Введение
Агентные сессии программирования стоят дорого. Одна сессия Claude Code — чтение файлов, написание кода, запуск тестов, итерации — может сжигать в 10–50 раз больше токенов, чем обычная переписка в чате. В масштабе эти расходы быстро накапливаются. Добавьте к этому лимиты скорости, способные прерывать длительные рабочие процессы прямо посреди сессии, и зависимость от стороннего API, который в любой момент может изменить цены, ужесточить правила или упасть, — и преимущества локального запуска моделей становятся очевидными.
Локальные модели в 2026 году достаточно хороши. Для повседневных задач Claude Code — автодополнение кода, рефакторинг, отладка, объяснение кодовой базы — удачно подобранная квантованная модель, работающая локально, справляется с подавляющим большинством реальных сценариев с нулевой стоимостью за токен и без ограничений скорости. В этом материале рассматриваются три бэкенда для запуска моделей: Ollama, LM Studio и llama.cpp, — точные переменные окружения и конфигурационные файлы для их связки с Claude Code, таблица моделей, которые стоит использовать, и решения реальных проблем, с которыми вы столкнётесь.
Как Claude Code подключается к любой локальной модели
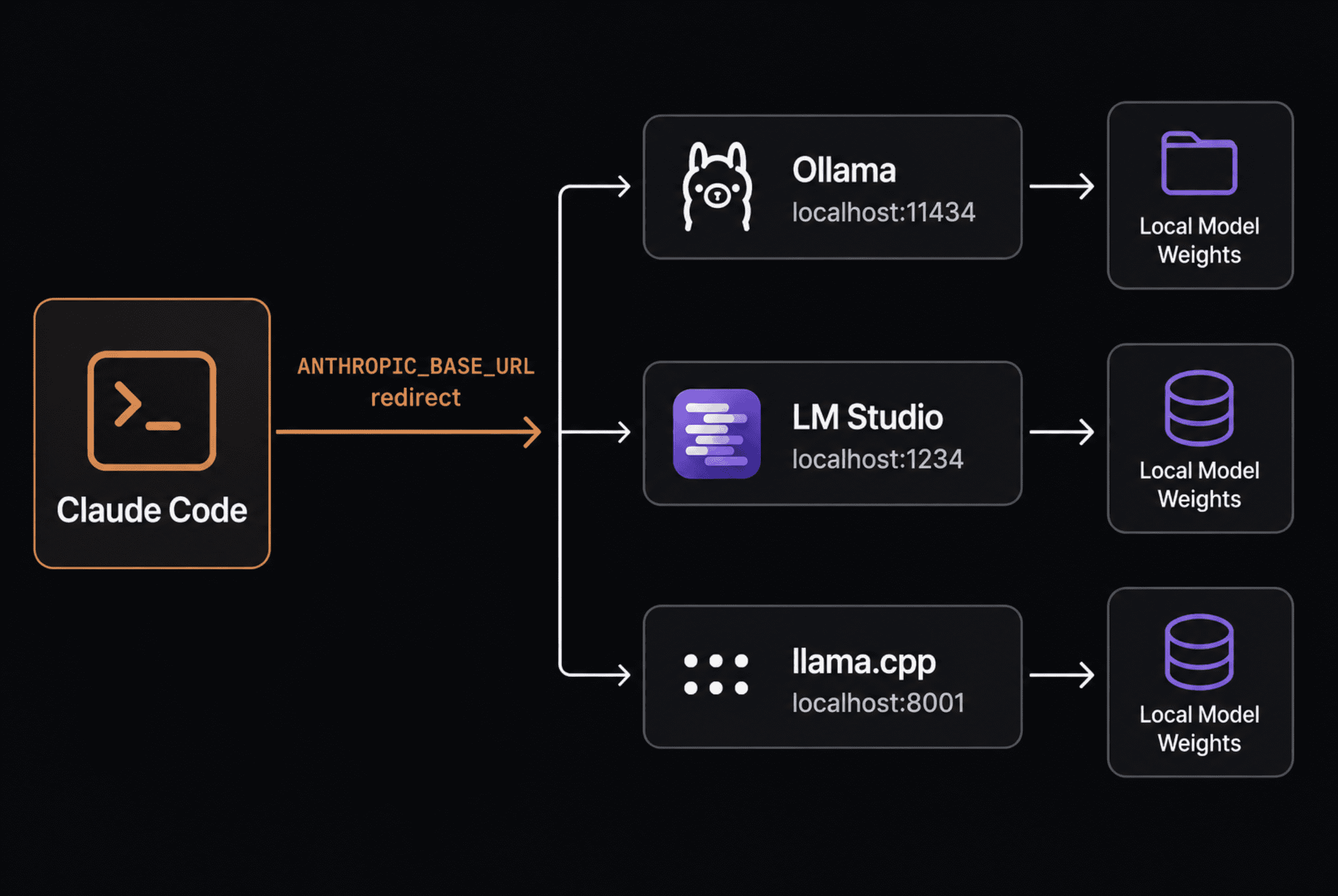
Механизм проще, чем описывается в большинстве руководств. Claude Code отправляет запросы в формате Anthropic Messages API. По умолчанию они уходят на серверы Anthropic. Установка переменной ANTHROPIC_BASE_URL перенаправляет их на любой сервер, говорящий на том же протоколе, а это теперь нативно умеют делать Ollama, LM Studio и llama.cpp.
Согласно официальной документации по переменным окружения Claude Code, для этой настройки важны следующие переменные:
ANTHROPIC_BASE_URL: перенаправляет все вызовы API с серверов Anthropic на указанный URL. Укажите адрес вашего локального сервера.ANTHROPIC_API_KEY: ключ API, передаваемый в заголовке запроса. Локальные серверы обычно игнорируют аутентификацию, поэтому сюда обычно ставят заглушку вроде «local» или «ollama».ANTHROPIC_AUTH_TOKEN: альтернативный заголовок авторизации. Некоторые локальные серверы проверяют его вместо ключа API. Устанавливается такая же заглушка.ANTHROPIC_DEFAULT_SONNET_MODEL,ANTHROPIC_DEFAULT_HAIKU_MODELиANTHROPIC_DEFAULT_OPUS_MODEL: Claude Code внутри себя запрашивает разные уровни моделей в зависимости от задачи. Эти три переменные сопоставляют каждый уровень с именем вашей локальной модели. Без них Claude Code отправляет запросы наclaude-sonnet-4-20250514на ваш локальный сервер, который отклонит запрос, потому что такой модели локально не существует.
В январе 2026 года Ollama добавила нативную поддержку Anthropic Messages API — техническое изменение, сделавшее этот сценарий практичным без прокси-трансляторов. LM Studio добавила эндпоинт /v1/messages в версии 0.4.1. llama.cpp поддерживает прямой Anthropic API ещё дольше. Теперь все три говорят на родном протоколе Claude Code.
Бэкенд 1: Ollama
Ollama — правильная отправная точка. Она берёт на себя всю сложность управления моделями — загрузку весов, квантование, распределение нагрузки между GPU и CPU, обслуживание — за простым интерфейсом командной строки. Одна команда для установки, одна команда для загрузки модели, несколько переменных окружения для настройки. После установки она работает как фоновая служба, так что ручной запуск сервера не требуется.
Требования
- macOS, Linux или Windows (на Windows рекомендуется использовать WSL2)
- Минимум 16 ГБ ОЗУ для практической работы (рекомендуется 32 ГБ)
- GPU с 8+ ГБ VRAM для ускорения на графическом процессоре или CPU-only с достаточным объёмом памяти
- Ollama версии 0.14.0 или новее — обязательна для поддержки Anthropic Messages API
Установка Ollama:
# macOS и Linux — установка одной командой curl -fsSL https://ollama.com/install.sh | sh # Проверка версии — должна быть 0.14.0+ для совместимости с Claude Code ollama version # Ожидаемый вывод: ollama version is 0.14.x или выше # Windows: загрузите установщик с https://ollama.com # Нативная поддержка Windows значительно улучшилась в последних версияхПосле установки Ollama автоматически запускается как фоновая служба на порту 11434. Проверить её работу можно так:
# Проверка, что сервер Ollama работает curl http://localhost:11434 # Ожидаемый ответ: # Ollama is runningЗагрузка модели для программирования:
# GLM-4.7-Flash — рекомендуемая точка входа # Уверенная работа с вызовами инструментов, контекст 128K, помещается на 8 ГБ VRAM # Лицензия Apache 2.0 ollama pull glm-4.7-flash:latest # Qwen3-Coder — качественная кодогенерация и следование инструкциям # Для полной модели требуется 20+ ГБ VRAM ollama pull qwen3-coder # Devstral-Small — спроектирована специально для агентных сценариев программирования # Проверена сообществом на совместимость с Claude Code # 24B, требуется 16+ ГБ VRAM ollama pull devstral-small-2:24b # Проверка, что модель загружена и готова ollama list # Показывает все загруженные модели с размерами и датами измененийНастройка Claude Code для работы с Ollama
Вариант 1: Shell export (только на текущую сессию терминала)
# Перенаправляем Claude Code на локальный сервер Ollama export ANTHROPIC_BASE_URL="http://localhost:11434" # Локальным серверам не нужна реальная аутентификация # Устанавливаем любую непустую строку — Ollama игнорирует значение export ANTHROPIC_API_KEY="ollama" export ANTHROPIC_AUTH_TOKEN="ollama" # Сопоставляем запросы уровней моделей Claude Code с именем вашей локальной модели # Claude Code внутри запрашивает sonnet/haiku/opus — эти переменные # переводят имена уровней в ту модель, которую вы загрузили локально export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest" export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest" export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest" # Запуск Claude Code — теперь он будет использовать Ollama вместо Anthropic API claudeВариант 2: ~/.claude/settings.json (постоянно, действует для всех сессий)
Этот способ переживёт перезапуски терминала и применяется каждый раз при запуске Claude Code. Claude Code считывает переменные окружения из settings.json при старте, поэтому они действуют независимо от способа запуска claude.
Создайте или отредактируйте ~/.claude/settings.json:
{ "env": { "ANTHROPIC_BASE_URL": "http://localhost:11434", "ANTHROPIC_API_KEY": "ollama", "ANTHROPIC_AUTH_TOKEN": "ollama", "ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:latest", "ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:latest", "ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:latest" } }Вариант 3: файл .env в директории проекта (переопределение для конкретного проекта)
Если вы хотите использовать для отдельного проекта другую модель, сохранив глобальные настройки на Anthropic API:
# .env в корне проекта — автоматически загружается Claude Code ANTHROPIC_BASE_URL=http://localhost:11434 ANTHROPIC_API_KEY=ollama ANTHROPIC_AUTH_TOKEN=ollama ANTHROPIC_DEFAULT_SONNET_MODEL=qwen3-coder ANTHROPIC_DEFAULT_HAIKU_MODEL=qwen3-coder ANTHROPIC_DEFAULT_OPUS_MODEL=qwen3-coderПроверка соединения:
# Запускаем Claude Code с простым тестом claude # Внутри Claude Code выполните базовый запрос: # > На какой модели вы работаете? # Локальная модель должна ответить без единого вызова Anthropic API. # Чтобы убедиться, что внешних вызовов нет, запустите с подробным логом: claude --verbose # Ищите строки, где запросы уходят на localhost:11434, # а не на api.anthropic.comПолная рабочая последовательность с нуля:
curl -fsSL https://ollama.com/install.sh | sh # 1. Установка Ollama ollama pull glm-4.7-flash:latest # 2. Загрузка модели (~4 ГБ) export ANTHROPIC_BASE_URL="http://localhost:11434" # 3. Перенаправление Claude Code export ANTHROPIC_API_KEY="ollama" # 4. Установка фиктивной авторизации export ANTHROPIC_AUTH_TOKEN="ollama" export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest" export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest" export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest" claude # 5. ЗапускБэкенд 2: LM Studio
LM Studio — правильный выбор, если вы предпочитаете графический интерфейс для просмотра и управления моделями, а не работу исключительно в терминале. Начиная с версии 0.4.1, она включает нативный эндпоинт /v1/messages, совместимый с Anthropic, — тот самый путь, который ожидает Claude Code, — так что ни слой трансляции, ни прокси не нужны.
Требования:
- macOS, Windows или Linux
- Рекомендуется GPU с 6+ ГБ VRAM (работа на одном CPU возможна, но медленна)
- Загрузите с lmstudio.ai или используйте CLI-установщик для headless-серверов
Установка и настройка LM Studio:
# На сервере или виртуальной машине без GUI — CLI-установщик curl -fsSL https://releases.lmstudio.ai/cli/install.sh | bash # Или загрузите десктопное приложение с https://lmstudio.ai для использования с GUIШаги настройки в графическом интерфейсе:
- Откройте LM Studio и найдите модель для программирования (поищите «qwen coder» или «devstral»).
- Загрузите модель. LM Studio автоматически подбирает вариант квантования.
- Перейдите на вкладку Local Server (иконка
<>на левой боковой панели). - Установите размер контекста. LM Studio рекомендует начинать минимум с 25 000 токенов и увеличивать для лучших результатов.
- Нажмите Start Server.
- Запомните порт (по умолчанию: 1234) и скопируйте имя модели точно так, как оно показано.
Примечание: скопируйте идентификатор модели в точности. LM Studio показывает ровно ту строку, которую нужно передать в
ANTHROPIC_DEFAULT_SONNET_MODEL. Несовпадение здесь — самая частая причина сбоев.
Настройка Claude Code:
# Указываем базовый URL локального сервера LM Studio export ANTHROPIC_BASE_URL="http://localhost:1234" export ANTHROPIC_API_KEY="lm-studio" export ANTHROPIC_AUTH_TOKEN="lm-studio" # Замените имя модели на то, что показывает LM Studio для загруженной модели # Скопируйте его точно — включая суффикс версии или тег квантования export ANTHROPIC_DEFAULT_SONNET_MODEL="qwen2.5-coder-32b-instruct" export ANTHROPIC_DEFAULT_HAIKU_MODEL="qwen2.5-coder-32b-instruct" export ANTHROPIC_DEFAULT_OPUS_MODEL="qwen2.5-coder-32b-instruct"Или постоянно в ~/.claude/settings.json:
{ "env": { "ANTHROPIC_BASE_URL": "http://localhost:1234", "ANTHROPIC_API_KEY": "lm-studio", "ANTHROPIC_AUTH_TOKEN": "lm-studio", "ANTHROPIC_DEFAULT_SONNET_MODEL": "qwen2.5-coder-32b-instruct", "ANTHROPIC_DEFAULT_HAIKU_MODEL": "qwen2.5-coder-32b-instruct", "ANTHROPIC_DEFAULT_OPUS_MODEL": "qwen2.5-coder-32b-instruct" } }Как запустить:
# 1. Запустите сервер LM Studio из GUI (вкладка Local Server > Start Server) # 2. Установите переменные окружения export ANTHROPIC_BASE_URL="http://localhost:1234" export ANTHROPIC_API_KEY="lm-studio" export ANTHROPIC_AUTH_TOKEN="lm-studio" export ANTHROPIC_DEFAULT_SONNET_MODEL="your-model-name-here" export ANTHROPIC_DEFAULT_HAIKU_MODEL="your-model-name-here" export ANTHROPIC_DEFAULT_OPUS_MODEL="your-model-name-here" # 3. Запуск claudeБэкенд 3: llama.cpp
llama.cpp — правильный выбор, когда нужен прямой контроль над параметрами запуска моделей — типом квантования, конфигурацией KV-кэша, размером батча, количеством потоков — или когда вы работаете на сервере и хотите минимальных накладных расходов. Он имеет нативную поддержку Anthropic Messages API, так что прокси или слой трансляции не требуется.
Требования:
- Файл модели в формате GGUF (скачайте с Hugging Face; ищите версии «GGUF» для любой модели)
- GPU с поддержкой CUDA для ускорения на графическом процессоре или только CPU для более медленной работы
- CMake и компилятор C++ для сборки из исходников (на Linux/CUDA рекомендуется собирать из исходников)
Установка llama.cpp:
# macOS — проще всего через Homebrew brew install llama.cpp # Linux с CUDA — сборка из исходников для лучшей производительности на GPU git clone https://github.com/ggml-org/llama.cpp cd llama.cpp cmake -B build -DGGML_CUDA=ON # Включение ускорения CUDA cmake --build build --config Release # Сборка # Бинарные файлы в ./build/bin/ # Linux, сборка только под CPU cmake -B build cmake --build build --config Release # Windows — готовые сборки доступны по адресу: # https://github.com/ggml-org/llama.cpp/releases # Загрузите вариант CUDA или CPU, подходящий вашему оборудованиюЗагрузка модели GGUF:
# Установите Hugging Face CLI, если его нет pip install huggingface-hub # Загрузите GLM-4.7-Flash в квантовании Q4_K_XL (~4.5 ГБ) # Это квантование даёт хороший баланс размера и качества для программирования huggingface-cli download unsloth/GLM-4.7-Flash-GGUF \ GLM-4.7-Flash-UD-Q4_K_XL.gguf \ --local-dir ./models/ # Или загрузите Qwen3-Coder в квантовании Q4 (~15 ГБ для 32B) huggingface-cli download Qwen/Qwen3-Coder-32B-Instruct-GGUF \ qwen3-coder-32b-instruct-q4_k_m.gguf \ --local-dir ./models/Запуск сервера llama.cpp:
# Запуск llama-server с поддержкой Anthropic API и окном контекста 128K llama-server \ --model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \ --alias "glm-4.7-flash" \ # Это имя идёт в ANTHROPIC_DEFAULT_SONNET_MODEL --port 8001 \ --ctx-size 131072 \ # Контекст 128K — важно для больших кодовых баз --flash-attn \ # Эффективное по памяти внимание, ускоряет работу --n-gpu-layers 99 # Выгрузить все слои на GPU; убрать для CPU-only # Для запуска только на CPU (без GPU): llama-server \ --model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \ --alias "glm-4.7-flash" \ --port 8001 \ --ctx-size 32768 \ # Уменьшите контекст на CPU, чтобы не выходить за пределы памяти --threads 8 # Подберите под количество ядер вашего CPUОбъяснение ключевых флагов:
--alias: строка с именем модели, которую Claude Code будет отправлять в запросах. УстановитеANTHROPIC_DEFAULT_SONNET_MODELстрого в соответствии с этим значением.--ctx-size: окно контекста в токенах. 131072 = 128K. Чем больше, тем лучше для анализа кодовых баз, но тем больше VRAM. Уменьшите при ошибках нехватки памяти.--flash-attn: Flash Attention снижает пиковое потребление VRAM, обрабатывая внимание меньшими блоками. Включайте всегда, когда ваша сборка это поддерживает.--n-gpu-layers 99: выгружает все слои трансформера на GPU. Сервер автоматически использует меньше слоёв, если VRAM недостаточно.
Настройка Claude Code:
export ANTHROPIC_BASE_URL="http://localhost:8001" export ANTHROPIC_API_KEY="llama-cpp" export ANTHROPIC_AUTH_TOKEN="llama-cpp" # Должно точно совпадать с --alias, который вы передали llama-server export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash" export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash" export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash"Как запустить:
# Терминал 1: запускаем сервер llama.cpp llama-server \ --model ./models/GLM-4.7-Flash-UD-Q4_K_XL.gguf \ --alias "glm-4.7-flash" \ --port 8001 \ --ctx-size 131072 \ --flash-attn \ --n-gpu-layers 99 # Терминал 2: настраиваем и запускаем Claude Code export ANTHROPIC_BASE_URL="http://localhost:8001" export ANTHROPIC_API_KEY="llama-cpp" export ANTHROPIC_AUTH_TOKEN="llama-cpp" export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash" export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash" export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash" claudeПолный settings.json
Экспорт переменных окружения живёт только до закрытия сессии терминала. Для долговременной конфигурации используйте ~/.claude/settings.json. Claude Code считывает переменные из этого файла при старте, поэтому они действуют независимо от того, как был запущен Claude — из терминала, из задачи VS Code или из скрипта.
Готовый к использованию settings.json с пояснением всех переменных:
{ "env": { "ANTHROPIC_BASE_URL": "http://localhost:11434", "ANTHROPIC_API_KEY": "ollama", "ANTHROPIC_AUTH_TOKEN": "ollama", "ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7-flash:latest", "ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.7-flash:latest", "ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7-flash:latest", "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" } }Почему CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS: "1" имеет значение:
При использовании Claude Code с бэкендами, отличными от Anthropic, Claude Code добавляет в заголовки запросов специфичные для Anthropic экспериментальные бета-флаги — флаги, которые сторонние и локальные серверы не распознают. Это вызывает ошибку Error: Unexpected value(s) for the anthropic-beta header на большинстве локальных серверов. Установка этой переменной в "1" вырезает эти заголовки до отправки запроса, устраняя ошибку без потери какой-либо важной функциональности Claude Code.
Переключение между бэкендами:
Если вы работаете с несколькими бэкендами — Ollama для повседневных задач, Anthropic API для сложных — самый простой подход — держать отдельные shell-скрипты, а не править settings.json туда-сюда:
# use-local.sh — переключение на Ollama export ANTHROPIC_BASE_URL="http://localhost:11434" export ANTHROPIC_API_KEY="ollama" export ANTHROPIC_AUTH_TOKEN="ollama" export ANTHROPIC_DEFAULT_SONNET_MODEL="glm-4.7-flash:latest" export ANTHROPIC_DEFAULT_HAIKU_MODEL="glm-4.7-flash:latest" export ANTHROPIC_DEFAULT_OPUS_MODEL="glm-4.7-flash:latest" echo "Claude Code → локальный Ollama (glm-4.7-flash)"# use-anthropic.sh — переключение обратно на Anthropic API unset ANTHROPIC_BASE_URL unset ANTHROPIC_AUTH_TOKEN unset ANTHROPIC_DEFAULT_SONNET_MODEL unset ANTHROPIC_DEFAULT_HAIKU_MODEL unset ANTHROPIC_DEFAULT_OPUS_MODEL # ANTHROPIC_API_KEY уже должен быть установлен в ваш реальный ключ в вашем rc-файле echo "Claude Code → Anthropic API"Выполните нужный скрипт в текущей сессии:
source ./use-local.sh claude # Когда понадобится реальный API для сложной задачи: source ./use-anthropic.sh claudeЛучшие локальные модели для Claude Code в 2026 году
Оборудование — главное ограничение. Чтобы Claude Code с локальными моделями был действительно применим для программирования, а не только для демонстрации, цельтесь на 32 ГБ ОЗУ — будь то унифицированная память Apple Silicon или обычная оперативная память ПК. 16 ГБ жизнеспособны с небольшими квантованными моделями и выгрузкой на CPU, но скорость генерации будет заметно ниже на многошаговых агентных задачах.
| Модель | Требуется VRAM | Контекст | Сильные стороны | Лицензия | Команда загрузки |
|---|---|---|---|---|---|
| glm-4.7-flash | 8 ГБ | 128K | Вызовы инструментов, быстрая, низкие требования к VRAM | Apache 2.0 | ollama pull glm-4.7-flash |
| devstral-small-2:24b | 16 ГБ | 32K | Агентные сценарии программирования | Apache 2.0 | ollama pull devstral-small-2:24b |
| qwen3-coder | 20 ГБ | 128K | Генерация кода, следование инструкциям | Apache 2.0 | ollama pull qwen3-coder |
| qwen3.5:27b | 20 ГБ | 256K | Сильный универсал, огромный контекст | Apache 2.0 | ollama pull qwen3.5:27b |
| gemma4:26b | 20 ГБ | 256K | Логические рассуждения, 77% в бенчмарке программирования | Gemma License | ollama pull gemma4:26b |
Решение типичных проблем
- Connection refused при запуске Claude Code: сервер вывода не запущен. Это самая частая проблема, которую проще всего диагностировать.
# Проверьте, работает ли Ollama curl http://localhost:11434 # Ожидаемый ответ: "Ollama is running" # Проверьте, работает ли сервер LM Studio curl http://localhost:1234/v1/models # Должен вернуть JSON-список загруженных моделей # Проверьте, работает ли llama-server curl http://localhost:8001/health # Должен вернуть {"status":"ok"} # Если не запущен — сначала запустите сервер, потом Claude Code ollama serve # Ollama # LM Studio: используйте вкладку Local Server в GUI # llama.cpp: выполните команду llama-server из раздела Бэкенд 3 - Ошибка «модель не найдена» или «неизвестная модель»: имя модели в
ANTHROPIC_DEFAULT_SONNET_MODELне совпадает с тем, что знает сервер.# Выведите список всех доступных Ollama моделей ollama list # Имя модели в ANTHROPIC_DEFAULT_SONNET_MODEL должно совпадать ТОЧНО, # включая тег — "glm-4.7-flash:latest", а не "glm-4.7-flash" # Проверьте прямым запросом к API, чтобы подтвердить, что видит сервер curl http://localhost:11434/v1/models - Сбои вызовов инструментов или ошибки при их выполнении: для потоковых вызовов инструментов, которые Claude Code использует при выполнении функций или скриптов, требуется Ollama версии 0.14.3-rc1 или новее. В более ранних версиях серии 0.14.x поддержка потоковых вызовов инструментов была неполной.
# Проверьте версию Ollama ollama version # Если ниже 0.14.3, обновите Ollama curl -fsSL https://ollama.com/install.sh | sh - Ошибка заголовка
anthropic-beta: вы увидите:Error: Unexpected value(s) for the anthropic-beta header. Это происходит, потому что Claude Code добавляет специфичные для Anthropic экспериментальные бета-флаги, которые локальные серверы не распознают. Исправляется добавлением в блокenvвашегоsettings.json:"CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" - Возврат к Anthropic API:
# Сессия терминала — сброс переменных перенаправления unset ANTHROPIC_BASE_URL unset ANTHROPIC_AUTH_TOKEN unset ANTHROPIC_DEFAULT_SONNET_MODEL unset ANTHROPIC_DEFAULT_HAIKU_MODEL unset ANTHROPIC_DEFAULT_OPUS_MODEL # Затем убедитесь, что ваш реальный API-ключ установлен echo $ANTHROPIC_API_KEY # Должен показать ваш ключ sk-ant-..., а не заглушку # Если вы использовали settings.json — удалите или закомментируйте блок env # и перезапустите Claude Code - Медленная скорость генерации: для агентных задач Claude Code скорость генерации критична, потому что каждый вызов инструмента — это полный цикл запроса-ответа. Если скорость недостаточна:
- Переключитесь на меньшую или более агрессивно квантованную модель (Q4_K_M вместо Q8).
- Включите
--flash-attnв llama.cpp, если ещё не включили. - Уменьшите размер контекста (
--ctx-size); большие контексты медленнее обрабатываются при префиллинге. - В Ollama установите
OLLAMA_NUM_GPU_LAYERS=99в переменных окружения для принудительной максимальной выгрузки на GPU.
Заключение
То, что раньше требовало хрупких адаптеров и хаков, теперь стало процессом из пяти шагов. Установите бэкенд для запуска моделей, загрузите модель, задайте три переменные окружения, и Claude Code будет маршрутизировать запросы на ваш локальный компьютер вместо API Anthropic. Настройка занимает меньше пяти минут, как только модель загружена.
Практический результат — ассистент для программирования, который ничего не стоит после первоначальной настройки, не имеет ограничений скорости, сохраняет весь код на вашем компьютере и справляется с подавляющим большинством реальных задач на уровне качества, недостижимом для локальных моделей год назад. Начните с Ollama и glm-4.7-flash — у неё самые низкие требования к оборудованию, самая стабильная поддержка вызовов инструментов и самый быстрый путь к работающей конфигурации. Когда всё заработает, масштабируйте модель вверх, исходя из вашего оборудования и реальной потребности в качестве.