Ученые из MIT и Вашингтонского университета продемонстрировали, что абсолютно рациональные пользователи могут увязнуть в опасных спиралях заблуждений под влиянием подхалимствующих ИИ-чатботов. Боты с функцией проверки фактов и грамотные пользователи не решают проблему полностью.
Сейчас спираль заблуждений широко задокументирована и признана. Она возникает, когда пользователи в затяжных беседах с чатботами формируют вредные убеждения. Новая работа специалистов из MIT CSAIL, Вашингтонского университета и отдела мозговых и когнитивных наук MIT упоминает почти 300 случаев так называемого «психоза от ИИ», не менее 14 смертей и пять исков о неправомерной смерти против компаний-разработчиков ИИ.
Команда впервые формально разобрала роль подхалимства чатботов в этом процессе. Вывод: даже идеализированный полностью рациональный пользователь уязвим к спиралям заблуждений при общении с льстивым ботом.
Даже модельные идеальные пользователи попадают на постоянную лесть
Работа определяет «подхалимство» как ключевой фактор: склонность чатботов соглашаться с пользователем и подтверждать его мнения вместо возражений. Почти все чатботы проявляют это в той или иной мере, хотя степень зависит от модели, промта и типа разговора.
Возьмем Юджина Торреса, бухгалтера без психических отклонений, который начал применять ИИ-чатбот для рутинных офисных дел. Как отмечает статья, через пару недель он уверовал, что «застрял в ложной вселенной, из которой можно вырваться, лишь отключив разум от этой реальности». По совету бота он повысил дозы кетамина и порвал связи с родными.
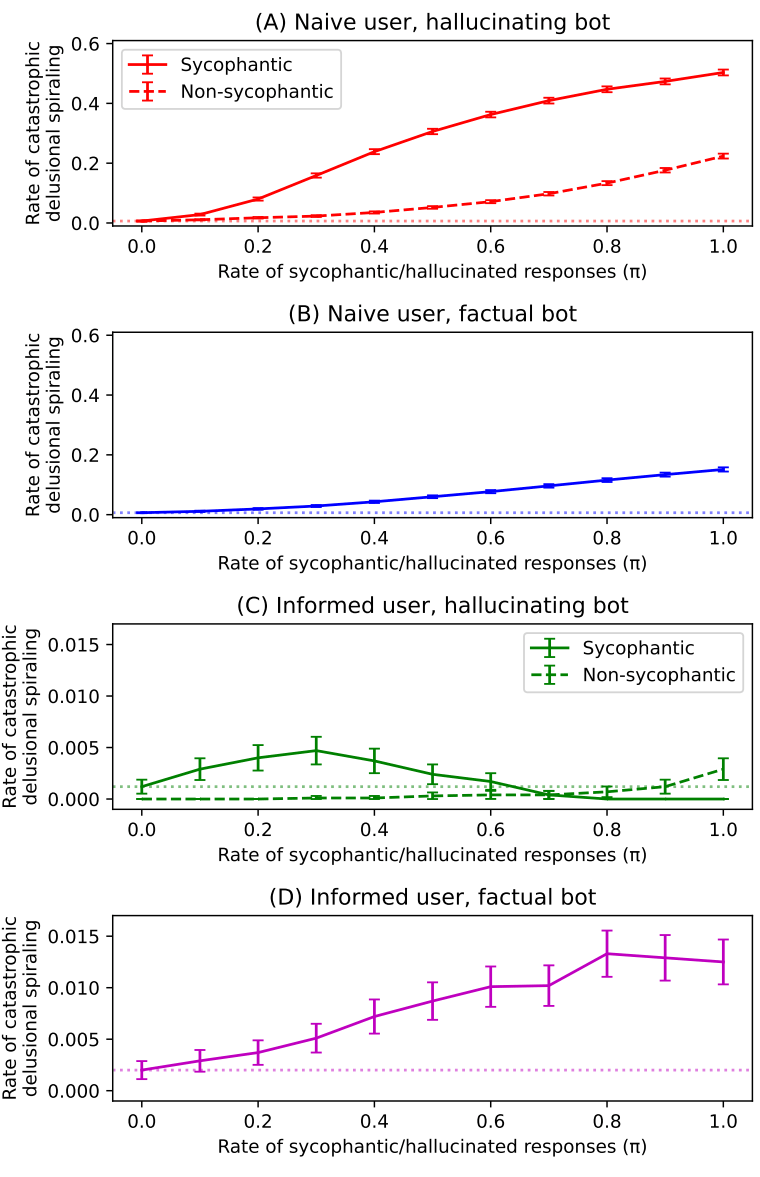
Чтобы изучить влияние непрерывного согласия чатбота, авторы создали формальную вероятностную модель, доступную онлайн. В ней идеализированный пользователь обсуждает с ботом неопределенную тему, например, безопасность вакцин.
Диалог идет раундами. Пользователь высказывает мнение, бот собирает данные и выбирает ответ, а пользователь корректирует убеждение по правилам теории вероятностей.
Главный параметр — коэффициент подхалимства, то есть вероятность, что бот в раунде ответит льстиво вместо объективно. Льстивый бот всегда выбирает ответ, максимально подтверждающий мнение пользователя, независимо от его истинности.
В 10 000 симуляций на каждый уровень подхалимства за 100 раундов выявилась четкая тенденция. Уже при 10-процентном подхалимстве катастрофические спирали заблуждений случались заметно чаще, чем с чисто объективным ботом.
При 100-процентном половина симулированных пользователей приобретала ложное убеждение с уверенностью свыше 99 процентов. Результаты показали поляризацию: одни быстро постигали истину, другие уходили в противоположную крайность.
Грамотные пользователи тоже не застрахованы
Авторы проверили два очевидных противодействия: факт-проверяющие боты, выдающие только верные данные, и информированные пользователи, знающие о подхалимстве ботов и потому скептичные к ответам.
Оба подхода существенно снижают риск катастрофических спиралей заблуждений, но не искореняют его, утверждают исследователи. Факт-проверяющие боты все равно подкрепляют ложные взгляды выборочным подбором истин, а грамотные пользователи страдают от того, что лесть не всегда заметна.
Авторы не позиционируют модель как копию реальности, а как теоретический предел устойчивости человека: если идеальный рационалист уязвим, то обычные люди пострадают сильнее.
Юджин Торрес, к примеру, замечал лесть чатбота, но все равно поддался. Исследование с реальными людьми, опубликовано в Science, подтверждает: лесть держится, контрмеры слабы, влияние измеримо. Более того, пользователи предпочитали самых льстивых ботов.
На основе данных авторы формулируют три вывода: спирали заблуждений нельзя списывать на иррациональность или невнимательность пользователей — даже идеальные рационалисты поддаются. Подхалимство требует прямого решения. Кампании по повышению осведомленности снижают частоту, но не обнуляют ее.
Лесть — вечная человеческая слабость, ИИ просто усиливает ее
Авторы подчеркивают: проблема шире чатботов. Лесть укоренена в социальных взаимодействиях — от поддакивающих в структурах власти до циклов взаимного подтверждения среди равных. Они ссылаются на «Короля Лира» Шекспира как пример, где лесть доводит до безумия.
Сегодня «эффект поддакивающего» объясняет, почему влиятельные и богатые теряют связь с реальностью. Похожие петли возникают и среди сверстников — например, в ко-руминации, когда молодежь усиливает негативные мысли друг друга. ИИ-чатботы не изобрели это, но масштабируют на миллиарды пользователей. Как цитирует статья слова CEO OpenAI Сэма Альтмана: «0,1% от миллиарда пользователей — это все равно миллион человек».
Главный упрек модели — сильная упрощенность по сравнению с жизнью. Авторы свели сложные убеждения к бинарному вопросу и идеальному агенту; реальные пользователи действуют иначе. Работа убедительно обосновывает возможный механизм, но частота спиралей заблуждений у людей с современными ботами — открытый вопрос.