Новейшее поколение больших языковых моделей начиная с GPT-5 по-прежнему испытывает сложности при выполнении заданий, растянутых на несколько реплик беседы.
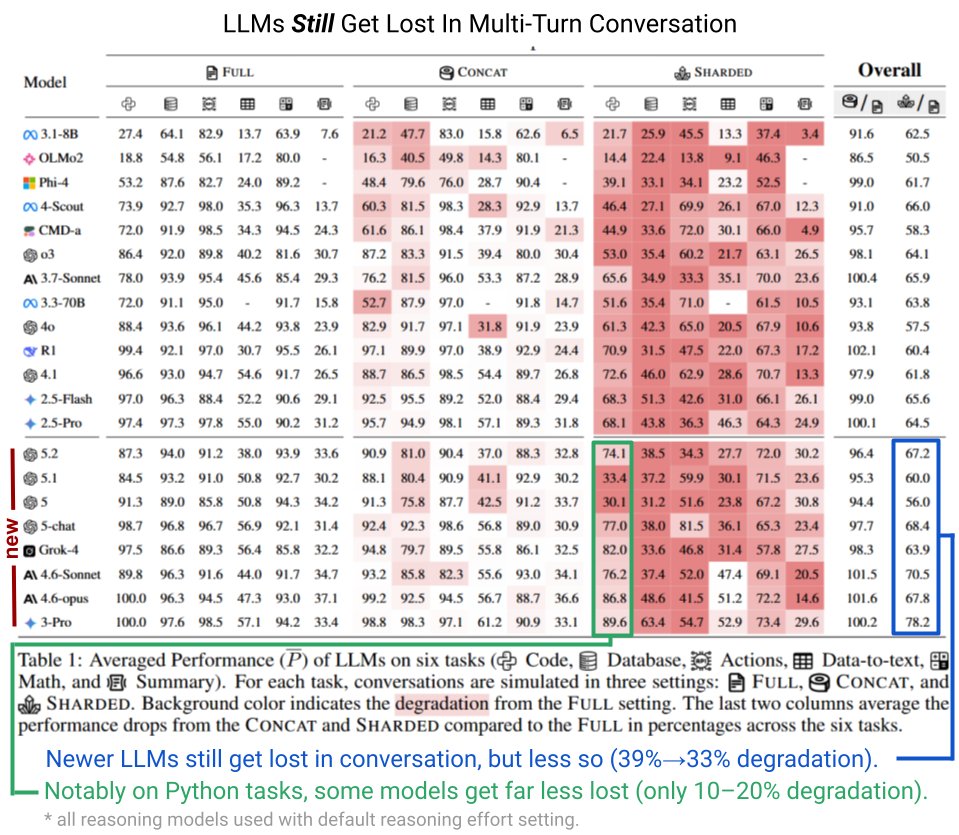
Команда исследователя Philippe Laban оценила возможности текущих моделей на шести задачах, охватывающих код, базы данных и действия. Более современные варианты проявили себя немного лучше — деградация производительности сократилась с 39 до 33 процентов, — но до устранения проблемы ещё далеко. Самые заметные успехи пришлись на задания с Python, где у отдельных моделей потери ограничились 10–20 процентами. Laban полагает, что в реальных условиях спад может быть сильнее: тесты опирались на базовые симуляции пользователей, а те, кто передумывает во время диалога, спровоцируют более крутое падение.
Корректировки вроде снижения температуры не приносят облегчения, подтверждает оригинальное исследование. Авторы советуют перезагружать разговор при проблемах, предварительно поручив модели обобщить все запросы и положить это обобщение в основу новой беседы.