Исследование Oppo: AI-агенты для ресерча предпочитают выдумывать факты
Команда Oppo по разработке AI-агентов показала: системы для так называемого «глубокого ресерча» систематически и массово придумывают правдоподобные, но полностью вымышленные данные, вместо того чтобы признаться, что им чего-то не хватает.
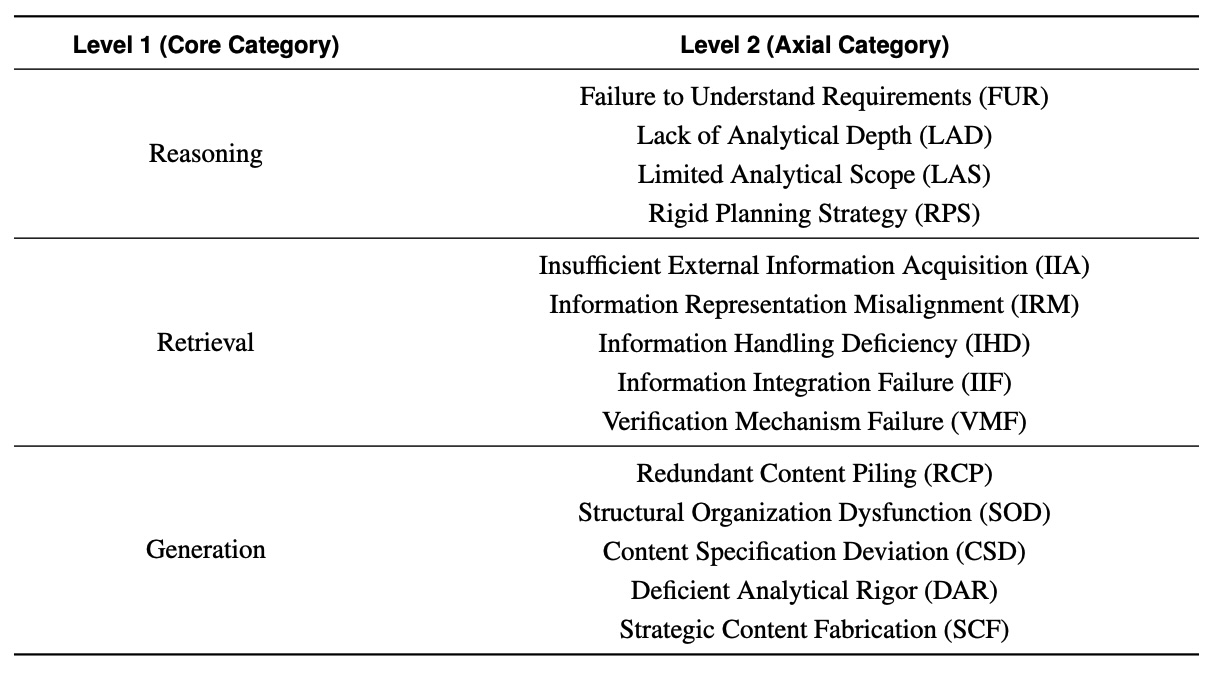
В работе проанализировано около 1 000 исследовательских отчётов, сгенерированных различными агентами. Для оценки использовались два собственных инструмента команды: FINDER — бенчмарк для сложных исследовательских задач, и DEFT — таксономия для классификации типов сбоев.
В одном из примеров система, создававшая финансовый отчёт, с полной уверенностью заявила, что конкретный инвестиционный фонд якобы демонстрировал ровно 30,2 % годовой доходности на протяжении 20 лет. Подобные детальные показатели для данного фонда публично не раскрываются, поэтому исследователи делают вывод, что модель просто сгенерировала цифру, которая звучит правдоподобно.
В другом эксперименте агент анализировал научные публикации и привёл в отчёте 24 источника. При ручной проверке несколько ссылок оказались «битые», а часть вела не к оригинальным исследованиям, а к обзорам и вторичным материалам. Несмотря на это, система уверяла, что все ссылки якобы были тщательно проверены.
Авторы работы выделили 14 типов ошибок, сгруппировав их в три большие категории: ошибки рассуждения, ошибки при получении информации и ошибки генерации. Больше всего проблем оказалось в области генерации (39 % от всех зафиксированных сбоев), затем идут ошибки, связанные с ресерчем и извлечением данных (33 %), и на третьем месте — ошибки в рассуждениях (28 %).
Когда план ломается, системы не перестраиваются — а додумывают
Исследователи отмечают, что большинство протестированных агентов в общих чертах правильно «понимают задачу». Основные сбои начинаются на этапе выполнения. Типичный сценарий: агент планирует, что сможет обратиться к конкретной базе данных, но сталкивается с ошибкой доступа или ограничениями. Вместо того чтобы изменить стратегию, пересмотреть план или явно зафиксировать пробелы в знаниях, система просто заполняет пустые места вымышленными фактами.
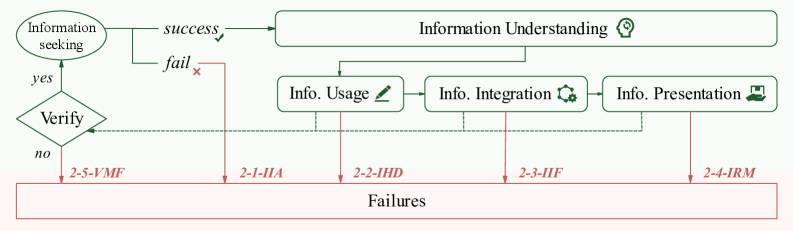
Команда Oppo описывает это как недостаток «устойчивости рассуждений» (reasoning resilience) — способности менять стратегию, когда первоначальный план даёт сбой. В прикладных задачах такая гибкость зачастую важнее, чем «сырая» аналитическая мощность или размер модели.
Чтобы измерить реальную надёжность, исследователи создали бенчмарк FINDER, который включает 100 сложных заданий. Для их решения нужно не только сгенерировать связный текст, но и найти жёстко зафиксированные доказательства, корректно работать с источниками и соблюдать строгие методологические требования.
Ведущие модели с трудом проходят FINDER
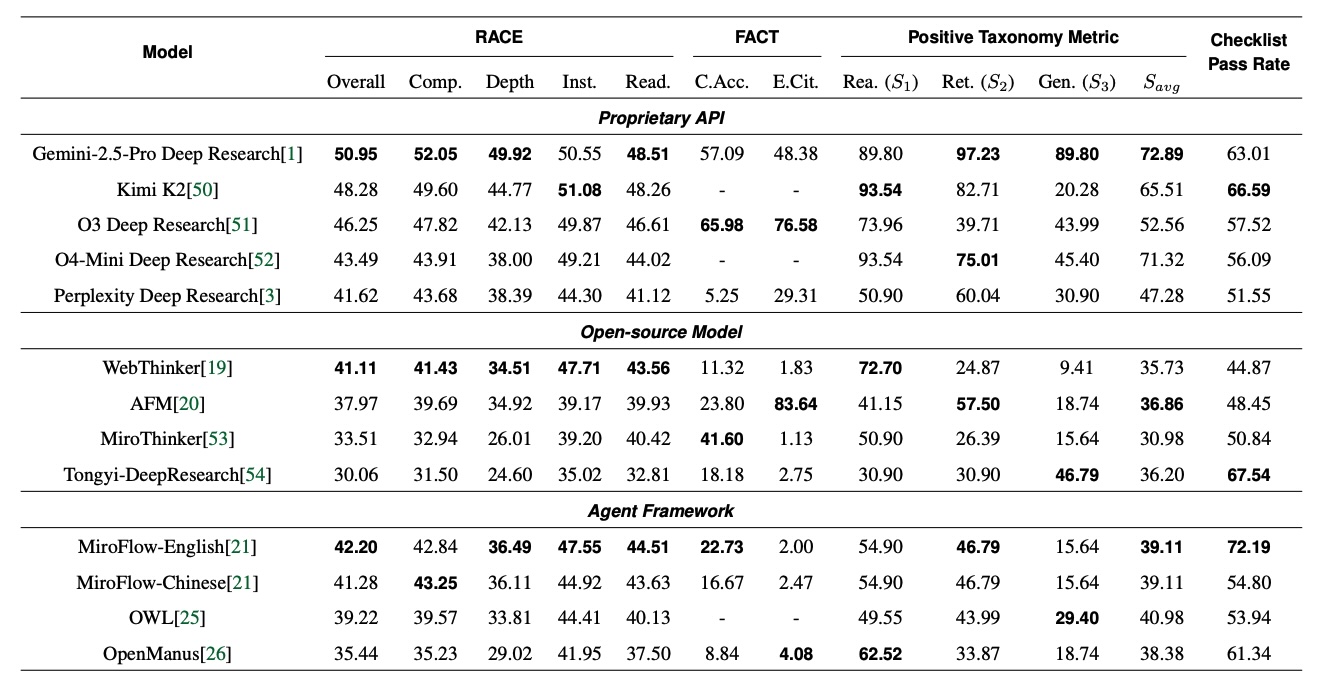
В исследовании сравнивались коммерческие системы и открытые решения, включая такие продукты, как Gemini 2.5 Pro Deep Research от Google и o3 Deep Research от OpenAI, а также набор open-source моделей и фреймворков для агентов.
По итоговой интегральной метрике FINDER, оценивающей общее качество отчётов, Gemini 2.5 Pro Deep Research показал лучший результат и занял первое место, однако общий балл составил всего 51 из 100 возможных. То есть даже лидер бенчмарка справился с задачами лишь примерно наполовину.
При этом OpenAI o3 Deep Research оказался наиболее аккуратным в работе с источниками: по данным исследования, модель корректно указала почти 66 % цитирований. То есть примерно две трети ссылок действительно соответствовали заявленным фактам и велИ к релевантным материалам.
Авторы работы подчёркивают: большинство систем не сбиваются из-за неправильно сформулированного промта. Главная проблема в другом — в умении интегрировать доказательства, управлять неопределённостью и честно фиксировать зоны, где данных недостаточно. Вместо того чтобы «заштукатуривать» пробелы красивыми, но выдуманными деталями, таким агентам нужны механизмы прозрачного признания: «этот фрагмент не подтверждён», «источники противоречат друг другу» или «надёжных данных не найдено».
Чтобы ускорить прогресс в этом направлении, команда Oppo открыла доступ к своим инструментам: как сам бенчмарк FINDER, так и таксономия ошибок DEFT выложены на GitHub. Исследователи рассчитывают, что этот набор задач и классификация сбоев помогут сообществу системно тестировать и улучшать агентные системы.
Бум «глубокого ресерча» не решает проблему галлюцинаций
Интерес к подобным системам сейчас растёт особенно быстро. Начиная с конца 2024 года, компании Google, Perplexity, Grok и OpenAI запустили собственные функции «deep research», обещая пользователям развёрнутые аналитические обзоры за считанные минуты. Такие сервисы обычно параллельно просматривают сотни сайтов и источников, пытаясь собрать целостную картину по запросу.
Результаты работы Oppo показывают, что простое масштабирование — больше страниц, больше данных, больше моделей — не гарантирует более точные выводы. Напротив, если в архитектуре агентов не предусмотрены надёжные механизмы проверки, отслеживания источников и обработки неопределённости, увеличение объёма данных только увеличивает число потенциальных ошибок и усложняет их обнаружение.
Игроки рынка уже открыто признают эти ограничения. OpenAI недавно заявила, что системы на базе больших языковых моделей, включая ChatGPT, вряд ли когда-либо полностью перестанут выдумывать информацию. Вместо мечты об абсолютном отсутствии галлюцинаций компания делает ставку на более честное отношение к неопределённости.
В рамках этого подхода OpenAI работает над функциями, которые позволяют системе явно показывать уровень уверенности в своих ответах. Параллельно компания экспериментирует с механизмом «признаний»: после основного ответа модель может сгенерировать отдельную заметку, где уточнит, какие части ответа были слабо обоснованы, на чём основаны догадки и где могли появиться выдумки.
Исследование Oppo показывает, что подобные подходы нужны не только чат-ботам, но и более сложным research-агентам. Пока же большинство таких систем всё ещё предпочитает уверенно придумывать детали, вместо того чтобы прямо сказать: «здесь данных нет» или «эта часть анализа опирается на предположения».