
Введение
Размеченные данные с истинными метками целей необходимы для создания большинства моделей машинного обучения с учителем, таких как случайный лес, логистическая регрессия или классификаторы на базе нейронных сетей. Хотя главная трудность в реальных задачах часто связана с сбором достаточного объема таких данных, иногда даже после этого решения возникает другая серьезная проблема: дисбаланс классов.
Дисбаланс классов возникает, когда в размеченном наборе данных классы сильно различаются по количеству примеров, и один или несколько из них представлены в минимальном объеме. Это создает сложности при обучении модели машинного обучения. Другими словами, обучение предиктивной модели, например классификатора, на несбалансированных данных приводит к смещенным границам решений, низкому recall для миноритарного класса и завышенной точности, которая выглядит хорошо на бумаге, но на практике модель подводит в ключевых ситуациях. Яркий пример — обнаружение мошенничества в банковских транзакциях, где около 99% операций честные, что делает наборы данных крайне несбалансированными.
Что такое SMOTE и как это работает
SMOTE — это метод аугментации данных для решения проблем дисбаланса классов в машинном обучении, особенно для моделей с учителем вроде классификаторов. Если хотя бы один класс сильно недопредставлен по сравнению с остальными, модель склонна отдавать предпочтение мажоритарному классу, что ухудшает результаты, в первую очередь для редкого класса.
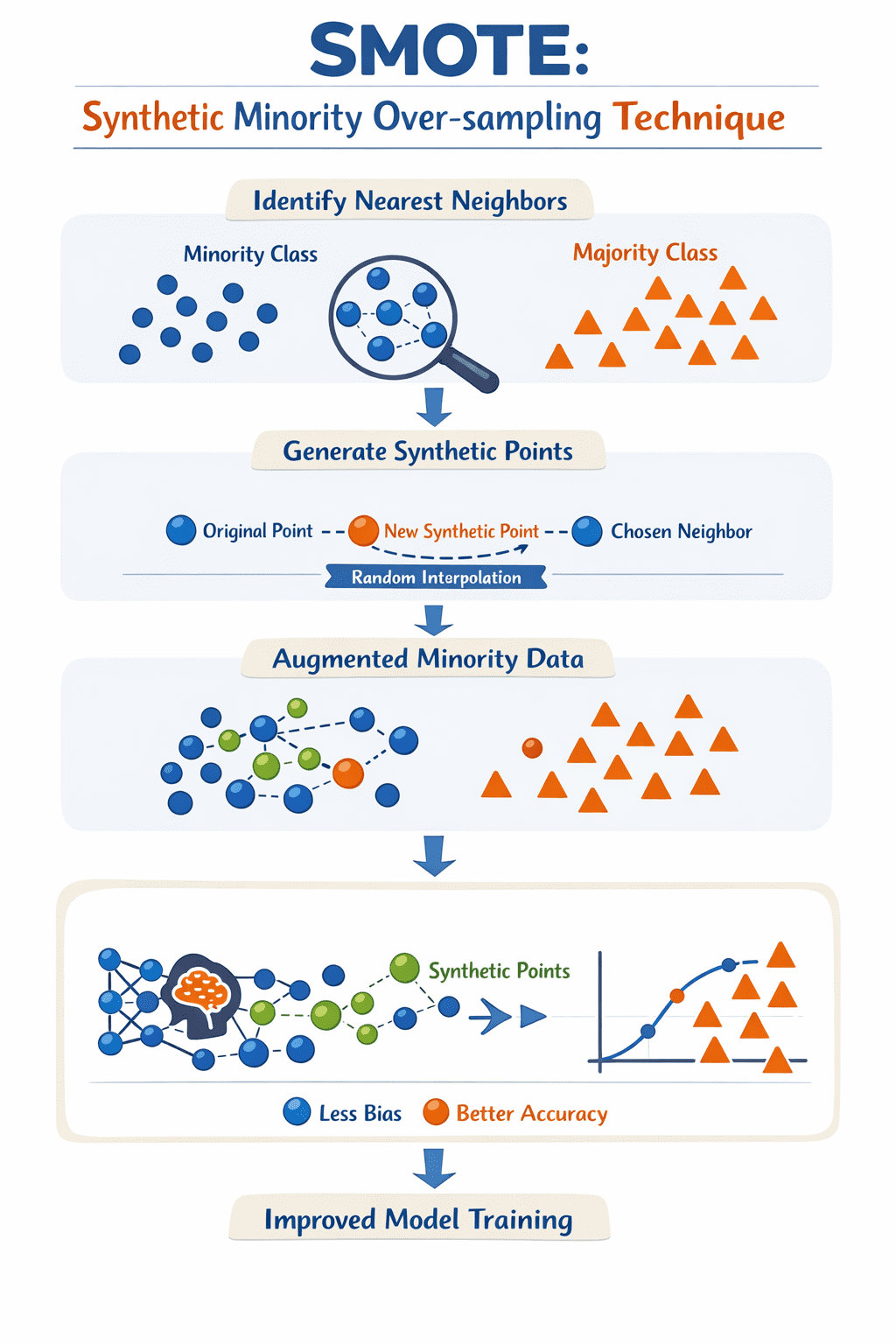
Чтобы преодолеть эту проблему, SMOTE генерирует синтетические примеры для миноритарного класса. Вместо простого копирования существующих экземпляров метод интерполирует между образцом миноритарного класса и его ближайшими соседями в пространстве признаков. По сути, это заполняет пробелы в областях вокруг реальных примеров миноритарного класса, помогая сбалансировать набор данных.
Алгоритм проходит по каждому примеру миноритарного класса, находит k ближайших соседей и создает новый синтетический пункт на прямой между образцом и случайно выбранным соседом. В итоге после итераций получается расширенный набор примеров миноритарного класса, на основе которого обучение модели проходит с более полным представлением миноритарных классов, что дает менее предвзятую и эффективную модель.
Правильная реализация SMOTE в Python
Чтобы избежать утечки данных, лучше всего применять SMOTE через конвейер. Библиотека imbalanced-learn предлагает специальный объект Pipeline, который гарантирует использование SMOTE только на обучающих данных во время каждого фолда кросс-валидации или при простом разделении на train/test, оставляя тестовый набор нетронутым и отражающим реальные условия.
Вот пример интеграции SMOTE в рабочий процесс машинного обучения с помощью scikit-learn и imblearn:
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# Split data into training and testing sets first
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Define the pipeline: Resampling then modeling
# The imblearn Pipeline only applies SMOTE to the training data
pipeline = Pipeline([
('smote', SMOTE(random_state=42)),
('classifier', RandomForestClassifier(random_state=42))
])
# Fit the pipeline on training data
pipeline.fit(X_train, y_train)
# Evaluate on the untouched test data
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred))
Использование Pipeline гарантирует, что трансформация применяется только в контексте обучения. Это предотвращает попадание синтетических данных в набор оценки, обеспечивая реалистичную проверку работы модели с дисбалансом в продакшене.
Распространенные ошибки при использовании SMOTE
Рассмотрим три типичных случая неправильного применения SMOTE в процессах машинного обучения и способы их избежать:
- Применение SMOTE до разделения данных на обучающую и тестовую выборки: Это частая оплошность, особенно у начинающих специалистов, которая обычно происходит случайно. SMOTE создает синтетические примеры на основе всех доступных данных, и если они попадают в будущие train и test, метрики оценки искусственно завышаются. Правильно: сначала разделить данные, потом применить SMOTE только к обучающей части. Планируете k-fold кросс-валидацию? Еще лучше.
- Чрезмерная балансировка: Глупо стремиться к идеальному равенству пропорций классов. В реальности это часто излишне и вредно, особенно в многоклассовых наборах с несколькими редкими классами. SMOTE может генерировать примеры за границами реальных данных или в пустых зонах, добавляя шум и провоцируя переобучение. Лучше действовать осторожно: повышайте долю миноритарных классов постепенно и проверяйте модель.
- Игнорирование контекста метрик и моделей: Общая точность — простая метрика, но она обманчива и не показывает слабостей в распознавании миноритарного класса. Это критично в сферах вроде банковского дела или медицины, например при поиске редких болезней. SMOTE улучшает recall, но может ухудшить precision из-за шумных синтетических сэмплов, что противоречит бизнес-целям. Оценивайте по recall, F1-score, коэффициенту корреляции Мэттьюза (MCC, обобщение матрицы ошибок) или площади под кривой precision-recall (PR-AUC). Также комбинируйте с весами классов или настройкой порога для лучшего эффекта.
Заключение
Статья посвященная SMOTE — популярному методу борьбы с дисбалансом классов при создании классификаторов машинного обучения на реальных данных. Выявлены типичные ошибки использования и даны рекомендации по их избежанию.