
Введение
Исследовательский анализ данных, или EDA, помогает подготовить почву для серьезного анализа или создания ИИ-систем на базе моделей машинного обучения. Проблемы с качеством данных вроде несоответствий часто решают позже в пайплайне, но на этапе EDA проще всего их заметить заранее. Так можно избежать скрытых искажений, падения точности моделей и ошибок в решениях.
Здесь собраны 7 приемов на Python, которые упрощают поиск и устранение разных дефектов данных на ранних шагах EDA. Для демонстрации используется набор данных о сотрудниках с специально добавленными проблемами. Перед тестами вставьте этот начальный код в среду разработки:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# PREAMBLE CODE THAT RANDOMLY CREATES A DATASET AND INTRODUCES QUALITY ISSUES IN IT
np.random.seed(42)
n = 1000
df = pd.DataFrame({
"age": np.random.normal(40, 12, n).round(),
"income": np.random.normal(60000, 15000, n),
"experience_years": np.random.normal(10, 5, n),
"department": np.random.choice([
"Sales", "Engineering", "HR", "sales", "Eng", "HR "
], n),
"performance_score": np.random.normal(3, 0.7, n)
})
# Randomly injecting data issues to the dataset
# 1. Missing values
df.loc[np.random.choice(n, 80, replace=False), "income"] = np.nan
df.loc[np.random.choice(n, 50, replace=False), "department"] = np.nan
# 2. Outliers
df.loc[np.random.choice(n, 10), "income"] *= 5
df.loc[np.random.choice(n, 10), "age"] = -5
# 3. Invalid values
df.loc[np.random.choice(n, 15), "performance_score"] = 7
# 4. Skewness
df["bonus"] = np.random.exponential(2000, n)
# 5. Highly correlated features
df["income_copy"] = df["income"] * 1.02
# 6. Duplicated entries
df = pd.concat([df, df.iloc[:20]], ignore_index=True)
df.head()1. Поиск пропусков с помощью тепловых карт
В библиотеках вроде Pandas есть способы посчитать пропуски по столбцам, но тепловая карта через isnull() дает мгновенный обзор. Белые полосы вроде штрих-кода отметят каждый пропуск, распределенные по атрибутам горизонтально.
plt.figure(figsize=(10, 5))
sns.heatmap(df.isnull(), cbar=False)
plt.title("Missing Value Heatmap")
plt.show()
df.isnull().sum().sort_values(ascending=False)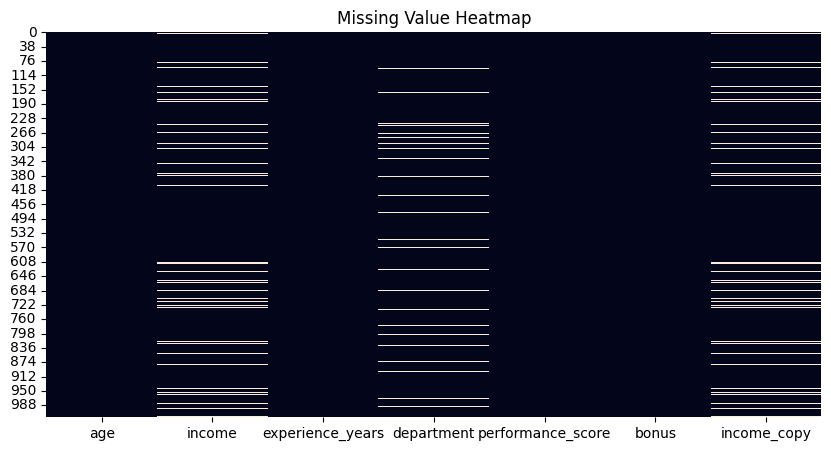
2. Удаление дубликатов
Простой и надежный способ: посчитать дубликаты строк через duplicated(), а потом убрать их с помощью drop_duplicates(). По умолчанию остается первая копия, остальные удаляются. Можно выбрать keep="last" для последней или keep=False, чтобы стереть все копии. Выбор зависит от задачи.
duplicate_count = df.duplicated().sum()
print(f"Number of duplicate rows: {duplicate_count}")
# Remove duplicates
df = df.drop_duplicates()3. Выбросы по методу межквартильного размаха
Метод IQR на основе статистики находит точки, сильно отстоящие от остальных, — потенциальные выбросы. Вот функция для числовых столбцов вроде "income":
def detect_outliers_iqr(data, column):
Q1 = data[column].quantile(0.25)
Q3 = data[column].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
return data[(data[column] < lower) | (data[column] > upper)]
outliers_income = detect_outliers_iqr(df, "income")
print(f"Income outliers: {len(outliers_income)}")
# Optional: cap them
Q1 = df["income"].quantile(0.25)
Q3 = df["income"].quantile(0.75)
IQR = Q3 - Q1
lower = Q1 - 1.5 * IQR
upper = Q3 + 1.5 * IQR
df["income"] = df["income"].clip(lower, upper)4. Работа с несогласованными категориями
В отличие от выбросов в числах, проблемы с категориями возникают из-за ручных ошибок вроде разного регистра или вариаций в названиях. Нужно знание предметной области, чтобы выбрать правильные категории. Пример — приведение названий отделов к единому виду.
print("Before cleaning:")
print(df["department"].value_counts(dropna=False))
df["department"] = (
df["department"]
.str.strip()
.str.lower()
.replace({
"eng": "engineering",
"sales": "sales",
"hr " : "hr"
})
)
print("\nAfter cleaning:")
print(df["department"].value_counts(dropna=False))5. Проверка и валидация диапазонов
Выбросы — это статистические аномалии, а недопустимые значения нарушают правила домена, например возраст не бывает отрицательным. Здесь отрицательные возраста заменяются на NaN — дальше их обработают как пропуски.
invalid_age = df[df["age"] < 0]
print(f"Invalid ages: {len(invalid_age)}")
# Fix by setting to NaN
df.loc[df["age"] < 0, "age"] = np.nan6. Логарифмическое преобразование для скошенных данных
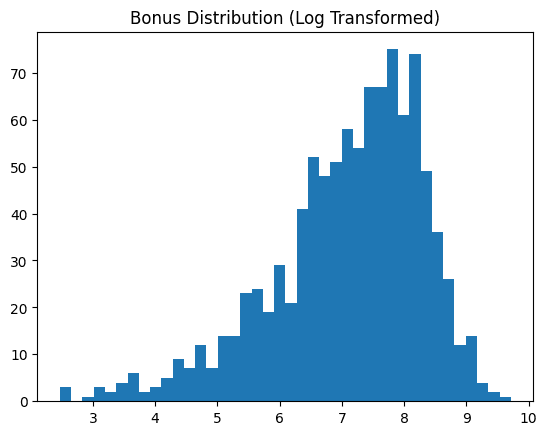
Скошенные признаки вроде "bonus" лучше привести к форме, близкой к нормальному распределению — это упрощает анализ для машинного обучения. Пример с логарифмом показывает распределение до и после.
skewness = df["bonus"].skew()
print(f"Bonus skewness: {skewness:.2f}")
plt.hist(df["bonus"], bins=40)
plt.title("Bonus Distribution (Original)")
plt.show()
# Log transform
df["bonus_log"] = np.log1p(df["bonus"])
plt.hist(df["bonus_log"], bins=40)
plt.title("Bonus Distribution (Log Transformed)")
plt.show()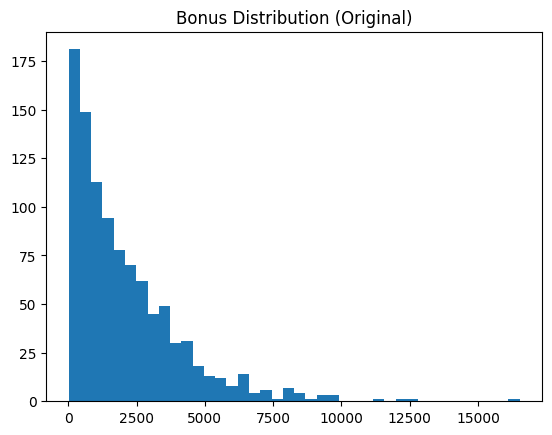
7. Избыточные признаки через матрицу корреляций
Завершаем визуализацией: тепловая карта корреляций быстро покажет пары признаков с высокой связью — признак избыточности, которую стоит сократить. Приводятся топ-5 пар для ясности.
corr_matrix = df.corr(numeric_only=True)
plt.figure(figsize=(10, 6))
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap="coolwarm")
plt.title("Correlation Matrix")
plt.show()
# Find high correlations
high_corr = (
corr_matrix
.abs()
.unstack()
.sort_values(ascending=False)
)
high_corr = high_corr[high_corr < 1]
print(high_corr.head(5))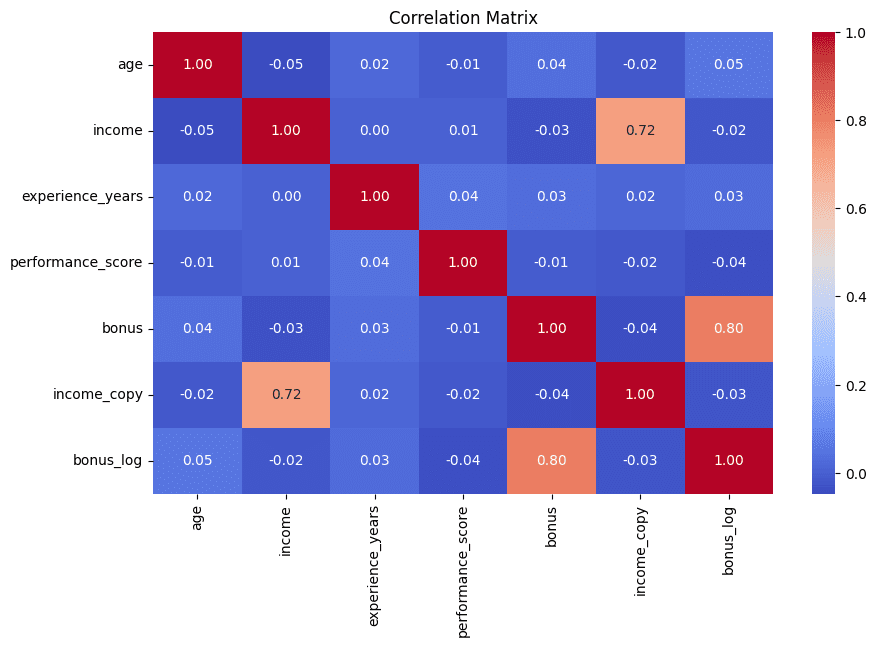
Итог
Эти 7 приемов усиливают EDA, позволяя легко находить и исправлять разные проблемы качества данных интуитивно и эффективно.