчмарков.