Введение
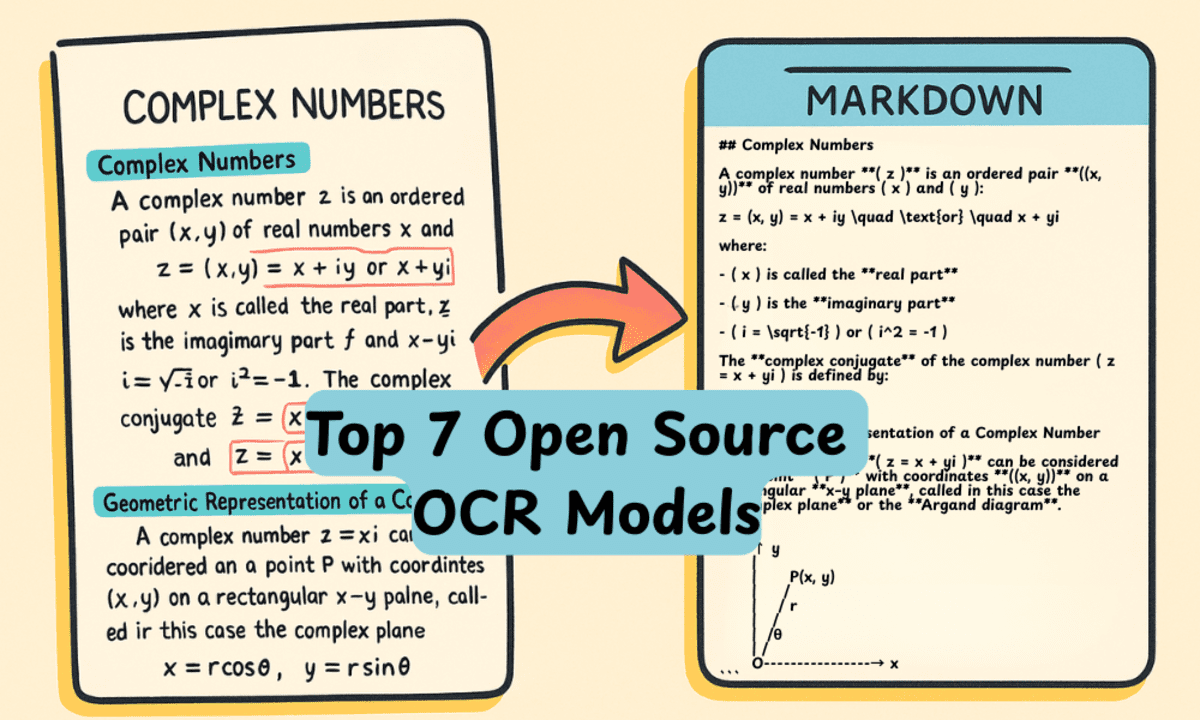
Модели OCR, то есть распознавания символов на изображениях, сейчас пользуются огромным спросом. На платформе Hugging Face то и дело всплывают свежие открытые варианты, которые бьют рекорды по тестам, становясь точнее, умнее и компактнее.
Прошли времена, когда загрузка PDF давала сплошной текст с ошибками. Нынешние ИИ-модели разбирают документы целиком — с таблицами, схемами, разделами и разными языками, — выдавая точный markdown. Получается полноценная цифровая копия документа.
Здесь мы разберём семь лучших OCR-моделей. Их можно запустить на своём компьютере без проблем, чтобы превращать изображения, PDF и фото в идеальные текстовые версии.
1. olmOCR-2-7B-1025

olmOCR-2-7B-1025 — это модель для работы с текстом и изображениями, заточенная под распознавание символов в документах.
Её выпустили в Allen Institute for Artificial Intelligence. Модель дообучили из Qwen2.5-VL-7B-Instruct на датасете olmOCR-mix-1025, а потом улучшили с помощью обучения с подкреплением GRPO.
На тесте olmOCR-bench она набирает 82.4 балла в общем зачёте и отлично справляется с трудными задачами вроде математических формул, таблиц и запутанных макетов документов.
Модель подходит для обработки огромных объёмов данных. Лучше всего она работает с набором инструментов olmOCR, который сам подстраивает рендеринг, повороты и повторные попытки — идеально для миллионов страниц.
Вот пять главных преимуществ:
- Адаптивная обработка с учётом содержимого: сама определяет типы элементов в документе — таблицы, схемы, формулы — и применяет подходящие методы OCR для большей точности.
- Оптимизация через обучение с подкреплением: GRPO помогает лучше распознавать формулы, таблицы и другие сложные случаи.
- Отличные результаты в тестах: 82.4 балла на olmOCR-bench, сильные показатели по arXiv-документам, старым сканам, колонтитулам и много-колоночным макетам.
- Специализация под документы: заточена под изображения с длинной стороной 1288 пикселей, требует особых промтов с метаданными для топ-результатов.
- Поддержка масштабирования: интегрируется с olmOCR toolkit для быстрого вывода через VLLM, способного осилить миллионы документов.
2. PP-OCR v5 Server Det

PaddleOCR VL — сверхкомпактная модель для зрения и языка, созданная для быстрого разбора многоязычных документов.
Основной компонент PaddleOCR-VL-0.9B сочетает визуальный энкодер с динамическим разрешением в стиле NaViT и лёгкую языковую модель ERNIE-4.5-0.3B. Получается топовая точность при минимальном расходе ресурсов.
Поддерживает 109 языков: китайский, английский, японский, арабский, хинди, тайский и другие. Хорошо находит текст, таблицы, формулы, графики в сложных документах.
Тесты на OmniDocBench и внутренних бенчмарках показывают высокую точность и скорость вывода — модель готова к реальным задачам.
Вот пять ключевых особенностей:
- Сверхкомпактная архитектура 0.9B: NaViT-энкодер с динамическим разрешением плюс ERNIE-4.5-0.3B обеспечивают точность без большого расхода ресурсов.
- Лидерство в разборе документов: лучшие результаты на OmniDocBench v1.5 и v1.0 по общему разбору, тексту, формулам, таблицам и порядку чтения.
- Широкая языковая поддержка: 109 языков, включая кириллицу, арабский, деванагари, тайский — для документов со всего мира.
- Полное распознавание элементов: находит текст, таблицы, формулы, графики, даже рукописный текст и исторические материалы.
- Гибкие варианты развёртывания: работает с PaddleOCR, transformers, vLLM — под разные сценарии.
3. OCRFlux 3B
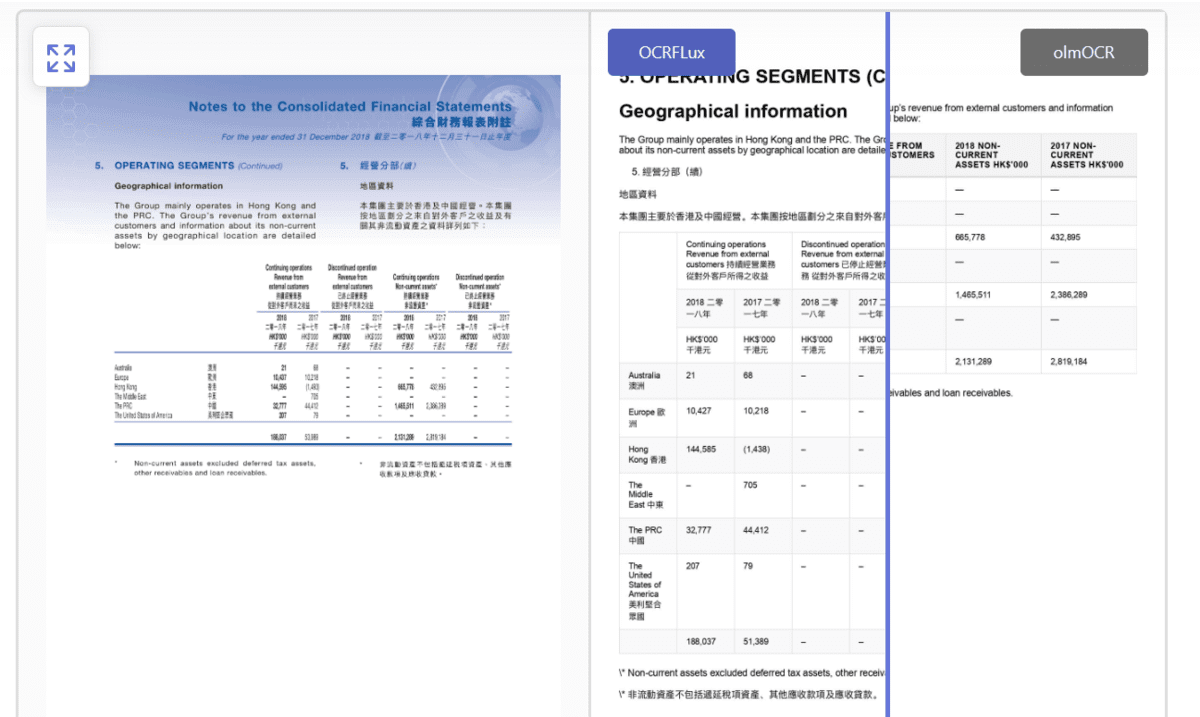
OCRFlux-3B — предварительная версия мультимодальной языковой модели, дообученной из Qwen2.5-VL-3B-Instruct. Она превращает PDF и изображения в чистый markdown-текст.
Обучили на приватных датасетах документов и olmOCR-mix-0225 для высокого качества разбора.
С 3 миллиардами параметров модель идёт на потребительском железе вроде GTX 3090. Поддерживает слияние таблиц и абзацев через страницы.
Лидер по тестам, подходит для масштаба через OCRFlux toolkit с vLLM.
Пять главных фишек:
- Выдающаяся точность на одной странице: Edit Distance Similarity 0.967 на OCRFlux-bench-single, лучше olmOCR-7B-0225-preview, Nanonets-OCR-s и MonkeyOCR.
- Слияние структур через страницы: первая открытая модель с нативной поддержкой таблиц и абзацев через страницы, F1 0.986 на детекции.
- Эффективная архитектура 3B: компактная, работает на GTX 3090, vLLM для миллионов документов.
- Полный набор тестов: OCRFlux-bench-single и кросс-страничные бенчмарки с разметкой для точных измерений.
- Готовый toolkit для продакшена: Docker, Python API, батч-обработка с воркерами, повторами и обработкой ошибок.
4. MiniCPM-V 4.5
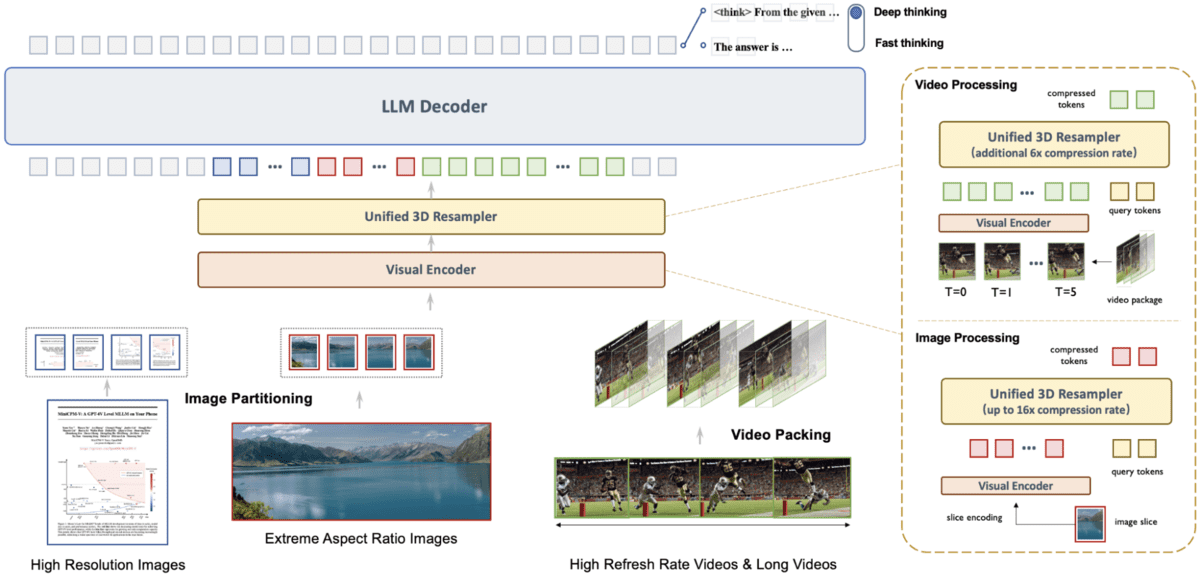
MiniCPM-V 4.5 — новинка в серии MiniCPM-V с продвинутым OCR и мультимодальным пониманием.
Построена на Qwen3-8B и SigLIP2-400M, 8 миллиардов параметров. Разбирает текст в изображениях, документах, видео и наборах фото прямо на мобильных устройствах.
Топовые результаты по тестам при хорошей эффективности для повседневки.
Пять ключевых возможностей:
- Рекордные бенчмарки: средний 77.0 на OpenCompass, обходит GPT-4o-latest и Gemini-2.0 Pro.
- Обработка видео: 3D-Resampler сжимает токены видео в 96 раз, до 10 FPS.
- Гибкие режимы мышления: переключение между быстрым и глубоким разбором.
- Продвинутый OCR: до 1.8 млн пикселей, лидер на OCRBench и OmniDocBench.
- Поддержка платформ: llama.cpp, ollama, 16 квантизаций, SGLang, vLLM, дообучение, WebUI, iOS, онлайн-демо.
5. InternVL 2.5 4B
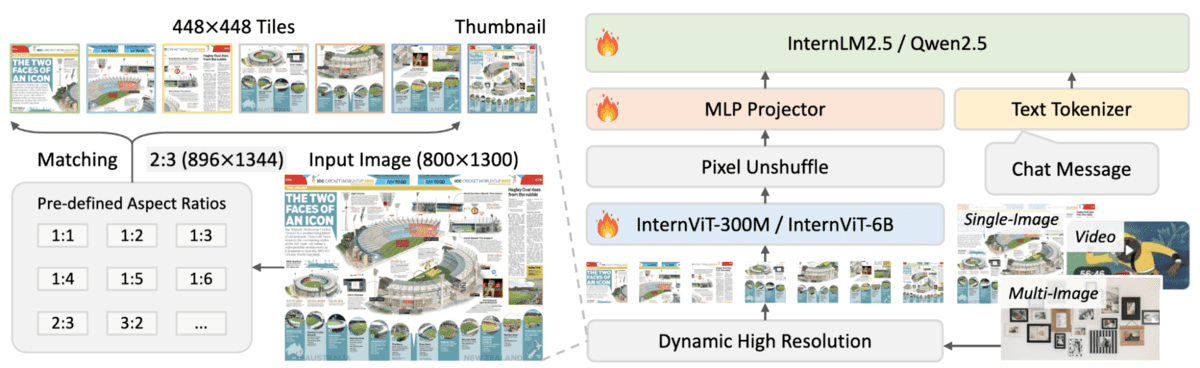
InternVL2.5-4B — компактная мультимодальная модель из серии InternVL 2.5. Визуальный энкодер InternViT на 300 млн параметров плюс языковая Qwen2.5 на 3 млрд.
Всего 4 миллиарда параметров. Заточена под OCR и мультимодальное понимание изображений, документов, видео.
Динамическое разрешение: разбивает на тайлы 448×448 пикселей с сокращением токенов через pixel unshuffle. Подходит для слабого железа.
Пять сильных сторон:
- Динамическая обработка высокого разрешения: тайлы 448×448 для изображений, фото, видео с умным сжатием токенов.
- Трёхэтапное обучение: MLP-разогрев, дообучение энкодера, тюнинг с контролем качества данных.
- Прогрессивное масштабирование: сначала с малыми ЛМ, потом большие, в 10 раз меньше токенов.
- Фильтрация данных: LLM-оценка, детекция повторов, эвристики против деградации.
- Мультимодальные способности: OCR, разбор документов, графики, видео, мульти-изображения при сохранении языковых навыков.
6. Granite Vision 3.3 2B

Granite Vision 3.3 2B — компактная модель для зрения и языка, предназначенная для понимания визуальных документов.
На базе Granite 3.1-2b-instruct и SigLIP2. Открытая, извлекает содержимое из таблиц, графиков, инфографики, диаграмм.
Экспериментальные фичи: сегментация изображений, генерация doctags, поддержка многостраничных документов. Плюс повышенная безопасность.
Пять преимуществ:
- Лучшее понимание документов: рост баллов на ChartQA, DocVQA, TextVQA, OCRBench по сравнению с прошлыми версиями.
- Улучшенная безопасность: выше баллы на RTVLM и VLGuard, лучше с политическим, расовым, jailbreak-контентом.
- Многостраничная поддержка: вопросы по 8 последовательным страницам для длинного контекста.
- Новые фичи обработки: сегментация, doctags для структурированного текста.
- Эффективный дизайн для бизнеса: 2 миллиарда параметров, контекст 128 тысяч токенов для визуальных задач.
7. TrOCR Large Printed

Модель TrOCR большой версии, дообученная на SROIE, — трансформерная система для извлечения текста из изображений с одной строкой.
Архитектура из статьи "TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models". Энкодер-декодер: BEiT для изображений, RoBERTa для текста.
Изображения в патчи 16×16 пикселей, автогенерация текста токенами. Идеальна для печатного текста.
Пять ключевых черт:
- Трансформерная архитектура: энкодер для изображений и декодер для текста в end-to-end OCR.
- Предобученные компоненты: BEiT для энкодера, RoBERTa для декодера.
- Обработка по патчам: 16×16 с линейным встраиванием и позиционными эмбеддингами.
- Авторегенерация текста: последовательная генерация токенов для точного распознавания.
- Специализация на SROIE: дообучение для печатного текста.
Итоги
Таблица сравнивает ведущие открытые модели OCR и зрения-языка: сильные стороны, способности, лучшие сценарии.
| Модель | Параметры | Главное преимущество | Особые возможности | Лучший сценарий |
|---|---|---|---|---|
| olmOCR-2-7B-1025 | 7B | Точный OCR документов | GRPO RL, OCR формул и таблиц, для ~1288px | Масштабные пайплайны документов, научные PDF |
| PP-OCR v5 / PaddleOCR-VL | 1B | Многоязычный разбор (109 языков) | Текст, таблицы, формулы, графики; NaViT-энкодер | Глобальный OCR, лёгкий и быстрый |
| OCRFlux-3B | 3B | Точный разбор в markdown | Слияние таблиц/абзацев через страницы; vLLM | PDF в markdown; на потребительских GPU |
| MiniCPM-V 4.5 | 8B | Топовый мультимодальный OCR | Видео-OCR, 1.8MP изображения, быстрый/глубокий режимы | Мобильный/краевой OCR, видео, мультимодал |
| InternVL 2.5-4B | 4B | Эффективный OCR с рассуждениями | Динамические тайлы 448×448; сильный экстракт текста | Слабое железо; мульти-изображения и видео |
| Granite Vision 3.3 (2B) | 2B | Понимание визуальных документов | Графики, таблицы, диаграммы, сегментация, doctags, QA многостраничных | Извлечение из таблиц, графиков в бизнесе |
| TrOCR Large (Printed) | 0.6B | Чистый OCR печатного текста | Патчи 16×16; BEiT + RoBERTa | Простой точный экстракт печатного текста |