Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Исследователи из Принстона создали ИИ-систему, которая самостоятельно проектирует радиочастотные интегральные схемы (RFIC) без шаблонов, достигая рекордных характеристик. Используя обучение с подкреплением и диффузионные модели, алгоритм генерирует нестандартные, но эффективные топологии за считанные минуты, преодолевая ограничения традиционного «искусства» проектирования.
Стартап XDOF вышел из скрытого режима с финансированием $70 млн, чтобы решить проблему нехватки данных для обучения роботов. Компания строит инфраструктуру сбора и аннотирования данных и уже сотрудничает с 20 клиентами, включая ведущие ИИ-лаборатории. XDOF также представила датасет ABC — крупнейшую открытую подборку данных для роботов.
Clarifai удалила 3 миллиона фото от OkCupid, использованных для обучения ИИ распознавания лиц, после расследования FTC. Данные передали в 2014 году вопреки политике конфиденциальности, расследование запустила статья NYT в 2019-м. FTC заключила соглашение с OkCupid и Match Group, запретив misrepresentation данных.
Компания Micro1 нанимает тысячи фрилансеров в 50+ странах для записи видео бытовых дел, которые обучают гуманоидных роботов манипулировать предметами. Работа приносит хороший доход локально, но вызывает вопросы приватности, согласия и качества данных. В 2025 году инвесторы вложили свыше 6 млрд долларов в такие роботы, спрос на данные превышает 100 млн долларов ежегодно.
Google применил модель Gemini для анализа миллионов новостей и создания датасета Groundsource о вспышковых наводнениях. На его основе обучили LSTM-модель, которая теперь прогнозирует риски в 150 странах через Flood Hub. Подход решает проблему нехватки данных в бедных регионах и может расшириться на другие угрозы.
OpenAI разработала датасет IH-Challenge, обучающий ИИ-модели строгой иерархии инструкций: системные выше разработческих, пользовательских и от инструментов. Это повышает безопасность и защиту от внедрения промтов, особенно через инструменты. Датасет доступен на Hugging Face для дальнейших экспериментов.
Специалисты из Apple, Stanford и Вашингтонского университета обнаружили, что экстракторы HTML вроде Resiliparse, Trafilatura и JusText пропускают разные участки веба — общие всего 39% страниц. Их объединение увеличивает токены на 71%, радикально улучшая таблицы и код. Это заставит пересмотреть подготовку данных для ИИ-моделей.
SMOTE помогает справляться с дисбалансом классов в машинном обучении, генерируя синтетические примеры для редких классов. Многие допускают ошибки вроде применения метода до разделения данных или чрезмерной балансировки. Правильный подход через Pipeline в Python и фокус на релевантных метриках обеспечивает надежные модели.
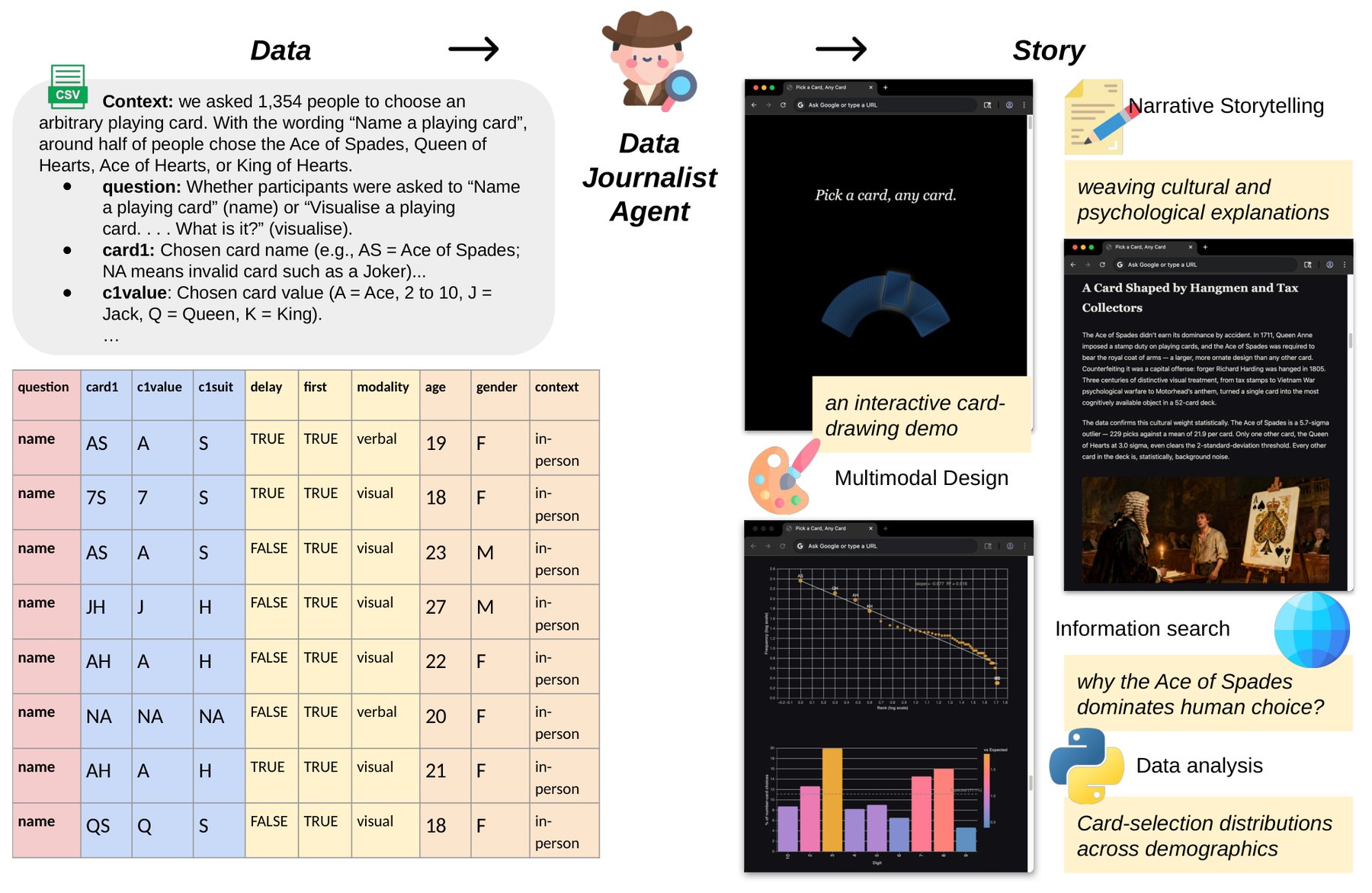
Data2Story — система из семи ИИ-агентов, автоматически создающая интерактивные мультимодальные статьи из CSV-файлов. Она обеспечивает высокую проверяемость утверждений, связывая каждое с кодом или источником. В тестах с читателями статьи агента получили более высокие оценки, чем написанные людьми.
DAIMON Robotics выпустила Daimon-Infinity — крупнейший омнимодальный датасет для воплощенного ИИ с тактильными данными высокого разрешения из 80+ сценариев и 2000+ навыков. Компания открыла 10 тысяч часов данных с партнерами вроде Google DeepMind для ускорения робототехники. Проект опирается на VTLA-архитектуру и сенсоры с 110 тысячами элементов для ловких манипуляций.
Бенчмарк RealChart2Code протестировал 14 ИИ-моделей на сложных графиках из реальных данных Kaggle: даже лидеры вроде Claude 4.5 Opus и Gemini 3 Pro Preview теряют до половины производительности. Открытые модели страдают от галлюцинаций библиотек и ошибок layouts, закрытые — от неправильного назначения данных. Бенчмарк доступен на GitHub и Hugging Face.
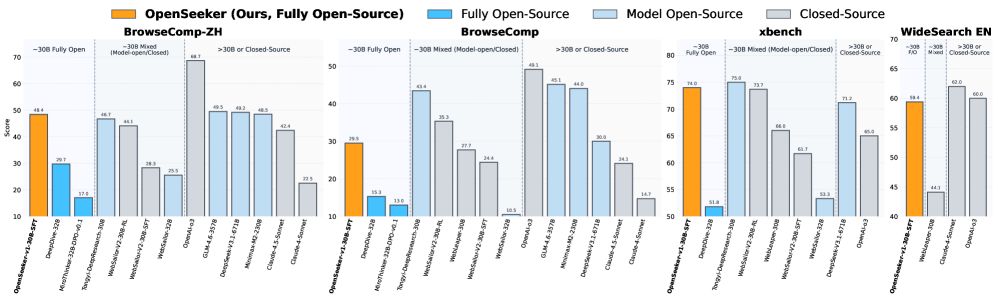
ИИ-агент OpenSeeker от ученых Шанхайского университета Цзяотун достигает результатов Alibaba с 11 700 точек данных и одной тренировкой. Модель обходит другие открытые аналоги на бенчмарках BrowseComp, все ресурсы — данные, код, веса — публичны. Это разрушает монополию больших компаний на данные для поиска.
Ai2 представила открытый набор моделей MolmoBot для робототехники, обученных на 1,8 млн синтетических траекторий из симуляций MuJoCo. Модели достигают 79,2% успеха в реальных задачах без дообучения, обходя ручной сбор данных. Такой подход ускоряет исследования и снижает затраты.
Ученые создали крупнейший датасет VBVR для видео-рассуждений с миллионами примеров; тесты показали, что Sora 2 набирает лишь 0,546 от человеческого уровня 0,974, а Veo 3.1 — 0,480. Дообученная Wan2.2 обошла закрытые модели, но на новых задачах уперлась в потолок — нужны изменения архитектуры.
Ансамбли XGBoost доминируют на табличных данных благодаря точности и скорости. Семь приёмов на Python улучшают модели: настройка learning_rate с n_estimators, ограничение max_depth, subsample, регуляризация, раннее останавливание, GridSearchCV и scale_pos_weight для дисбаланса. Примеры даны на датасете Breast Cancer из scikit-learn.
Семь практичных приемов на Python помогают в exploratory data analysis находить пропуски, выбросы, дубликаты и другие дефекты данных. На примере датасета сотрудников с искусственными ошибками показаны тепловые карты, IQR, лог-трансформы и корреляции. Методы сохраняют все детали и готовы к использованию в коде.