В последние недели команда Anthropic изучила сообщения о снижении качества ответов Claude у части пользователей. Выяснилось, что виноваты три независимых обновления, затронувшие Claude Code, Claude Agent SDK и Claude Coworker. API остался нетронутым.
К 20 апреля (версия v2.1.116) все проблемы устранены.
Здесь мы расскажем, что произошло, как это починили и какие меры помогут избежать повторений.
Жалобы на деградацию воспринимаются очень серьезно. Модели не ухудшают специально, и проверка сразу показала, что API и слой вывода работают стабильно.
Расследование выявило три причины:
- 4 марта в Claude Code уровень усилий по умолчанию сменили с
highнаmedium, чтобы убрать чрезмерные задержки, из-за которых интерфейс казался замороженным. Решение оказалось неудачным. 7 апреля вернули исходный вариант после отзывов: пользователи хотят высокий интеллект по умолчанию и сами выбирают упрощенный режим для легких задач. Затронуло Sonnet 4.6 и Opus 4.6. - 26 марта внедрили оптимизацию: очищали старые рассуждения из сессий, простаивавших час+, чтобы ускорить возобновление. Из-за бага очистка повторялась на каждом шаге сессии, делая Claude забывчивым и повторяющимся. Исправили 10 апреля. Затронуло Sonnet 4.6 и Opus 4.6.
- 16 апреля добавили в системный промт указание сократить многословность. Вместе с другими правками это ухудшило качество кода; откатили 20 апреля. Затронуло Sonnet 4.6, Opus 4.6 и Opus 4.7.
Поскольку изменения коснулись разных потоков трафика в разное время, эффект выглядел как общее, но нестабильное ухудшение. Хотя расследование стартовало в начале марта, сначала отзывы казались обычной вариацией, а внутренние тесты и оценки не воспроизвели проблемы.
Такого опыта от Claude Code ждать не стоит. С 23 апреля лимиты использования сброшены для всех подписчиков.
Смена уровня усилий рассуждений по умолчанию в Claude Code
При запуске Opus 4.6 в Claude Code в феврале уровень усилий по умолчанию установили на high.
Вскоре пользователи отметили: в высоком режиме Opus 4.6 иногда слишком долго думает, интерфейс зависает, растут задержки и расход токенов.
Чем дольше модель размышляет, тем лучше результат. Уровни усилий позволяют выбирать баланс: больше мышления или скорость и экономия лимитов. При калибровке учитывают эту кривую вычислений во время теста, чтобы предложить оптимальные точки. В продукте выбирают значение по умолчанию для Messages API как параметр effort, а другие варианты доступны через /effort.
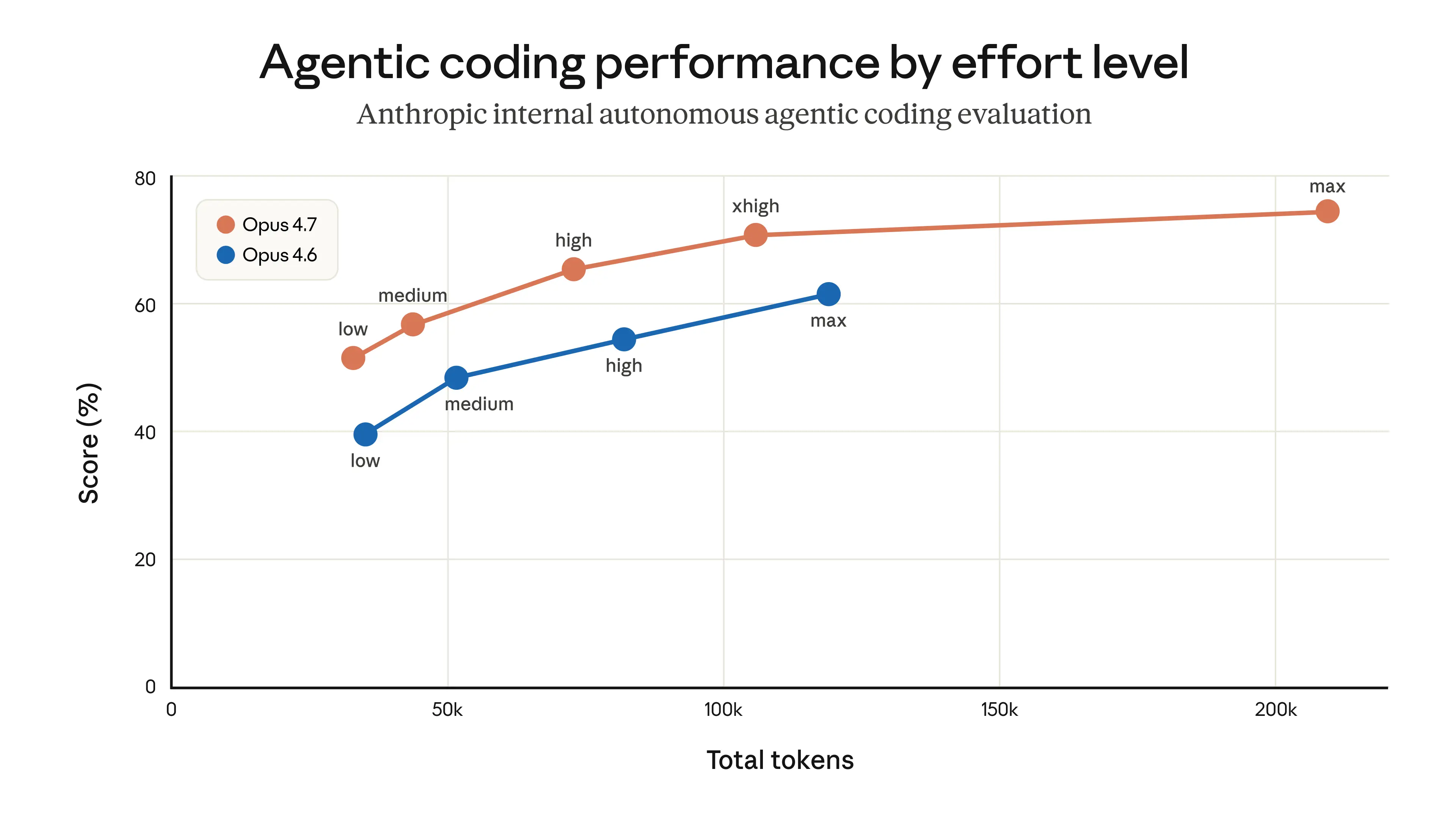
Внутренние тесты показали: средний уровень дает чуть меньший интеллект, но сильно меньше задержек для большинства задач. Нет хвостовых простоев, лимиты используются эффективнее. Поэтому сделали medium значением по умолчанию и объяснили в диалоге продукта.
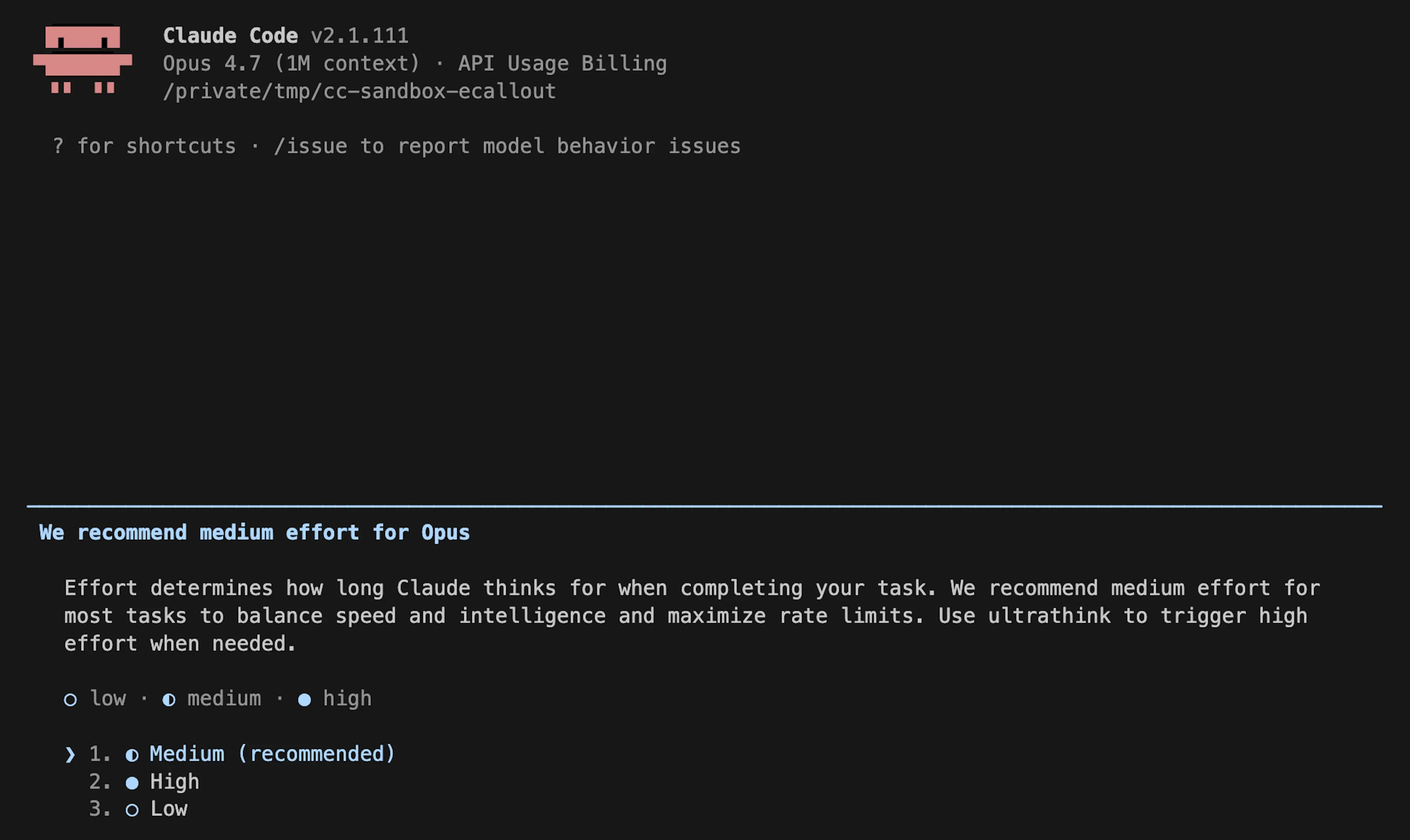
После внедрения отзывы указали на падение интеллекта. Добавили уведомления при запуске, селектор усилий в строке и ultrathink, но большинство осталось на medium.
Учитывая дополнительные отзывы, 7 апреля вернули: теперь по умолчанию xhigh для Opus 4.7 и high для остальных моделей.
Оптимизация кэша, стирающая прошлые рассуждения
Обычно рассуждения Claude сохраняются в истории чата, чтобы на следующих шагах модель видела причины правок и вызовов инструментов.
26 марта ввели улучшение эффективности. Prompt caching ускоряет последовательные API-вызовы и снижает их стоимость. Токены ввода кэшируются при запросе, но после паузы промт вытесняется. Управление кэшем — приоритет (подход).
Идея простая: для сессий с паузой час+ очищать старые рассуждения, чтобы сократить uncached токены (запрос все равно miss). Потом передавать полную историю. Использовали заголовок API clear_thinking_20251015 с keep:1.
Баг в реализации: вместо разовой очистки она повторялась каждый раз. После первой паузы каждый запрос сохранял только последний блок рассуждений, отбрасывая остальное. Эффект накапливался: в середине tool use фоллоу-ап сбрасывал даже текущие рассуждения. Claude продолжал, но без контекста — отсюда забывчивость, повторы и странные инструменты.
Повторные misses кэша объясняют быстрый расход лимитов.
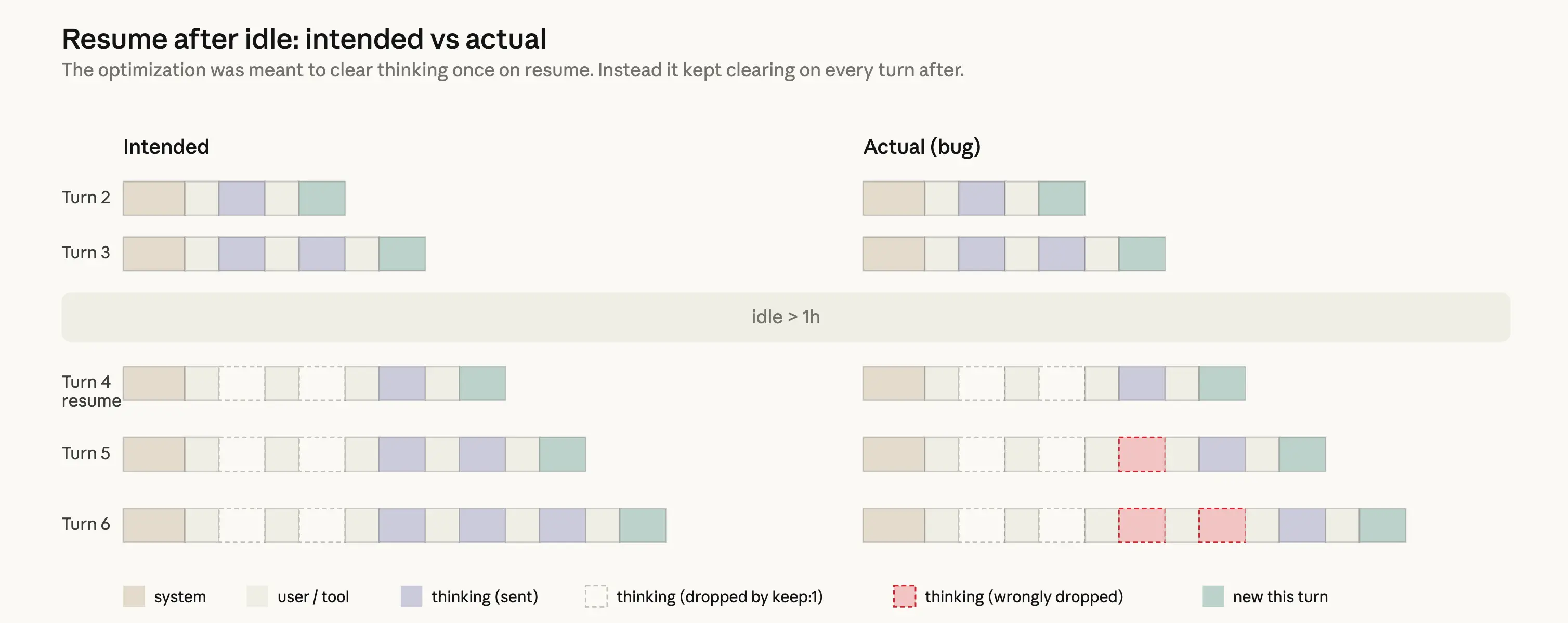
Два эксперимента мешали воспроизвести: внутренний по очередям сообщений и правка отображения thinking, подавлявшие баг в CLI. Не поймали в ревью кода, тестах, dogfooding.
Баг на стыке контекста Claude Code, API и extended thinking. Трудно воспроизвести в corner case (старые сессии).
В расследовании протестировали Code Review на PR с багом через Opus 4.7: с полным контекстом репозиториев нашел, 4.6 — нет. Теперь добавляют поддержку доп. репозиториев для отзывов.
Исправили 10 апреля в v2.1.101.
Правка системного промта против многословности
Claude Opus 4.7 по сравнению с предшественником (как писали при запуске) склонен к детальным ответам. Это помогает на сложных задачах, но увеличивает токены вывода.
Перед релизом 4.7 настраивали Claude Code: модели разные, оптимизируют harness и продукт.
Инструменты против verbosity: тренировка, промты, UX мышления. Применили все, но добавка в системный промт сильно ударила по интеллекту:
«Ограничения длины: текст между вызовами инструментов — ≤25 слов. Финальные ответы — ≤100 слов, если задача не требует большего.»
После недель тестов без регрессов в оценках внедрили 16 апреля с Opus 4.7.
В расследовании провели абляции (убирали строки промта) на широком наборе оценок. Одна показала -3% для 4.6 и 4.7. Откатили 20 апреля.
Что дальше
Чтобы избежать повторений, большая часть команды перейдет на публичную сборку Claude Code (а не тестовую); улучшат внутренний Code Review и выпустят клиентам.
Ужесточают контроль системных промтов: для каждого изменения — полный набор eval по моделям, абляции, новые инструменты для ревью/аудита. В CLAUDE.md добавили гейт для модель-специфичных правок. Для рисков интеллекта — soak, расширенные eval, gradual rollout.
В X запустили @ClaudeDevs для глубоких объяснений решений. Аналогичные обновления — в тредах GitHub.
Спасибо пользователям: те, кто слал /feedback или публиковал воспроизводимые примеры, помогли выявить и исправить. Сегодня сброшены лимиты для всех.
Огромная благодарность за отзывы и терпение.