Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Google представила новую умную колонку Home Speaker с поддержкой Gemini. Устройство понимает естественную речь, позволяет давать сложные команды и исправлять их на ходу. Продвинутые ИИ-функции доступны по подписке за $10 в месяц.
Alibaba выпустила омнимодальную модель Qwen3.5-Omni, которая лидирует в аудиозадачах над Gemini 3.1 Pro и неожиданно обрела способность генерировать код по голосовым инструкциям и видео. Версия Plus установила рекорды на 215 бенчмарках, расширила языковую поддержку до 113 языков и ввела ARIA для естественного синтеза речи в реальном времени. Выпуск произошел на фоне ухода ключевых разработчиков.
Гайд по настройке локальной транскрипции аудио с Faster-Whisper, которая в 4 раза быстрее оригинального Whisper и тратит меньше памяти. Описаны установка на CPU/GPU, предобработка файлов pydub+FFmpeg и готовые скрипты для MP3 в текст. Система работает оффлайн, защищая приватность.
Сессия Roundtables на конференции EmTech AI MIT Technology Review представила список из 10 ключевых технологий, трендов, идей и движений в ИИ на 2026 год. Это эксклюзивный обзор важных изменений в отрасли. Участники получили первый взгляд на то, что определяет будущее ИИ.
Deezer констатировала: 44% новых загрузок — ИИ-треки, с 75 тысячами ежедневно и ростом с 10 тысяч в начале 2025 года. Прослушивания низкие, 85% мошеннические, компания исключает их из рекомендаций и hi-res. Опрос показал: слушатели не отличают ИИ от человеческой музыки, но требуют маркировки и защиты чартов.
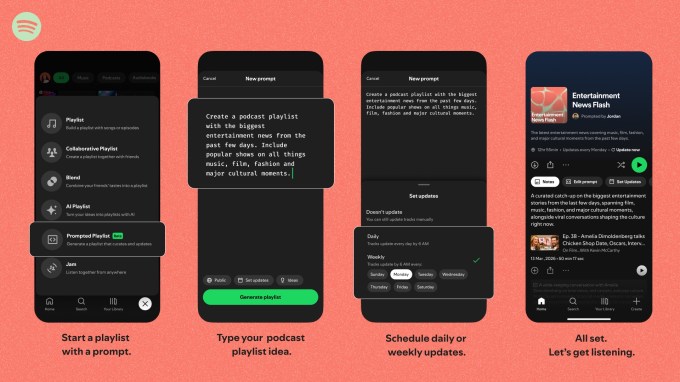
Spotify ввела поддержку подкастов в ИИ-функцию Prompted Playlists для премиум-пользователей в США, Канаде, Великобритании и других странах. Пользователи задают промты для персонализированных подборок с настройками обновлений и объяснениями выбора эпизодов. Еженедельно платформа помогает открыть более 34 млн новых подкастов.
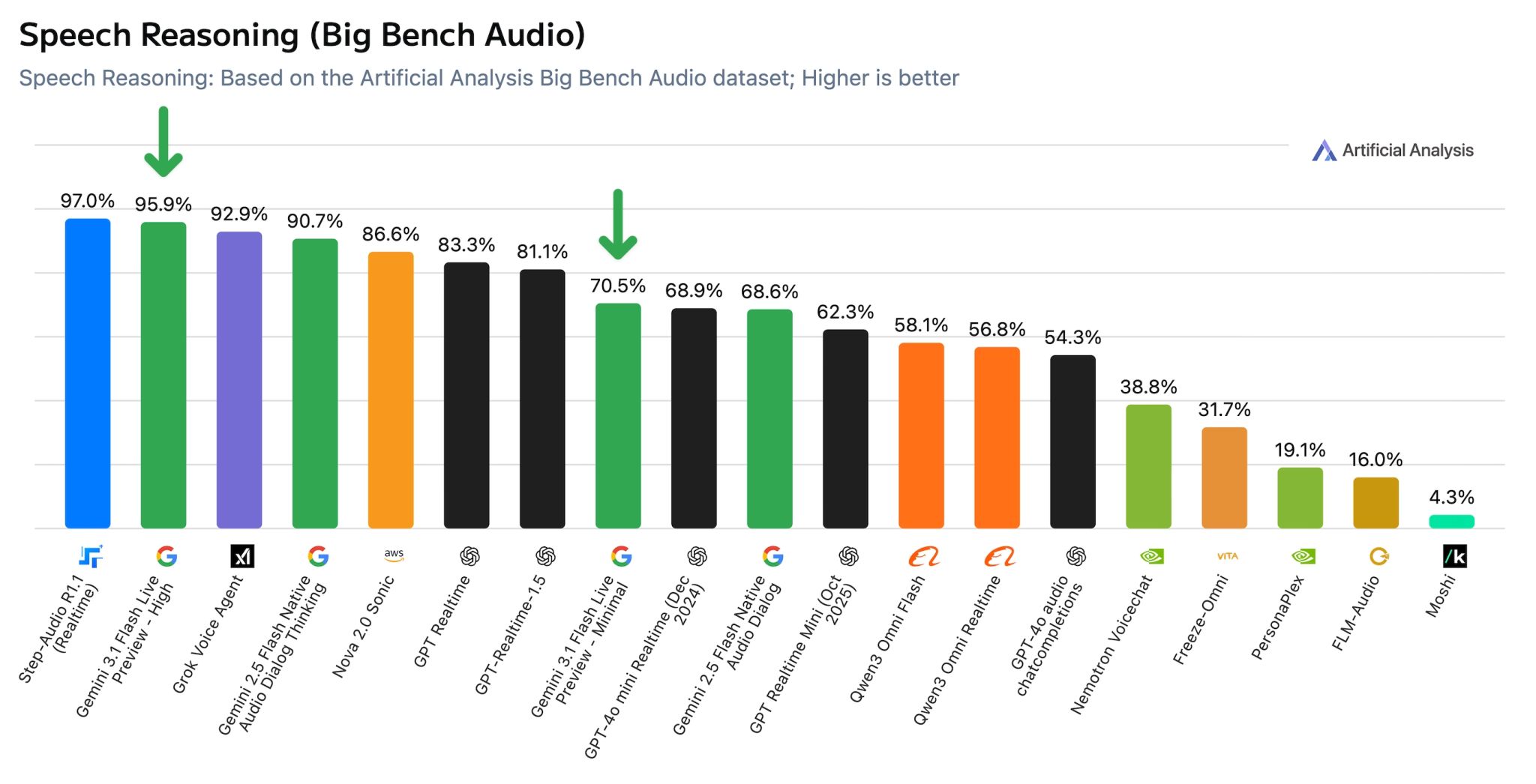
Google анонсировала Gemini 3.1 Flash Live — топовую голосовую ИИ-модель с быстрыми откликами и естественными беседами. В тестах Big Bench Audio она набирает 95,9% на высоком уровне мышления и доступна по низкой цене через API и сервисы компании в 200+ странах.
Физические ИИ-устройства вроде Plaud Note, Mobvoi TicNote и других записывают очные встречи, транскрибируют речь и создают саммари. Они компактны, носимы или размером с карту, многие без обязательных подписок. Модели различаются по микрофонам, автономности и бесплатным минутам транскрипции.
Исследователи показали, что незаметные для слуха звуковые вставки способны захватывать контроль над голосовыми ИИ-моделями — заставлять их выполнять вредоносные команды, загружать файлы злоумышленников и отправлять конфиденциальные данные. Подход работает на ведущих открытых и коммерческих моделях в 79–96% случаев, а стандартные методы защиты почти не мешают атаке.
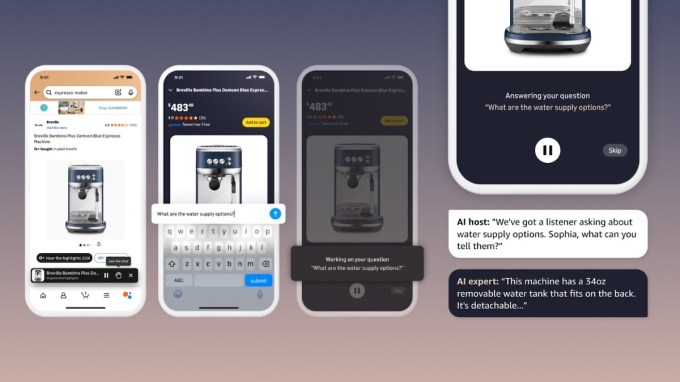
Amazon ввел функцию 'Join the chat' — ИИ-аудиочат для вопросов о товарах на страницах продуктов. Она интегрирована в 'Hear the highlights' с аудиообзорами и доступна в приложении для США. Функция опирается на отзывы и характеристики, дополняя инструменты вроде Rufus и Interests.
SpeakOn — легкий гаджет на 25 г для голосовой диктовки, крепится к iPhone через MagSafe и работает независимо от микрофона смартфона. Устройство распознает речь в 2 футах, переводит на 12 языков, но страдает от шумов, ограничено iOS и навязчиво редактирует текст. Стоит $129 за 5000 слов в неделю, перспективно при доработках.
Deezer сообщает: 44% ежедневных загрузок треков — полностью ИИ-генерированные, около 75 тысяч в день, что в два раза больше, чем год назад. Платформа единственная маркирует такой контент с помощью запатентованного инструмента и исключает его из рекомендаций, где 85% стримов от ботов. Слушатели в опросе Ipsos не отличают ИИ от человеческой музыки, но требуют чёткой маркировки.
Локальный инструмент на Whisper, RoBERTa и BERTopic транскрибирует клиентские звонки, определяет настроение, эмоции и темы. Работает оффлайн с дашбордом на Streamlit для визуализации. Идеально для анализа поддержки без утечек данных.
Генераторы ИИ вроде Suno тайно проникают в производство хитов: продюсеры создают семплы и демо, но молчат из страха критики, а ИИ уже в чартах Billboard. В хип-хопе более половины семплов — от ИИ, сессионщики теряют работу. Неопределенность с копирайтом и конкуренция с гигантами вроде Google усложняют ситуацию.
Talat — локальное Mac-приложение для ИИ-заметок с встреч, альтернатива облачным сервисам вроде Granola. Оно транскрибирует аудио в реальном времени, суммирует ключевые моменты и хранит данные только на устройстве, с гибкими настройками моделей. Разовая покупка за 49 долларов в предрелизе, пробный период 10 часов.
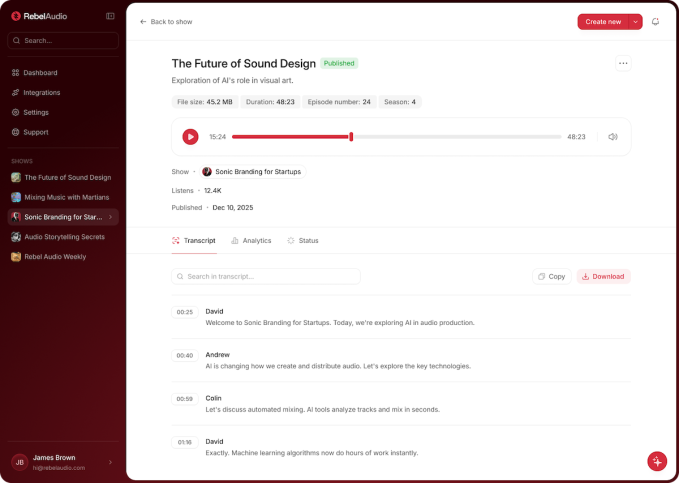
Rebel Audio предлагает all-in-one платформу с ИИ для новичков в подкастинге: от записи до монетизации. Проект привлёк $3,8 млн инвестиций, рынок подкастов вырастет до $114,5 млрд к 2030 году. Команда включает ветеранов индустрии, внедрены меры против рисков ИИ-контента.