Новый бенчмарк ARC-AGI-3 помещает ИИ-системы в интерактивные игровые миры, с которыми люди справляются без усилий. Ни одна передовая модель не преодолевает отметку в 1%, поскольку тест лишает их ключевых сильных сторон.
Фонд ARC Prize Foundation представил ARC-AGI-3 — тест для проверки ИИ в пошаговых игровых средах. В отличие от предыдущих версий, где модели угадывали статические закономерности по примерам вход-выход, здесь агенты сами изучают окружение, строят предположения, определяют цели и реализуют стратегии — полностью без подсказок или описания задачи. Раннюю версию показали летом 2025 года.
Как указано в техническом отчете, все 135 задач люди решили без предварительных знаний и инструкций. А вот frontier-модели показали результаты ниже 1%: Gemini 3.1 Pro Preview — 0,37%, GPT 5.4 — 0,26%, Opus 4.6 — 0,25%, Grok-4.20 — 0,00%.
Важный нюанс: оценки для машин и людей используют разные шкалы.
Квадратичная эффективность карает грубую силу, а не только ошибки
ARC-AGI-3 применяет метрику RHAE (Relative Human Action Efficiency). Она не просто фиксирует успех в задаче, а сравнивает количество действий модели с человеческим. Считаются только шаги, меняющие состояние игры, без учета внутренних вычислений или цепочек рассуждений. Из-за этого результаты ARC-AGI-1/2 и ARC-AGI-3 нельзя сравнивать напрямую.
Человеческий эталон — второй лучший результат среди десяти новичков на каждой задаче. Документация по оценке объясняет: лучший игрок исключают, чтобы убрать выбросы, но сохранить реалистичный ориентир для умелой человеческой игры. Эффективность вычисляют квадратичной формулой: (действия человека / действия ИИ)2. Если человеку нужно 10 шагов, а ИИ — 100, модель получает не 10%, а всего 1%. Такая кара за квадрат наказывает попытки перебрать варианты. Быстрее человека быть нельзя — максимум на уровне 1,0. Более сложные поздние задачи весят больше, поскольку требуют глубокого понимания. Чтобы сэкономить ресурсы, разработчики ограничат попытки агентов пятьюкратным числом человеческих.
Специальные обвязки дают преимущество на знакомых задачах, но не доказывают общий интеллект
Официальный лидерборд проверяет модели через API без специальных обвязок (harnesses), с единым системным промтом для всех.
Фонд в отчете обосновывает выбор: тест оценивает не человеческий ум, вложенный в кастомную систему для задачи, а именно общий интеллект самой модели ИИ. Будущие системы AGI должны справляться с новыми вызовами самостоятельно, без внешней поддержки.
Эксперименты с Duke University выявили четкую картину: Opus 4.6 набрала 97,1% на известной задаче с ручной обвязкой, но провалилась с 0% на незнакомой. Значит, дело не в восприятии игры или формате API. Кастомные подходы просто не переносятся на новые среды. Chollet на X подчеркивает: настоящий AGI не требует подсказок от человека для задач, которые обычные люди решают сами.
Отдельно существует лидерборд сообщества для результатов с обвязками — на основе самоотчетов. Фонд прямо предупреждает: такие цифры не отражают прогресс к AGI. Впрочем, лучшие находки из исследований обвязок со временем интегрируют в модели, подобно тому, как chain-of-thought prompting из внешнего приема стал встроенной фишкой в o1 от OpenAI.
Chollet отвечает на критику на X: низкие баллы — не следствие отсутствия обвязок или простого промта. Буква G в AGI означает "general" — общий. Общий интеллект подразумевает решение любой новой задачи автономно, без специальной подготовки. Если люди справляются без инструментов и инструкций, AGI не должен зависеть от человеческой опеки. По мнению Chollet, всего две позиции: либо AGI реален и пройдет ARC-AGI-3, как люди, либо ИИ навсегда останется инструментом, требующим вмешательства на каждом шагу.
Записи тестов последних моделей доступны на сайте ARC Prize.
Ранние версии ARC заранее выявили ключевые прорывы в ИИ
Предыдущие бенчмарки неоднократно сигнализировали о поворотных моментах в развитии ИИ за последние годы. ARC-AGI-1 первым точно отметил прорыв reasoning-систем вроде o3 от OpenAI, когда другие тесты уже исчерпали потенциал. ARC-AGI-2 отследил взлет современных моделей рассуждений и рост обвязок, которые теперь применяют в продакшен-инструментах вроде Claude Code и Codex. Сегодня оба бенчмарка практически насыщены благодаря таким методам.
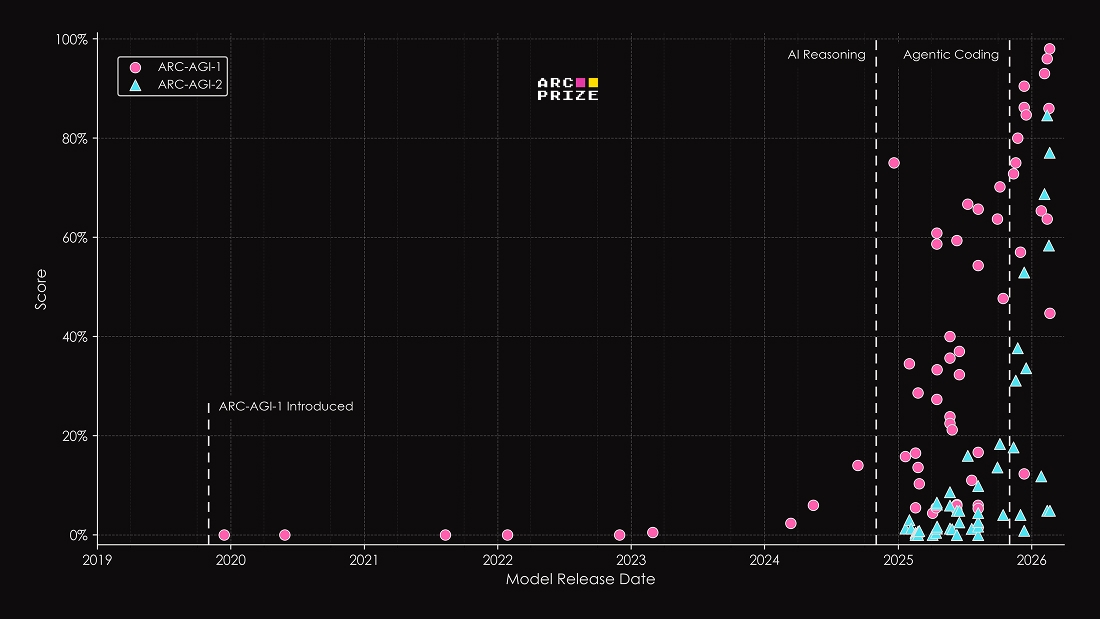
ARC-AGI-3 фокусируется на следующем разрыве: agentic intelligence — умении ориентироваться в совершенно чуждых средах без тренировки. Результаты ниже 1% у всех frontier-моделей, по мнению создателей, демонстрируют, насколько ИИ отстает от человеческой гибкости.
Фонд открыл 25 задач для свободной игры и запустил конкурс ARC Prize 2026 на Kaggle с призовым фондом $2 млн.