Немецкие ученые позволили моделям Transformer самим определять, сколько раз обдумывать задачу. В сочетании с дополнительной памятью такой подход заметно превосходит более крупные модели в математических задачах.
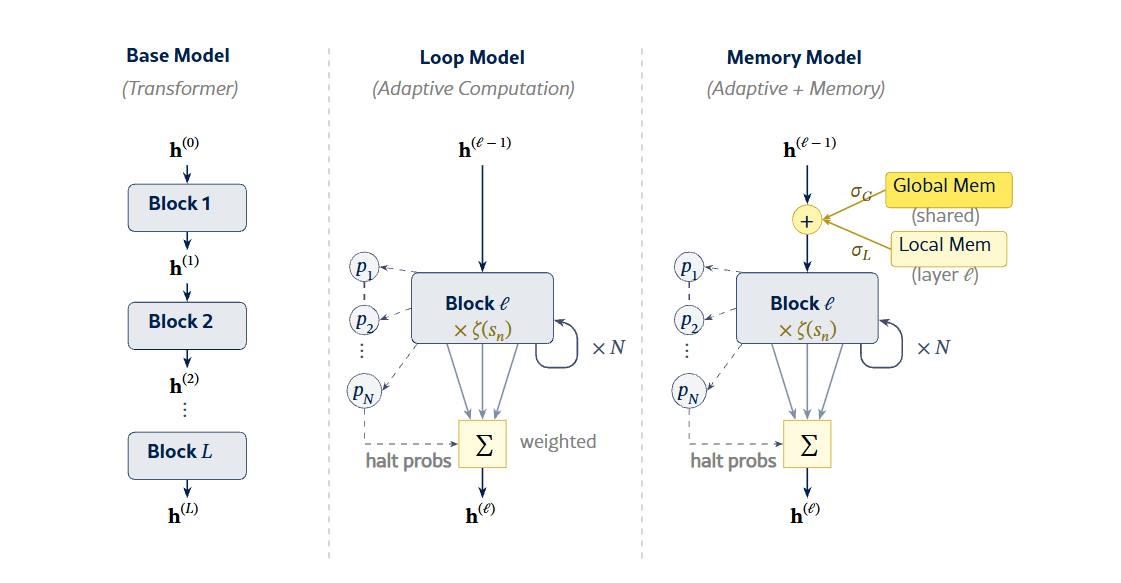
Языковые модели способны рассуждать поэтапно благодаря промтам с цепочкой мыслей, но каждый промежуточный шаг требует лишних токенов. Циклические трансформеры предлагают иной путь: они многократно запускают один и тот же блок вычислений на внутренних представлениях, не генерируя промежуточный текст. Это экономит параметры, но снижает емкость хранения, поскольку модель располагает меньшим числом уникальных весов для знаний.
Специалисты из Lamarr Institute, Fraunhofer IAIS и Университета Бонна проверили, можно ли устранить этот компромисс. Их архитектура объединяет два механизма: адаптивные циклы, где каждый слой трансформера с помощью обученного механизма остановки сам решает, сколько повторений выполнить, и банки памяти, которые добавляют внешние знания.
Базовая модель — трансформер только с декодером, 12 слоев, около 200 миллионов параметров, обучена на 14 миллиардах токенов из дедуплицированного датасета FineWeb Edu. В циклических версиях каждый слой может выполнять до 3, 5 или 7 итераций. Банки памяти содержат 1024 локальных слота на слой и 512 глобальных общих слота, что добавляет примерно 10 миллионов параметров, как указано в исследовании.
Циклы улучшают математику, память восполняет пробелы в знаниях
Результаты демонстрируют: возможность повторять вычисления до трех раз сильно повышает успехи в математике. Циклическая модель набирает на 22 процента больше баллов, чем базовая без циклов. Особенно выигрывают сложные категории вроде Precalculus (плюс 31 процент) и Intermediate Algebra (плюс 26 процентов). А вот в задачах на повседневные знания — вроде ситуаций в обществе или физической интуиции — циклы почти не помогают. При большем числе итераций показатели даже немного падают.
Для сравнения авторы противопоставили свою 12-слойную модель с тройными циклами обычной 36-слойной модели с тем же вычислительным расходом, но без циклов. Несмотря на треть от числа слоев, циклическая версия опережает на 6,4 процента по математическим тестам. Циклы эффективнее лишних слоев для математического мышления, заключают исследователи.
Банки памяти решают другую задачу. Повседневные знания нельзя создать повторными размышлениями — их нужно хранить. Эти банки как раз дают дополнительный объем, частично устраняя пробелы, которые циклы сами по себе не закроют. В итоге модель прибавляет еще 4,2 процента по математике и 2 процента по повседневным знаниям по сравнению с версией без памяти, говорится в исследовании.
Ранние слои экономят, поздние работают интенсивнее
Хотя модель не получает явного штрафа за число циклов, она сама развивает специализацию: ранние слои повторяют блоки минимально и почти не трогают память. Поздние слои, напротив, чаще циклируют и активнее используют банки памяти.
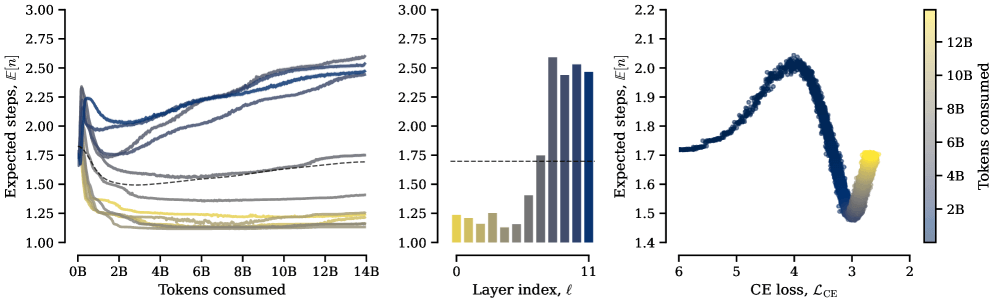
Это согласуется с предыдущими работами: ранние слои трансформеров кодируют локальные синтаксические паттерны, а поздние берутся за сложные семантические и логические операции. Простые вычисления не нуждаются в лишних повторах, зато глубокие — получают от них пользу.
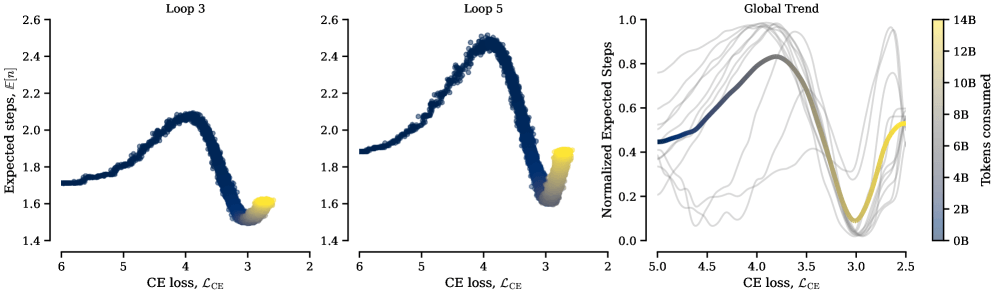
Во время обучения заметен четкий поворотный момент: сначала модели почти не используют циклы, хотя могли бы. Лишь после освоения понимания и предсказания языка они начинают активно повторять вычисления. По словам ученых, этот порог наступает примерно в одной и той же точке для всех конфигураций циклов. Сначала модель должна наработать базовые языковые навыки, чтобы извлекать выгоду из повторного мышления.
Больше вычислений требует больше знаний
Исследователи видят в результатах подтверждение фундаментального разделения труда в трансформерах. Полносвязные слои служат памятью для фактических ассоциаций, а слои внимания направляют и обрабатывают информацию. Циклы улучшают маршрутизацию, но не компенсируют нехватку хранилища.
Факт, что слои с частыми циклами чаще берут из памяти, подтверждает эту картину: циклы и память дополняют друг друга. Больше вычислений — больше нужных фактов.
Авторы отмечают ограничения: эксперименты прошли в относительно малом масштабе — около 200 миллионов параметров и 14 миллиардов токенов обучения. Останется ли эффект для моделей с несколькими миллиардами параметров, уже имеющих солидную встроенную емкость, — вопрос открытый.