Claude Fable 5 обходит GPT-5.5 на самом сложном тесте FrontierMath
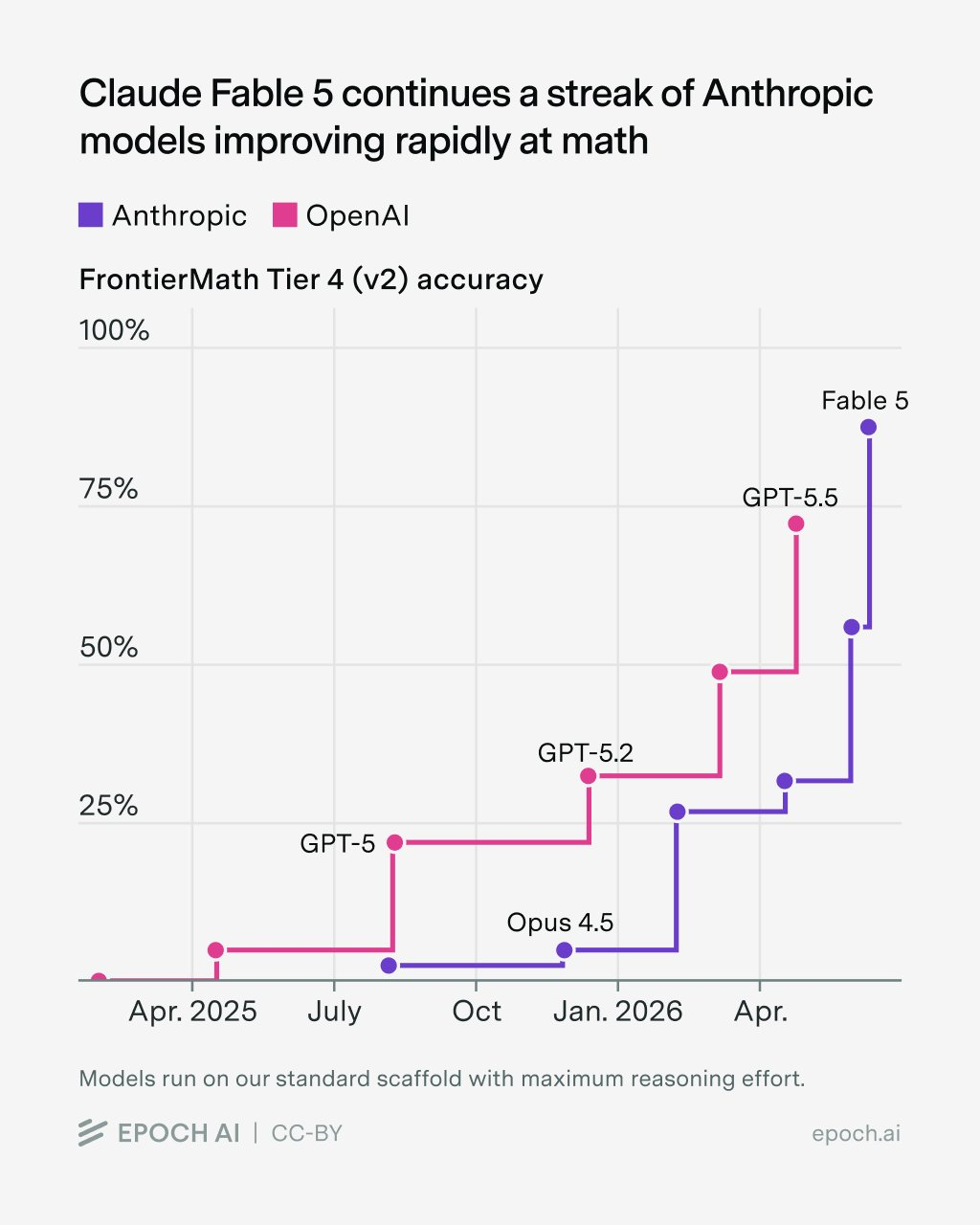
Новая модель Anthropic Claude Fable 5 показала впечатляющие результаты в бенчмарке FrontierMath. По информации Epoch AI, Fable 5 достигла 87% точности на первых трёх уровнях сложности и 88% — на самом трудном четвёртом уровне (v2).

Модели Anthropic стремительно улучшают математические способности. Ещё в начале 2026 года предыдущая версия Opus 4.5 набирала меньше 10% на четвёртом уровне. OpenAI's GPT-5.5 достигает примерно 75% на том же уровне, заметно уступая Fable 5, хотя уже идёт работа над GPT-5.6.
Все модели тестировались на стандартной платформе Epoch AI с максимальными вычислительными усилиями. FrontierMath считается одним из самых сложных тестов для оценки математического мышления ИИ. Эти успехи не ограничиваются бенчмарками — реальные достижения продолжают накапливаться. Недавно модель OpenAI решила давнюю проблему Эрдёша, а Claude Mythos также нашёл решение этой задачи.