Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Статья о применении генеративного ИИ в моделировании природных катастроф: диффузионные модели создают множество сценариев для более точной оценки рисков, но сталкиваются с проблемой галлюцинаций и противоречием интересам страховщиков, которые предпочитают заниженные оценки убытков.
KPMG включила в отчёт о будущем ИИ вымышленные кейсы об использовании технологии в UBS, NHS и других организациях. GPTZero обнаружил ошибки, Financial Times их подтвердил — компании опровергли заявления. Инцидент показал опасность «вторичных галлюцинаций» от авторитетных отчётов и проблемы «vibe citing» в AI-поиске.
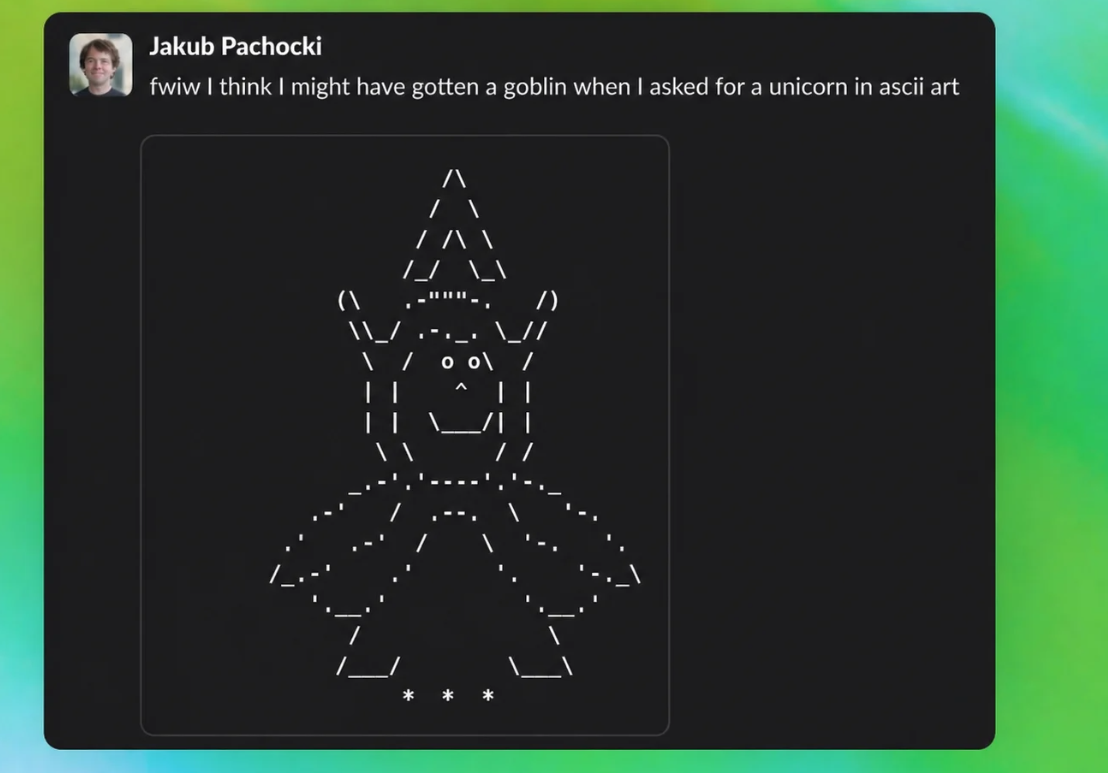
OpenAI разобралась, почему с GPT-5.1 модели ChatGPT стали часто вставлять гоблинов в ответы: сбой в поощрении при дообучении 'Nerdy' личности вызвал 175-процентный рост упоминаний. Привычка распространилась на другие режимы через обратную связь, компания устранила дефект и добавила запреты. Случай подчёркивает риски непредвиденных эффектов от мелких изменений в обучении.
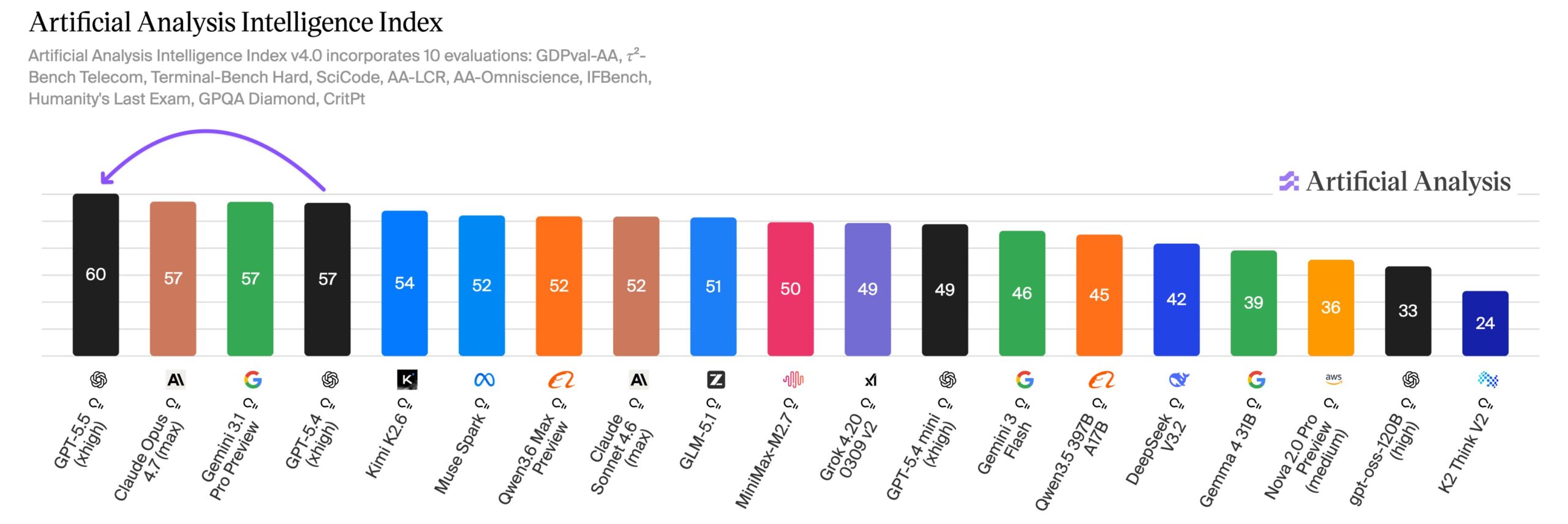
GPT-5.5 возглавила Intelligence Index Artificial Analysis с 60 очками, опередив Claude Opus 4.7 и Gemini 3.1 Pro Preview на три пункта. Удвоение цены API смягчено экономией 40% токенов, итого рост на 20%, но галлюцинаций стало 86% — хуже конкурентов. Бенчмарки хвалят цену-производительность, однако в программировании и галлюцинациях модель не без изъянов.
Системы RAG развивают LLM, устраняя галлюцинации и проблемы с актуальными знаниями. Статья разбирает семь шагов: от очистки данных и разбиения на чанки до векторизации, хранения, извлечения контекста и генерации ответов. Это позволяет создавать надежные ИИ-приложения на свежих данных.
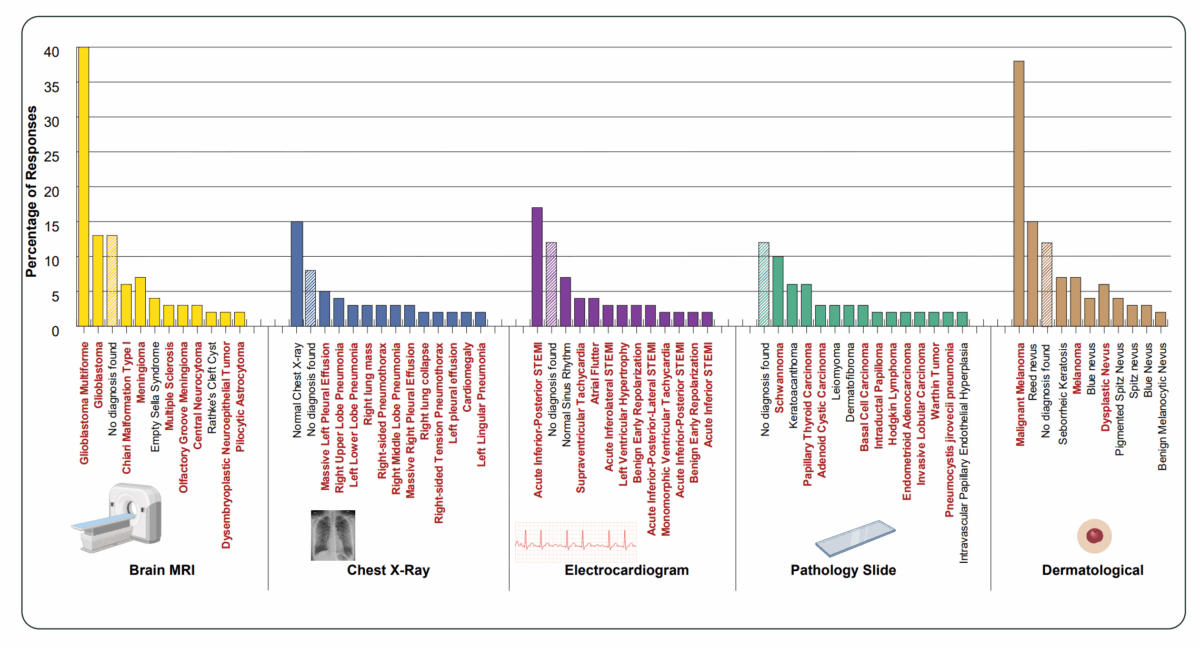
Фронтирные ИИ-модели уверенно описывают несуществующие изображения в 60–100% случаев, достигая 70–80% баллов бенчмарков без визуала. Текстовая модель на 3 млрд параметров обошла мультимодалки и радиологов, а метод B-Clean выявил утечки в тестах. Это подрывает доверие к визуальным претензиям ИИ и требует новых подходов к оценке.
Википедия запретила редакторам генерировать или перерабатывать контент статей с помощью больших языковых моделей. Изменение политики одобрили 40 голосами против 2. ИИ разрешают использовать только для базовых правок собственного текста после человеческой проверки.
Encyclopedia Britannica и Merriam-Webster подали иск против OpenAI за использование почти 100 000 статей в обучении ИИ без разрешения, а также за копирование контента в ответах и галлюцинации. Это часть волны судебных дел от издателей вроде New York Times и газет США и Канады. Прецедентов по обучению моделей на защищенных данных мало, но пример Anthropic показывает риски.
Два немецких суда вынесли противоположные вердикты об ответственности Google за ИИ-обзоры. Берлин счёл их лишь новым форматом поиска, не нарушающим закон, а Мюнхен возложил на компанию прямую ответственность за ложные утверждения ИИ. Противоречие может серьёзно повлиять на развитие ИИ-поиска.
KPMG пришлось удалить отчет об агентном ИИ после того, как в нем обнаружились вымышленные данные о клиентах. Причиной стали галлюцинации нейросети, которую использовали при подготовке документа.
Goodfire представила Silico — платформу механистической интерпретируемости для LLM. Инструмент автоматизирует анализ нейронов, помогает исправлять галлюцинации, этические сбои и ошибки вроде сравнения 9.11 с 9.9. Это позволит малым командам создавать надежные модели без проб и ошибок.
Глоссарий разбирает ключевые термины ИИ от AGI и LLM до галлюцинаций и весов. Объяснения охватывают определения, примеры и связи понятий вроде цепочки мыслей, дистилляции, диффузии. Материал помогает ориентироваться в новостях ИИ, сохраняя все технические детали.
The New York Times прекратила работу с фрилансером Алексом Престоном: его ИИ-инструмент заимствовал текст рецензии The Guardian на роман Watching Over Her. Престон не заметил плагиата и сдал материал. В Ars Technica редактор опубликовал вымышленные цитаты ChatGPT из недоступного блога.
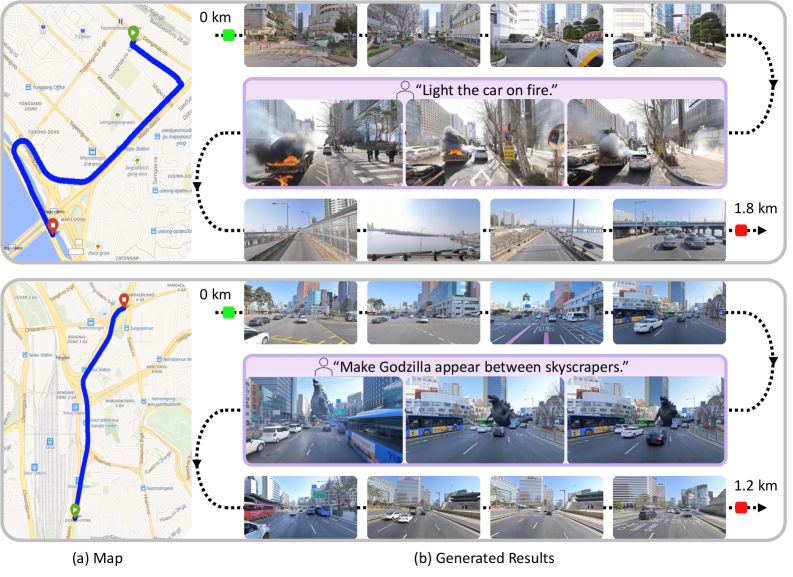
Naver разработала Seoul World Model — видео-модель на базе 1,2 млн панорам Street View Сеула, которая генерирует реалистичные видео по реальным маршрутам без вымысла. Она решает проблемы с временными объектами, пробелами в данных и накоплением ошибок, обобщаясь на другие города вроде Пусана и Энн-Арбора. Модель превосходит конкурентов и открывает применение в автономном вождении и урбанистике.
Галлюцинации в LLM решают как системную задачу семью методами: от RAG и обязательных цитат до инструментов, верификации и мониторинга. Подходы опираются на данные, проверки и отказы, повышая надежность приложений. Непрерывная оценка предотвращает регресс качества.
Статьи на топовых ИИ-конференциях содержат галлюцинированные цитаты, обходящие рецензию. CiteAudit предлагает открытый бенчмарк из 6475 реальных и 2967 фейковых ссылок, где пять ИИ-агентов достигают 97,2% точности на практике. Инструмент работает локально, бесплатно доступен онлайн и превосходит коммерческие модели.