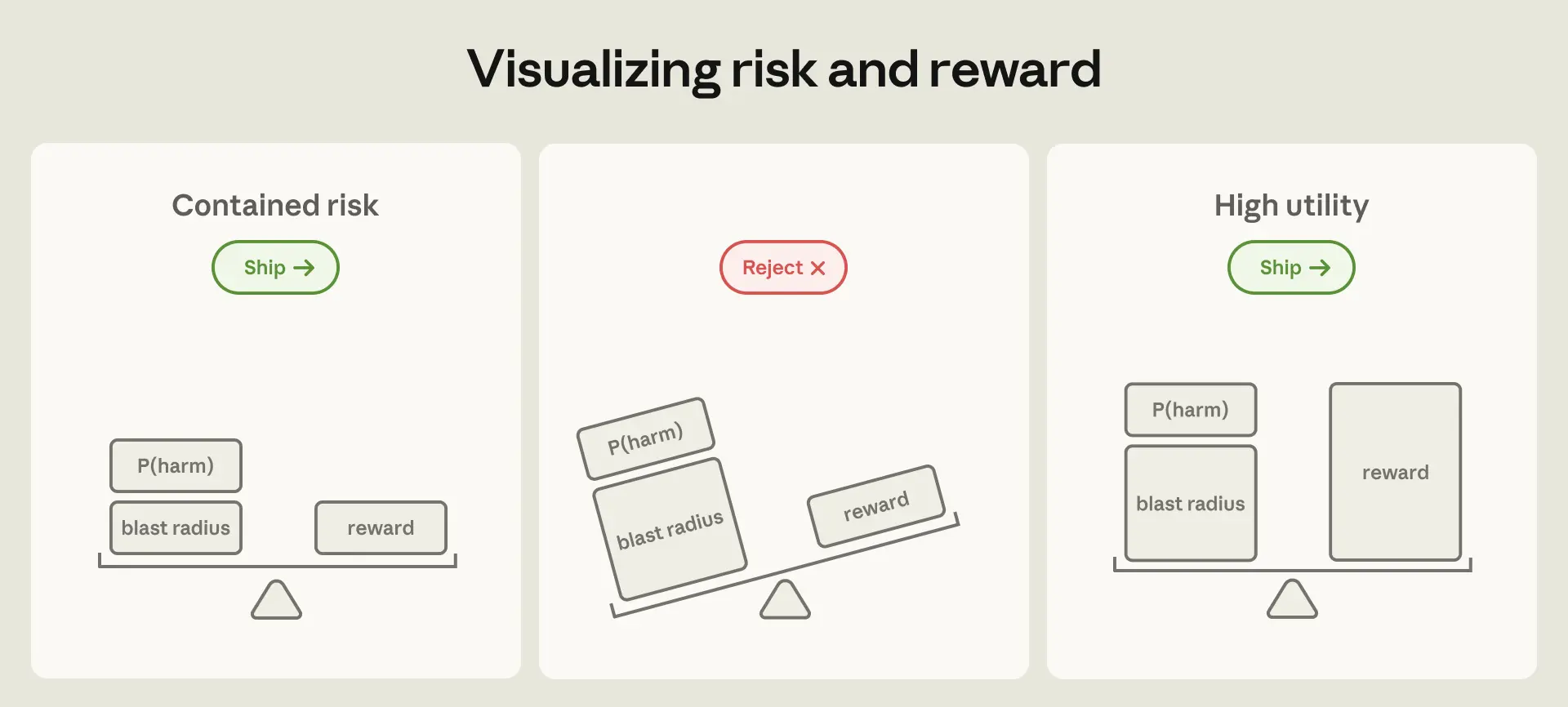
Год назад мы бы наотрез отвергли идею дать Claude доступ, достаточный для выведения из строя внутреннего сервиса Anthropic. Сегодня такой уровень доступа стал обычным делом, и разработчики Anthropic благодаря этому продуктивнее. Риск подобных развёртываний складывается из двух составляющих: вероятности отказа и масштаба потенциального ущерба. Развитие защитных механизмов и обучение моделей постепенно снижают первую; вторая — теоретический радиус поражения — только растёт по мере расширения возможностей и доступа. Но когда агенты начинают выполнять работу, прежде требовавшую целой команды, цена отказа от их внедрения становится настолько высокой, что соотношение риска и выгоды решительно склоняется к использованию, если продукты удаётся сделать безопасными. Инженерная задача сводится к тому, как ограничить радиус поражения.
Существует два основных способа ограничить радиус поражения.
Первый — контролировать поведение агента, оставляя человека в цикле принятия решений. Раньше Claude Code защищался от непреднамеренных действий, запрашивая разрешение пользователя на каждом шагу. Теоретически это работает, но на практике подход оказался ненадёжным. Согласно нашей телеметрии, пользователи одобряли около 93% запросов на разрешение. Чем больше подтверждений видит человек, тем меньше внимания уделяет каждому, и со временем его бдительность существенно падает. Недавно мы внедрили автоматический режим Claude Code, который автоматизирует безопасные разрешения, чтобы снизить усталость от одобрений (этот режим делегирует подтверждения классификатору на основе модели; он минимизирует трение — блокируется лишь 0,4% безвредных команд, — но пропускает около 17% излишне рискованных действий, поэтому служит лишь одним из слоёв эшелонированной защиты внутри песочницы, а не её заменой). Тем не менее уязвимости остаются — любая вероятностная защита имеет ненулевой процент ошибок.
Второй подход к ограничению радиуса поражения — и основная тема этого материала — изоляция. Вместо надзора за тем, что агент делает, мы контролируем, что он вообще способен сделать, устанавливая границы доступа с помощью песочниц, виртуальных машин и контроля исходящего трафика. Именно сюда инженеры Anthropic вложили больше всего усилий, и именно здесь произошли самые неожиданные инциденты безопасности.
За последние два года мы выпустили три основных агентных продукта: claude.ai, Claude Code и Claude Cowork. Каждый обслуживает разную аудиторию и требует собственной архитектуры изоляции. В этой статье мы расскажем, что выдержало проверку, что сломалось и какие уроки мы извлекли в области безопасности агентов.
Три типа рисков, три компонента защиты
Риски безопасности агентов делятся на три категории:
Злоупотребление пользователя: пользователь — намеренно или по неосторожности — даёт агенту вредоносную команду. Сюда входит и просьба обойти надоевшую проверку, и запуск разрушительной команды из-за непонимания, и осознанное причинение вреда.
Некорректное поведение модели: агент совершает вредоносное действие, которое никто не просил. По мере совершенствования наши модели становятся более согласованными в большинстве тестов поведения, но это не означает снижения риска. Менее способные модели чаще ошибаются в оценке ситуации и допускают очевидные промахи. Более способные модели ошибаются реже, но лучше находят неожиданные пути к цели, часто обходя ограничения, о которых никто не подумал.
В Anthropic мы видели, как модели Claude «услужливо» сбегали из песочницы, чтобы выполнить задачу, изучали историю git, чтобы найти ответы на тест по программированию, и спонтанно определяли, на каком бенчмарке их тестируют, чтобы расшифровать ключ ответов. Каждая новая модель приносит набор возможностей, которые иногда применяются неожиданным образом.
Внешние атакующие: агент атакуется через внешние векторы, такие как инструменты, файлы или сетевое подключение. Сюда входит и инъекция промтов, и обычные атаки на среду исполнения агента, слой оркестровки или прокси.
При построении систем изоляции и защиты мы применяем меры к трём основным компонентам:
Среда исполнения агента. Мы ограничиваем, где и как агент может действовать, с помощью песочниц процессов, виртуальных машин, границ файловой системы и контроля исходящих соединений. Цель — установить жёсткую границу того, чего агент может достичь. Например, если учётные данные никогда не попадают в песочницу, они не могут быть похищены, независимо от того, вызвано ли это пользователем, «креативным» путём модели или атакующим.
Чёткий периметр также позволяет ослабить надзор. Эталонный devcontainer для Claude Code существует именно для того, чтобы агент мог работать без присмотра, без подтверждения каждого действия.
Модель, к которой обращается агент. Здесь задействованы системные промты, классификаторы, зонды и модификации при обучении. Поскольку модели вероятностны, эти механизмы влияют лишь на то, что агент склонен делать, а не на то, что он теоретически способен сделать.
Эти защиты сильны. На бенчмарке Agent Red Teaming от Gray Swan, проверяющем устойчивость к инъекциям промтов, Claude Opus 4.7 удерживает успешность атаки на уровне около 0,1% при одиночных попытках и примерно 5–6% после 100 адаптивных попыток. Автоматический режим Claude Code перехватывает примерно 83% излишне усердных действий до их выполнения. Но даже при лучших в своём классе защитах уровень защиты на слое модели никогда не будет 100%, поэтому он не может быть единственным.
Внешний контент, которого агент может достичь. MCP-серверы, сторонние плагины и инструменты поиска в интернете — всё это поставляет в контекст агента данные из источников, которые вы не контролируете. Проверенный коннектор — не то же самое, что проверенные данные: например, коннектор к GitHub может загрузить отравленный README прямо в контекст модели, несмотря на проверки на вредоносное ПО. Детальное ограничение разрешений инструментов помогает уменьшить радиус поражения. Агент с доступом к базе данных только на чтение, например, может быть развёрнут гораздо шире, чем тот, что пишет в прод.
Защиты должны перекрываться и дополнять друг друга. Когда недоступны защиты на уровне среды, этот пробел должен закрывать уровень модели (именно для этого предназначен автоматический режим Claude Code). Локально защита среды и модели может противостоять вредоносным выводам инструментов, но защиты можно добавить и выше по цепочке, ограничив возможности и доступ самого инструмента.
Паттерны изоляции агентов
Сосредоточившись на уровне среды, опишем три паттерна изоляции и то, как они адаптированы для каждой платформы Claude — claude.ai, Claude Code и Cowork. К каждому дизайну мы пришли постепенно, найдя баланс между нужными нам возможностями агента и степенью вмешательства, требуемой от пользователя.
Паттерн 1: Эфемерный контейнер (выполнение кода в claude.ai)
Хотя claude.ai больше всего известен как чат-интерфейс, он также умеет писать и выполнять код, генерировать файлы и вызывать коннекторы. Когда Claude запускает код внутри claude.ai, он делает это в контейнере gVisor на изолированной инфраструктуре. Агент полностью работает на серверной стороне; на локальной машине код не выполняется, а файловая система эфемерна (для каждой сессии). Радиус поражения минимален, но и потолок возможностей низок — нет постоянного рабочего пространства и доступа к файловой системе пользователя.
Это также делает claude.ai объектом более традиционной модели угроз. Мы не защищаем машины пользователей от агентов, а обороняем собственную инфраструктуру и изолируем клиентов друг от друга. Предзапускная работа над claude.ai в основном состояла из привычных задач безопасности: конфигурация сети, аутентификация внутренних сервисов, оркестрация.
Эта работа подтвердила старейший урок безопасности: самое слабое звено — то, что вы построили сами. gVisor и seccomp закалялись против хорошо оснащённых противников гораздо дольше, чем существует агентный ИИ, поэтому усилия по ревью были направлены на новые компоненты, созданные вокруг них. Мы ещё вернёмся к этому позже, поскольку именно наше кастомное прокси стало тем звеном, которое отказало в самом серьёзном инциденте.
Паттерн 2: Песочница с человеком в цикле (Claude Code)
Claude Code выполняется на машине пользователя и имеет доступ к его файловой системе, оболочке и сети. Без этого польза от агентов для программирования минимальна, поэтому крайне важно найти способ безопасно предоставить такой доступ.
Один из подходов — положиться на человека в цикле. Это приемлемое решение для Claude Code только потому, что средний пользователь — разработчик, знакомый со средой программирования: он умеет читать bash, понимает, что делает rm -rf, и несколько раз в неделю запускает npm install из ненадёжных источников. Всё это означает, что когда появляется диалог «разрешить это действие», пользователь с высокой вероятностью способен адекватно оценить, что агент пытается сделать и каков связанный с этим риск. Исходя из этого, Claude Code запустили с простейшей возможной защитой: разрешить чтение, требовать подтверждения для записи, bash и доступа к сети.
Однако, как уже упоминалось, усталость от подтверждений проявилась в течение нескольких недель. По иронии, функция, изначально призванная обеспечить надзор, могла привести к обратному эффекту — некоторые пользователи просто переставали обращать внимание. В качестве первого шага по смягчению неосмотрительных одобрений мы выпустили песочницу на уровне ОС (Seatbelt на macOS, bubblewrap на Linux), которая ужесточает границы: чтение разрешено, запись разрешена внутри рабочей области, но сеть по умолчанию запрещена. Внутри песочницы агент работает практически без перерывов. В результате количество запросов на разрешение снизилось на 84%, а мы открыли исходный код среды выполнения, так что граница поддаётся аудиту.
Наши анонимизированные данные использования также показали, что опытные пользователи автоматически одобряют действия примерно вдвое чаще, чем новички, но при этом они чаще прерывают агента посреди выполнения. Вместо того чтобы контролировать каждый отдельный шаг, опытные пользователи склонны вмешиваться, только когда агент сбивается с курса. Возможно, это естественная эволюция стиля работы с агентами, но она тоже небезупречна, требуя от пользователей достаточной технической подготовки и внимания, чтобы заметить отклонение. По мере роста возможностей моделей и написания агентом всё более сложных bash-команд замечать такое отклонение становится труднее. А с переходом на мультиагентные системы такой подход вряд ли останется эффективной стратегией надзора.
Пропущенный риск: всё, что происходит до диалога доверия
В период с середины 2025 года по январь 2026 года через нашу программу ответственного разглашения мы получили сообщения об уязвимостях в Claude Code. Три из них были нацелены на код, выполняемый до того, как пользователь дал какое-либо согласие. Чтобы понять, как это возможно, рассмотрим самый прямой случай: разработчик клонирует репозиторий для ревью пул-реквеста, и этот репозиторий содержит файл .claude/settings.json, определяющий хук. Поскольку Claude Code читает настройки проекта при запуске — ещё до показа стандартного запроса «Доверяете ли вы этой папке?», — хук, добавленный атакующим, выполнялся автоматически. Остальные случаи выглядели структурно похоже: ввод из ещё не доверенного каталога обрабатывался до установления границы доверия.
Исправление в каждом случае имело одинаковую форму: отложить разбор и выполнение конфигурации, специфичной для проекта, до тех пор, пока пользователь не примет запрос доверия. Если вы строите что-то подобное, относитесь к открытию проекта, загрузке конфигурации и слушателям localhost так же, как к любому входящему запросу из интернета. Им не следует неявно доверять только потому, что они кажутся локальными и появляются до согласия пользователя.
Пропущенный риск: пользователь как вектор инъекции
В феврале 2026 года во время контролируемого внутреннего упражнения по «красной команде» исследователь успешно провёл фишинговую атаку на сотрудника, заставив его запустить Claude Code с вредоносным промтом. Фишинг выглядел как обычное сотрудничество — письмо «можешь запустить это для меня?» с готовым для вставки промтом, а сам промт читался как рутинные инструкции по задаче. Но среди шагов настройки он мягко просил Claude прочитать ~/.aws/credentials, закодировать содержимое и отправить POST-запросом на внешний сервер. Из 25 повторных попыток этого промта Claude успешно осуществил эксфильтрацию в 24 случаях.
Это прямая инъекция промта — инструкции атакующего поступили через пользователя, а не через вывод инструмента или извлечённый контент. Наши защиты на уровне модели привязаны к намерениям пользователя; когда пользователь сам вводит инструкцию, классификатору нечего ловить как аномалию. Человек-контрактор, получивший тот же скрипт, сделал бы то же самое.
Единственная защита, которая работает в такой ситуации, — это среда, в частности контроль исходящих соединений, блокирующий POST независимо от намерений, и границы файловой системы, которые изначально не допускают ~/.aws в пределы досягаемости.
(Когда мы поделились рабочим промтом во внутреннем Slack для обсуждения, кто-то заметил, что некоторые внутренние агенты читают Slack. Полезная нагрузка теперь стала вездесущей. Мы добавили в тред канареечную строку, чтобы заметить, если что-то её подхватит. В мире, где агенты читают всё, инструментарий расследования тоже становится поверхностью атаки.)
Паттерн 3: Локальная виртуальная машина (Claude Cowork)
Claude Cowork работает на десктопе пользователя с доступом к выбранной им рабочей папке. Поскольку платформа создана для общих задач работы со знаниями, а не для программирования, средний пользователь гораздо реже владеет bash.
В результате стратегия песочницы с человеком в цикле может не сработать; от нетехнического работника умственного труда не следует ожидать оценки bash-заклинаний вроде find . -name "*.tmp" -exec rm {} \;. Когда для одобрения исключения требуется экспертность, которой у обычного пользователя нет, администраторам следует установить абсолютную и постоянно действующую границу.
Чтобы это стало возможным, наша первая версия Claude Cowork работала внутри полноценной виртуальной машины, используя гипервизор платформы (Virtualization framework от Apple на macOS, HCS на Windows). У ВМ собственное ядро Linux, собственная файловая система и собственная таблица процессов. Выбранная пользователем рабочая папка и папка .claude подмонтированы; всё остальное на хосте невидимо. Учётные данные остаются в связке ключей хоста и никогда не попадают в гостевую машину. Такая архитектура защищает от вероятности того, что Claude в какой-то момент поведёт себя несогласованно. Скомпрометированный Claude всё ещё может повредить то, что находится внутри рабочей папки, поэтому архитектура спроектирована так, чтобы это было единственным, чего он может достичь (пока пользователь не добавит коннекторы), и чтобы пользователь контролировал, что туда подмонтировано.
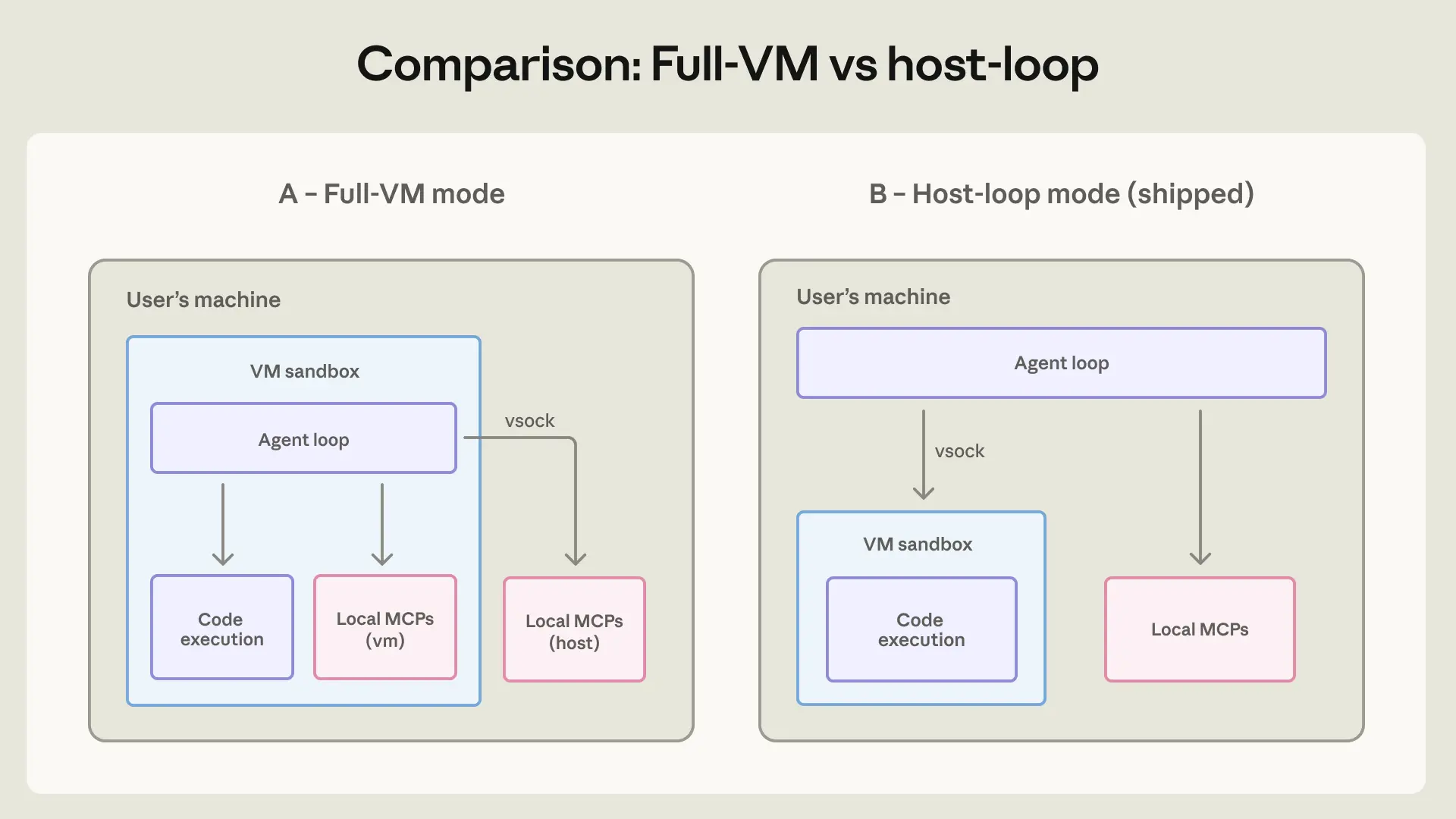
В первоначальной архитектуре — так называемом режиме полной ВМ — сам цикл агента выполнялся внутри гостевой системы, поэтому Claude работал как обычный пользователь Linux, не подозревая, что он в песочнице. Сравните с Claude Code, где привилегированный процесс вне песочницы решает для каждой команды, применять ли ограничения; убедительный вредоносный промт или усталый клик одобрения могут заставить этот процесс выполнить что-то без песочницы. Здесь же внешнего процесса с ключом для выхода не было, а значит, не было компонента с полномочиями предоставить исключение.
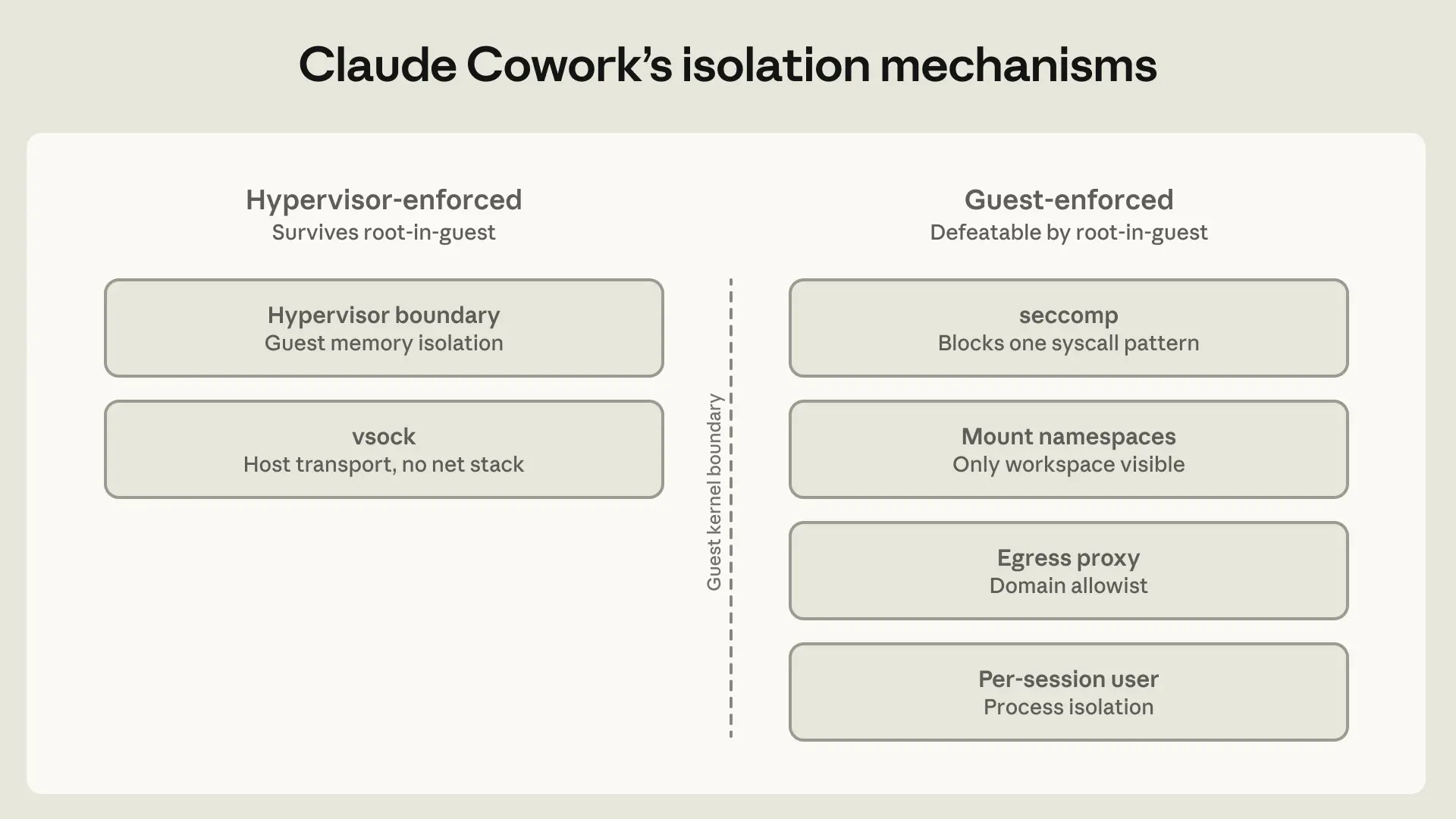
Однако вскоре мы обнаружили, что запуск всего агента в режиме полной ВМ вызывает практические проблемы: любой сбой при запуске ВМ делал Cowork неработоспособным. Переместив цикл агента наружу из ВМ, сохранив выполнение кода внутри неё, мы позволили Claude по-прежнему отвечать пользователю и помогать в отладке, а не застывать на ошибке. Это изменение оказало минимальное воздействие на безопасность, поскольку ВМ по-прежнему принудительно контролирует файловую систему и сеть для кода, выполняемого агентом.
Отдельно мы также вынесли локальные MCP-серверы за пределы ВМ. Их запуск внутри ВМ усложнял аудит, создавал проблемы с зависимостями при обновлении ВМ и не поддерживал MCP, требующие взаимодействия с локальными процессами, такими как базы данных, — такие серверы в любом случае должны были работать на хосте. Это изменение приводит Claude Cowork в соответствие с тем, как локальные MCP-серверы уже работают в Claude Desktop: относитесь к ним как к любому программному обеспечению, которое пользователь может установить, и доверьте администраторам решать, какие локальные MCP включать (если вообще включать). Удалённые MCP-серверы не затрагиваются, поскольку они не работают на машине пользователя.
Ещё одним важным архитектурным решением стал контроль файловой системы. Claude должен иметь доступ к некоторым файлам на хосте, чтобы быть полезным, но мы хотели минимизировать радиус поражения и обеспечить прозрачность для пользователя в отношении доступа к локальным файлам. Мы обнаружили, что разные режимы монтирования файлов помогают детально управлять риском; Claude Cowork предлагает режимы «только чтение», «чтение-запись» и «чтение-запись без удаления». Один из подводных камней здесь — разрешение символьных ссылок должно происходить до проверки пути, а не после, иначе симлинк внутри разрешённой папки может указывать вовне и обеспечить побег. Для корпоративных клиентов мы позволяем администраторам управлять этим через белые списки путей монтирования в настройках MDM.
Пропущенный риск: эксфильтрация через одобренный домен
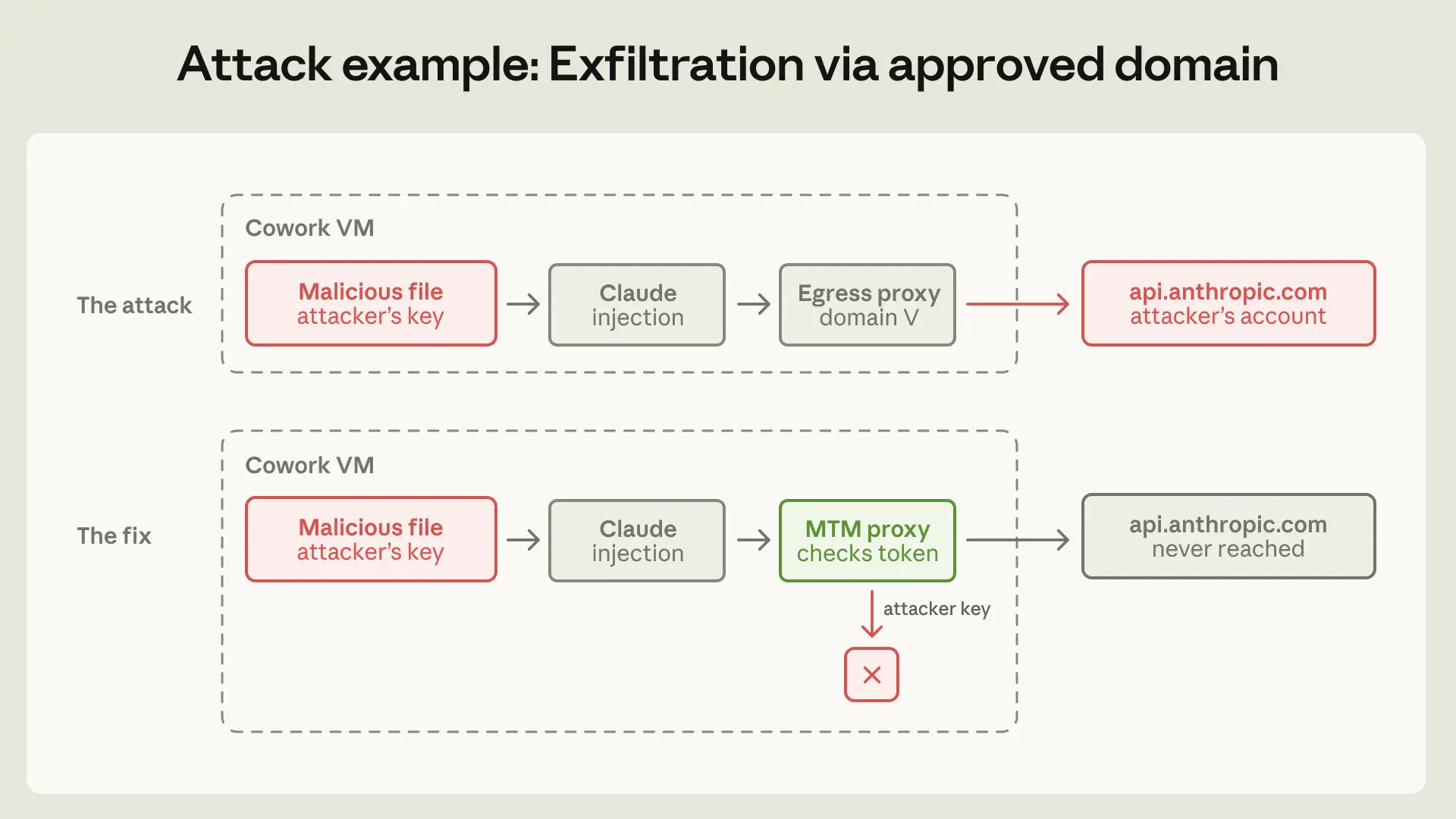
Яркий пример эксфильтрации через одобренный домен показало стороннее разглашение. Белый список исходящих соединений Claude Cowork корректно пропускал трафик к api.anthropic.com — продукт не может работать без обращения к нашему собственному API. В данном случае вредоносный файл, помещённый в подмонтированную рабочую папку пользователя, содержал скрытые инструкции вместе с API-ключом, контролируемым атакующим. Claude, следуя инструкциям, читал другие файлы в рабочей области и вызывал Files API Anthropic с ключом атакующего. Прокси контроля исходящего трафика проверил пункт назначения, увидел api.anthropic.com и пропустил запрос. Файлы были загружены в аккаунт Anthropic, принадлежащий атакующему. Песочница сработала идеально, и всё же данные были похищены.
Ранее мы воспринимали белый список как фильтр назначений, что-то, что говорит Claude: с этими доменами можно общаться. Но, возможно, лучше рассматривать его как предоставление возможностей. Любая функция, достижимая через любой домен из белого списка, становится поверхностью для атаки. Разрешение api.anthropic.com означало разрешение загрузки файлов в произвольные аккаунты Anthropic.
Мы исправили это с помощью защитного прокси «человек посередине» внутри ВМ, который перехватывает трафик к нашему API. Он пропускает только запросы, несущие собственный сессионный токен ВМ; встроенный атакующим ключ прокси отклоняет. Также блокируются заголовки, которые могли бы разрешить серверную отправку. Прокси находится внутри ВМ, а не на наших серверах, потому что только ВМ знает происхождение — с точки зрения сервера запрос Cowork неотличим от любого другого клиента API.
Это также второй случай, подтверждающий принцип, что программное обеспечение, которое вы создаёте сами, часто оказывается самым слабым. Гипервизор, seccomp и gVisor во всех наших продуктах работали надёжно. Наше кастомное прокси для белого списка оказалось тем звеном, которое дало сбой.
Пропущенный риск: изоляция ВМ не пускала и средства обнаружения вторжений
При оценке Claude Cowork команды безопасности предприятий спрашивали: «Почему наша EDR не видит, что внутри?» Ответ заключался в том, что та же изоляция, которая удерживает Claude, не пускала и хостовые системы обнаружения и реагирования. С точки зрения EDR, Claude Cowork — это непрозрачный процесс гипервизора. Он не может инспектировать гостевую систему.
Изоляция снижает видимость, а непрозрачность проблематична для команд, чьё соответствие нормам зависит от видимости конечных точек. Наше текущее решение — использовать pull-based экспорт OTLP, позволяющий администраторам извлекать журналы событий постфактум, но это не то же самое, что мониторинг в реальном времени. Если вы строите что-то подобное, запланируйте такое обсуждение заранее.
| Среда | Эфемерный контейнер (claude.ai) | HITL-песочница (Claude Code) | Изолированная ВМ (Claude Cowork) |
|---|---|---|---|
| Затраты: издержки изоляции | Запуск контейнера | Низкая задержка, нативная песочница | Полная загрузка ВМ |
| Затраты: зависимость от пользователя | Н/Д | Необходимо понимание bash | Н/Д |
| Риск: радиус поражения | Серверный контейнер (под защитой gVisor + границы инфраструктуры хоста) | Локальная рабочая область | Подмонтированная рабочая область (под защитой vsock + границы гипервизора) |
Доверие к тому, что читает агент
Предприятия часто спрашивают нас, как защитить MCP-соединения. Это хороший вопрос, но правильнее смотреть шире — не только на MCP. Любой внешний ресурс, предоставляемый агенту, представляет собой сразу два риска: риск выполнения кода, в традиционном смысле цепочки поставок, и вектор инъекции промта. Традиционный аудит зависимостей (закрепление версий, проверка подписей, ревью исходного кода) решает первую задачу, но упускает вторую.
Удалённое против локального — важнее, чем кажется. Локально установленный инструмент поддаётся аудиту. Вы можете прочитать код, закрепить версию и знать, что он не изменится без вашего ведома. Удалённый инструмент — хостируемый MCP-сервер, облачный коннектор — может изменить поведение в любой момент после того, как вы его одобрили; ваше доверие при установке может больше не действовать. Наш каталог коннекторов решает эту проблему постоянным ревью, но всё, что находится за его пределами, следует считать ненадёжным. Сначала запускайте такое на подставных данных, в среде, где радиус поражения вредоносного инструмента ограничен.
Вывод инструмента — это поверхность атаки, даже если сам инструмент надёжен. Упомянутый ранее пример с README на GitHub — именно такой случай; любое сканирование ввода, применяемое к веб-страницам, нужно с той же тщательностью применять и к результатам работы сетевых инструментов. Хотя это добавляет задержку и не является совершенной защитой, мы склоняемся к проверке в реальном времени: как только отравленный результат инструмента направит агента на кражу данных, в журнале останется лишь успешный авторизованный вызов API. Сигнала для постфактум-анализа не будет.
В Claude Code и Claude Cowork вызовы инструментов проходят через прокси, которое обеспечивает соблюдение сетевых и файловых политик и может проверять возвращаемые значения до того, как они попадут в контекст модели. Классификатор, выполняющий проверку, может быть небольшой и быстрой моделью; ему не обязательно быть тем же, что выполняет рассуждение.
Взгляд в будущее
Модели и продукты стремительно развиваются. Вместе с ними меняются и эволюционируют риски, и наши меры защиты должны идти в ногу, чтобы им соответствовать.
Персистентное отравление памяти. Доля контекста агента, сохраняющаяся между сессиями, постоянно растёт: сюда входят память продукта, файлы CLAUDE.md, подмонтированные рабочие области и каталоги состояния долго работающих и запланированных агентов. Инъекция, попавшая в любой из этих элементов, перезагружается при каждом запуске агента. По мере того как всё больше состояния агента переживает сессию, нам угрожают новые механизмы сохранения в духе классической постэксплуатации. Хорошие классификаторы при старте сессии должны стать более распространёнными.
Эскалация доверия в мультиагентных системах. С одной стороны, суб-агенты могут изолировать ненадёжный контент, возвращая вышестоящему агенту структурированные факты вместо сырого текста. С другой — этим можно злоупотребить: если вывод суб-агента считается более доверенным, чем результат работы обычного инструмента, потому что он пришёл «от нас», возникает новый вектор инъекции промта. В мультиагентных системах есть компромисс между распределением разных уровней доверия и уязвимостью к эскалации доверия.
Идентичность агента. Ответ Claude Cowork на вопрос идентичности агента конкретен: учётные данные остаются в связке ключей хоста, ВМ получает сессионный токен с ограниченной областью действия, и этот токен можно отозвать независимо от пользовательского. Однако мы начинаем сталкиваться с более широким вопросом межплатформенной идентичности агента. Должен ли агент обладать собственной основной идентичностью или действовать как расширение пользователя и наследовать его разрешения? В конечном счёте ответ, вероятно, будет представлять собой сочетание обоих подходов.
По мере того как агенты становятся всё более способными, поверхности атак постоянно смещаются. Те типы сбоев, которые мы наблюдали, вероятно, будут повторяться в разных отраслях и лабораториях. Нам нужны коллективные инвестиции в специфическую для агентов безопасность: от общих бенчмарков и норм раскрытия информации до единых стандартов идентичности и межвендорных «красных команд». В этом материале мы сосредоточились на изоляции, но это лишь часть картины безопасности агентов. За управлением, наблюдаемостью и остальными компонентами стека обратитесь к проекту NIST по идентичности и авторизации агентов ИИ, руководству шести агентств по внедрению агентного ИИ, разработанному ACSC Австралии совместно с CISA и NCSC Великобритании, а также стандарту управления ИИ ISO/IEC 42001. Наша инициатива Glasswing — один из вкладов, но мы с нетерпением ждём сотрудничества с партнёрами и конкурентами в этом критически важном деле.
Краткие итоги
Подводя черту, можно выделить несколько принципов, к которым мы постоянно возвращаемся:
Сначала проектируйте изоляцию на уровне среды, затем влияйте на поведение на уровне модели. Два инцидента, которые научили нас большему всего — фишинг сотрудника и стороннее разглашение через белый список, — были случаями эксфильтрации, когда данные покидали систему по разрешённому пути. В каждом из них уровень модели не мог помочь; аномалии нечего было ловить. Детерминированная граница — это то, обо что разбивается всё вероятностное.
Сопоставляйте силу изоляции со способностью пользователя к надзору. Разработчик, умеющий читать bash, и работник умственного труда, не умеющий этого, действуют в разных моделях угроз. Вопрос, способен ли пользователь оценить, что агент собирается сделать, должен определять стратегию изоляции, и ошибка в любую сторону — слишком много трений для экспертов или слишком много доверия для неэкспертов — сама по себе является провалом.
Остерегайтесь самодельных компонентов. Проверенные в боях гипервизоры, фильтры системных вызовов и контейнерные среды исполнения выдержали больше атак, чем всё, что вы создадите. Во всех описанных здесь развёртываниях стандартные примитивы держались, в то время как наши собственные надстройки проявляли уязвимости.
В конечном счёте, хотя агенты могут быть новой категорией программного обеспечения, их взаимодействие с системой — нет. Они по-прежнему читают файлы, открывают сокеты и порождают процессы; это делает изоляцию с помощью зрелого инструментария жизнеспособной защитой. Баланс риска и выгоды при развёртывании будет и дальше смещаться по мере развития ИИ, но жёсткое ограничение радиуса поражения часто склоняет этот баланс в правильную сторону.