Будущее агентов на базе ИИ предполагает, что модели смогут эффективно взаимодействовать с сотнями или тысячами инструментов. Представьте помощника в среде разработки, который управляет операциями с Git, манипулирует файлами, работает с менеджерами пакетов, фреймворками для тестирования и конвейерами развертывания. Или координатора операций, который связывает Slack, GitHub, Google Drive, Jira, корпоративные базы данных и десятки серверов MCP одновременно.
Чтобы создавать эффективных агентов, им требуется доступ к неограниченным библиотекам инструментов без необходимости загружать все определения в контекст заранее. В нашей статье о использовании выполнения кода с MCP мы объясняли, как результаты инструментов и их определения иногда занимают более 50 000 токенов еще до того, как агент получит запрос. Агенты должны находить и загружать инструменты по мере необходимости, сохраняя в контексте только то, что актуально для текущей задачи.
Агентам также нужно вызывать инструменты из кода. При использовании вызова инструментов на естественном языке каждый запуск требует полного прохода инференса, а промежуточные результаты накапливаются в контексте, даже если они бесполезны. Код идеально подходит для логики оркестрации, такой как циклы, условия и преобразования данных. Агентам требуется гибкость в выборе между выполнением кода и инференсом в зависимости от задачи.
Кроме того, агентам нужно учиться правильному использованию инструментов на примерах, а не только по схемам определений. Схемы JSON определяют, что структурно верно, но не могут передать шаблоны использования: когда добавлять необязательные параметры, какие комбинации логичны или какие соглашения ожидает ваш API.
Сегодня мы представляем три функции, которые делают это реальностью:
- Инструмент поиска инструментов, который позволяет Claude использовать поисковые инструменты для доступа к тысячам инструментов без нагрузки на окно контекста.
- Программный вызов инструментов, который дает Claude возможность вызывать инструменты в среде выполнения кода, минимизируя влияние на окно контекста модели.
- Примеры использования инструментов, которые устанавливают универсальный стандарт для демонстрации эффективного применения конкретного инструмента.
В наших внутренних тестах эти функции помогли создать решения, которые были невозможны с традиционными подходами к инструментам. Например, Claude для Excel применяет программный вызов инструментов для чтения и изменения таблиц с тысячами строк без перегрузки окна контекста модели.
На основе нашего опыта мы уверены, что эти функции открывают новые горизонты для разработок на базе Claude.
Инструмент поиска инструментов
Проблема
Определения инструментов MCP дают важный контекст, но с ростом числа подключенных серверов токены быстро накапливаются. Возьмем конфигурацию из пяти серверов:
- GitHub: 35 инструментов (~26K токенов)
- Slack: 11 инструментов (~21K токенов)
- Sentry: 5 инструментов (~3K токенов)
- Grafana: 5 инструментов (~3K токенов)
- Splunk: 2 инструмента (~2K токенов)
Это 58 инструментов, которые тратят около 55K токенов еще до начала разговора. Добавьте сервер вроде Jira (сам по себе ~17K токенов), и вы приближаетесь к 100K+ токенам overhead. В Anthropic мы видели случаи, когда определения инструментов съедали 134K токенов до оптимизации.
Но токены — не единственная проблема. Чаще всего ошибаются в выборе инструмента и параметрах, особенно когда имена похожи, как notification-send-user против notification-send-channel.
Решение
Вместо загрузки всех определений заранее инструмент поиска инструментов находит их по требованию. Claude видит только те инструменты, которые действительно нужны для задачи.
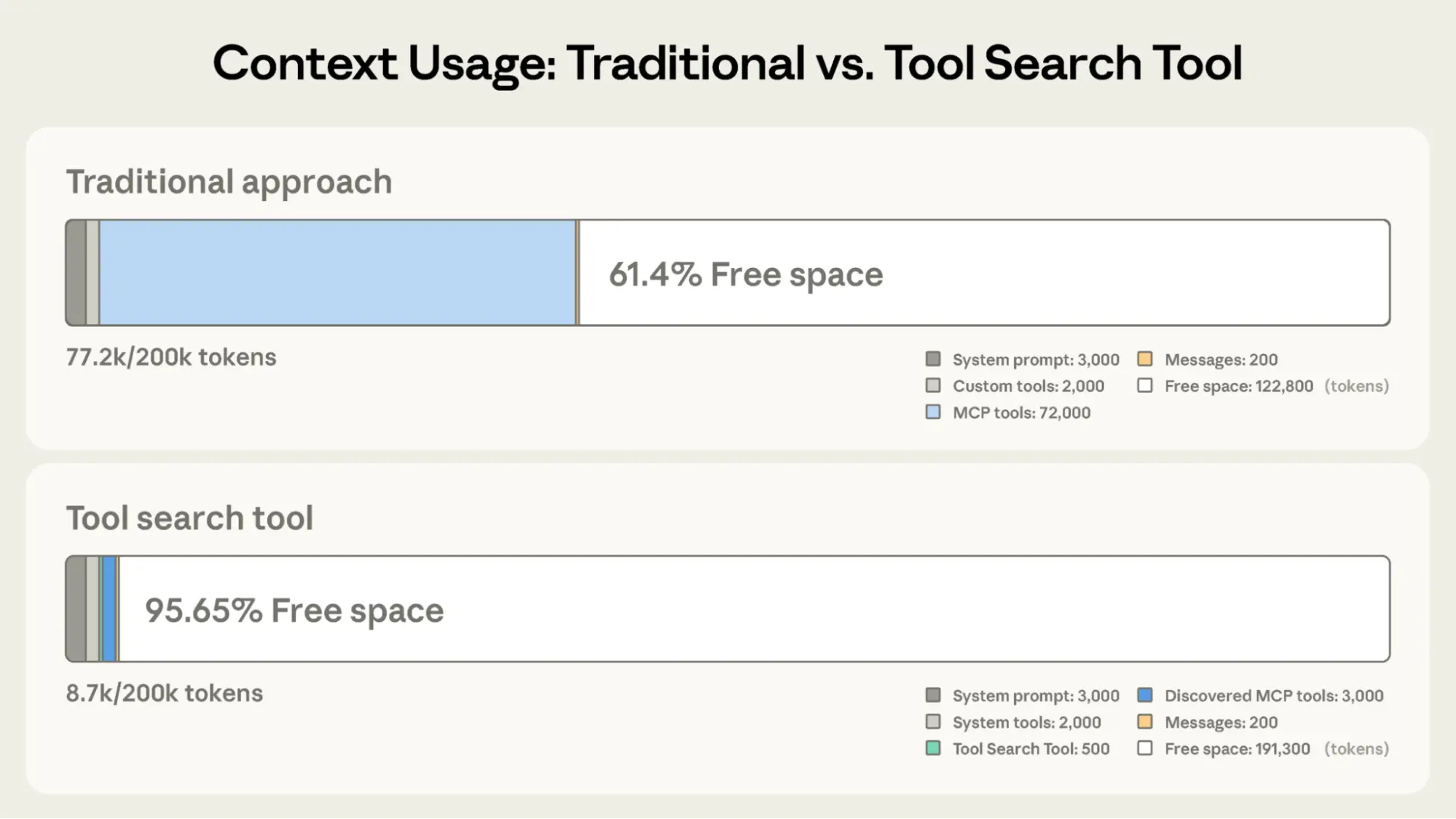
Традиционный подход:
- Все определения инструментов загружаются заранее (~72K токенов для 50+ инструментов MCP)
- История разговора и системный промт конкурируют за оставшееся место
- Общее потребление контекста: ~77K токенов до начала работы
С инструментом поиска инструментов:
- Загружается только сам инструмент поиска (~500 токенов)
- Инструменты обнаруживаются по мере необходимости (3-5 релевантных, ~3K токенов)
- Общее потребление контекста: ~8.7K токенов, что сохраняет 95% окна контекста
Это дает сокращение использования токенов на 85%, при сохранении доступа ко всей библиотеке инструментов. Внутренние тесты показали заметный рост точности на оценках MCP при работе с большими библиотеками инструментов. Opus 4 улучшился с 49% до 74%, а Opus 4.5 — с 79.5% до 88.1% при включенном инструменте поиска.
Как работает инструмент поиска инструментов
Инструмент поиска инструментов позволяет Claude динамически находить инструменты вместо загрузки всех определений заранее. Вы предоставляете все определения инструментов в API, но помечаете их defer_loading: true, чтобы они становились доступны по требованию. Отложенные инструменты не попадают в контекст Claude изначально. Claude видит только сам инструмент поиска и любые инструменты с defer_loading: false (ваши ключевые, часто используемые инструменты).
Когда Claude требует конкретных возможностей, он ищет подходящие инструменты. Инструмент поиска возвращает ссылки на совпадающие инструменты, которые расширяются в полные определения в контексте Claude.
Например, если Claude нужно взаимодействовать с GitHub, он ищет "github", и загружаются только github.createPullRequest и github.listIssues — не остальные 50+ инструментов из Slack, Jira и Google Drive.
Таким образом, Claude имеет доступ ко всей библиотеке, но платит токенами только за нужные инструменты.
Заметка о кэшировании промта: Инструмент поиска не нарушает кэширование промта, поскольку отложенные инструменты полностью исключены из начального промта. Они добавляются в контекст только после поиска, так что системный промт и основные определения инструментов остаются кэшируемыми.
Реализация:
{ "tools": [ // Включите инструмент поиска (regex, BM25 или кастомный) {"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"}, // Пометьте инструменты для обнаружения по требованию { "name": "github.createPullRequest", "description": "Create a pull request", "input_schema": {...}, "defer_loading": true } // ... сотни других отложенных инструментов с defer_loading: true ] }Для серверов MCP можно отложить загрузку целых серверов, сохраняя конкретные часто используемые инструменты загруженными:
{ "type": "mcp_toolset", "mcp_server_name": "google-drive", "default_config": {"defer_loading": true}, # отложить загрузку всего сервера "configs": { "search_files": { "defer_loading": false } // Сохранить наиболее используемый инструмент загруженным } }Платформа Claude Developer предоставляет инструменты поиска на базе regex и BM25 из коробки, но вы можете реализовать кастомные с использованием эмбеддингов или других методов.
Когда применять инструмент поиска инструментов
Как и любое архитектурное решение, включение инструмента поиска требует учета компромиссов. Функция добавляет шаг поиска перед вызовом инструмента, так что она окупается, когда экономия контекста и рост точности перевешивают дополнительную задержку.
Используйте, когда:
- Определения инструментов тратят >10K токенов
- Есть проблемы с точностью выбора инструментов
- Строите системы на MCP с несколькими серверами
- Доступно 10+ инструментов
Меньше пользы, когда:
- Маленькая библиотека инструментов (<10)
- Все инструменты используются часто в каждой сессии
- Определения инструментов компактны
Программный вызов инструментов
Проблема
Традиционный вызов инструментов создает две ключевые проблемы по мере усложнения рабочих процессов:
- Загрязнение контекста промежуточными результатами: Когда Claude анализирует лог-файл на 10 МБ для поиска шаблонов ошибок, весь файл попадает в окно контекста, хотя Claude нужен только обзор частоты ошибок. При получении данных клиентов из нескольких таблиц каждая запись накапливается в контексте независимо от релевантности. Эти промежуточные результаты тратят огромные бюджеты токенов и могут вытеснить важную информацию из окна контекста.
- Накладные расходы на инференс и ручной синтез: Каждый вызов инструмента требует полного прохода модели. После получения результатов Claude должен "осмотреть" данные, чтобы извлечь релевантное, подумать, как части соединяются, и решить следующий шаг — все через обработку естественного языка. Рабочий процесс из пяти инструментов значит пять проходов инференса плюс парсинг каждым результатом, сравнение значений и синтез выводов. Это медленно и склонно к ошибкам.
Решение
Программный вызов инструментов позволяет Claude оркестрировать инструменты через код, а не через отдельные круглые поездки в API. Вместо того чтобы Claude запрашивал инструменты по одному с возвратом каждого результата в контекст, Claude пишет код, который вызывает несколько инструментов, обрабатывает их выводы и контролирует, какая информация попадает в окно контекста.
Claude отлично пишет код, и позволяя выразить логику оркестрации на Python вместо вызовов инструментов на естественном языке, вы получаете более надежный и точный контроль потока. Циклы, условия, преобразования данных и обработка ошибок explicit в коде, а не implicit в рассуждениях Claude.
Пример: Проверка соответствия бюджету
Рассмотрим типичную бизнес-задачу: "Какие члены команды превысили бюджет на поездки в третьем квартале?"
Доступны три инструмента:
get_team_members(department)— Возвращает список членов команды с ID и уровнямиget_expenses(user_id, quarter)— Возвращает строки расходов для пользователяget_budget_by_level(level)— Возвращает лимиты бюджета для уровня сотрудника
Традиционный подход:
- Получить членов команды → 20 человек
- Для каждого получить расходы за Q3 → 20 вызовов инструментов, каждый возвращает 50-100 строк (рейсы, отели, еда, чеки)
- Получить лимиты бюджета по уровням сотрудников
- Все это попадает в контекст Claude: 2000+ строк расходов (50 КБ+)
- Claude вручную суммирует расходы каждого, смотрит бюджет, сравнивает расходы с лимитами
- Дополнительные круглые поездки к модели, значительное потребление контекста
С программным вызовом инструментов:
Вместо возврата каждого результата инструмента в Claude, Claude пишет скрипт на Python, который оркестрирует весь процесс. Скрипт запускается в инструменте выполнения кода (песочнице), приостанавливаясь при необходимости результатов от ваших инструментов. Когда вы возвращаете результаты инструментов через API, они обрабатываются скриптом, а не потребляются моделью. Скрипт продолжает выполнение, и Claude видит только финальный вывод.
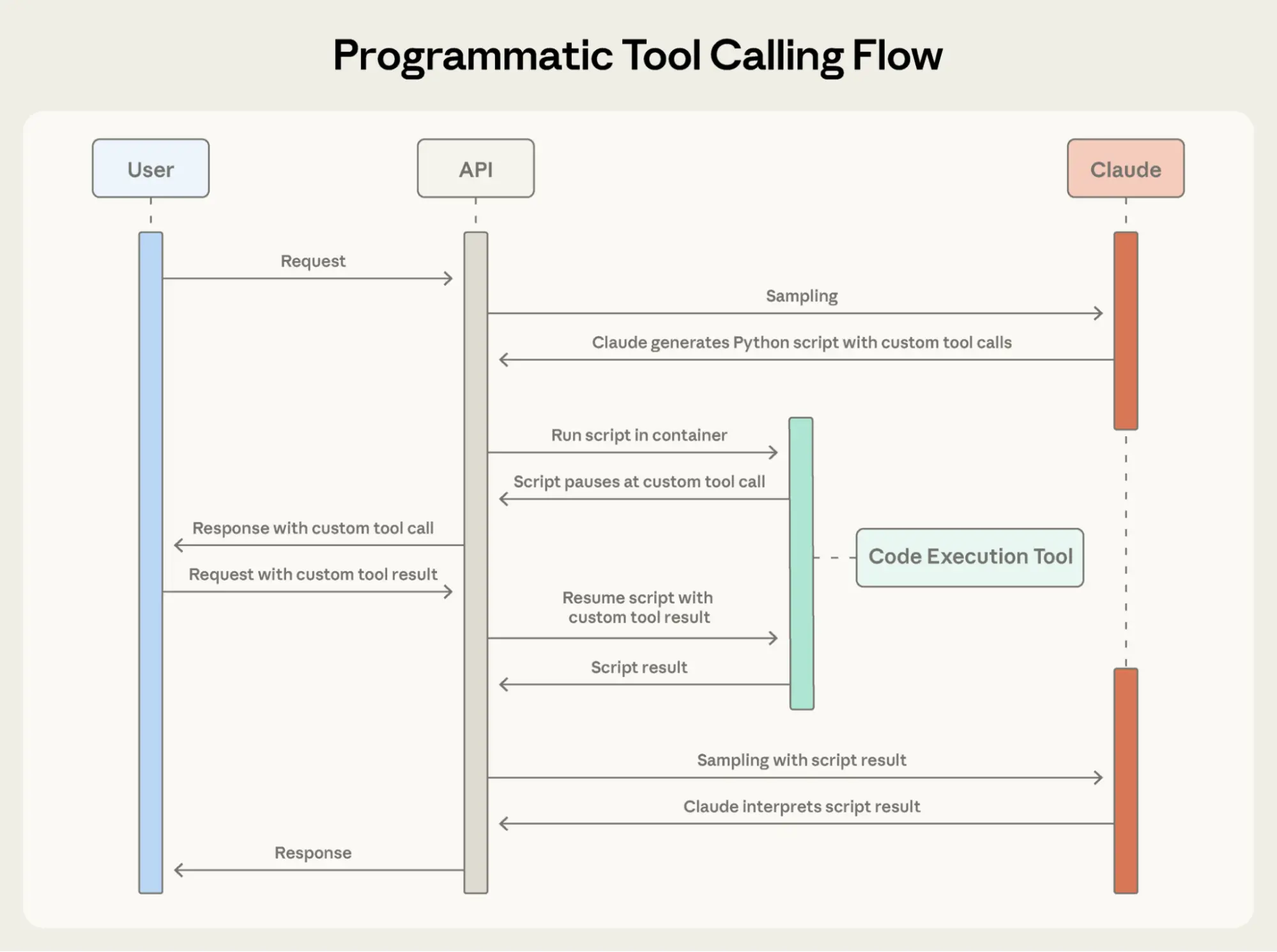
Вот как выглядит код оркестрации Claude для задачи проверки бюджета:
team = await get_team_members("engineering") # Fetch budgets for each unique level levels = list(set(m["level"] for m in team)) budget_results = await asyncio.gather(*[ get_budget_by_level(level) for level in levels ]) # Create a lookup dictionary: {"junior": budget1, "senior": budget2, ...} budgets = {level: budget for level, budget in zip(levels, budget_results)} # Fetch all expenses in parallel expenses = await asyncio.gather(*[ get_expenses(m["id"], "Q3") for m in team ]) # Find employees who exceeded their travel budget exceeded = [] for member, exp in zip(team, expenses): budget = budgets[member["level"]] total = sum(e["amount"] for e in exp) if total > budget["travel_limit"]: exceeded.append({ "name": member["name"], "spent": total, "limit": budget["travel_limit"] }) print(json.dumps(exceeded))В контекст Claude попадает только финальный результат: два-три человека, превысивших бюджет. 2000+ строк расходов, промежуточные суммы и запросы бюджетов не влияют на контекст Claude, снижая потребление с 200 КБ сырых данных расходов до 1 КБ результатов.
Эффективность растет существенно:
- Экономия токенов: Держа промежуточные результаты вне контекста Claude, программный вызов резко снижает потребление токенов. Среднее использование упало с 43 588 до 27 297 токенов, на 37% для сложных исследовательских задач.
- Снижение задержки: Каждая круглая поездка в API требует инференса модели (сотни миллисекунд до секунд). Когда Claude оркестрирует 20+ вызовов инструментов в одном блоке кода, вы избавляетесь от 19+ проходов инференса. API обрабатывает выполнение инструментов без возврата к модели каждый раз.
- Рост точности: Писать явную логику оркестрации позволяет Claude избегать ошибок при жонглировании несколькими результатами инструментов на естественном языке. Внутренний поиск знаний улучшился с 25.6% до 28.5%; бенчмарки GIA — с 46.5% до 51.2%.
Реальные рабочие процессы включают грязные данные, условную логику и операции, требующие масштаба. Программный вызов инструментов позволяет Claude справляться с этой сложностью программно, фокусируясь на actionable результатах вместо обработки сырых данных.
Как работает программный вызов инструментов
1. Пометьте инструменты как вызываемые из кода
Добавьте code_execution к инструментам и установите allowed_callers для инструментов, opted-in для программного выполнения:
{ "tools": [ { "type": "code_execution_20250825", "name": "code_execution" }, { "name": "get_team_members", "description": "Get all members of a department...", "input_schema": {...}, "allowed_callers": ["code_execution_20250825"] # opt-in to programmatic tool calling }, { "name": "get_expenses", ... }, { "name": "get_budget_by_level", ... } ] }API преобразует эти определения инструментов в функции Python, которые Claude может вызывать.
2. Claude пишет код оркестрации
Вместо запроса инструментов по одному Claude генерирует код на Python:
{ "type": "server_tool_use", "id": "srvtoolu_abc", "name": "code_execution", "input": { "code": "team = get_team_members('engineering')\n..." # the code example above } }3. Инструменты выполняются без попадания в контекст Claude
Когда код вызывает get_expenses(), вы получаете запрос инструмента с полем caller:
{ "type": "tool_use", "id": "toolu_xyz", "name": "get_expenses", "input": {"user_id": "emp_123", "quarter": "Q3"}, "caller": { "type": "code_execution_20250825", "tool_id": "srvtoolu_abc" } }Вы предоставляете результат, который обрабатывается в среде выполнения кода, а не в контексте Claude. Этот цикл запрос-ответ повторяется для каждого вызова инструмента в коде.
4. Только финальный вывод попадает в контекст
Когда код завершает выполнение, в Claude возвращаются только результаты кода:
{ "type": "code_execution_tool_result", "tool_use_id": "srvtoolu_abc", "content": { "stdout": "[{\"name\": \"Alice\", \"spent\": 12500, \"limit\": 10000}... ]" } }Это все, что видит Claude, — не 2000+ строк расходов, обработанных по пути.
Когда применять программный вызов инструментов
Программный вызов добавляет шаг выполнения кода в рабочий процесс. Эта дополнительная нагрузка окупается, когда экономия токенов, улучшение задержки и рост точности значительны.
Наибольшая польза, когда:
- Обработка больших наборов данных, где нужны только агрегаты или обзоры
- Многошаговые процессы с тремя или более зависимыми вызовами инструментов
- Фильтрация, сортировка или преобразование результатов инструментов перед показом Claude
- Задачи, где промежуточные данные не должны влиять на рассуждения Claude
- Параллельные операции по многим элементам (проверка 50 эндпоинтов, например)
Меньше пользы, когда:
- Простые вызовы одного инструмента
- Задачи, где Claude должен видеть и рассуждать о всех промежуточных результатах
- Быстрые запросы с маленькими ответами
Примеры использования инструментов
Проблема
JSON Schema хорошо определяет структуру — типы, обязательные поля, разрешенные enum — но не передает шаблоны использования: когда включать необязательные параметры, какие комбинации подходят или какие соглашения ожидает API.
Рассмотрим API для поддержки тикетов:
{ "name": "create_ticket", "input_schema": { "properties": { "title": {"type": "string"}, "priority": {"enum": ["low", "medium", "high", "critical"]}, "labels": {"type": "array", "items": {"type": "string"}}, "reporter": { "type": "object", "properties": { "id": {"type": "string"}, "name": {"type": "string"}, "contact": { "type": "object", "properties": { "email": {"type": "string"}, "phone": {"type": "string"} } } } }, "due_date": {"type": "string"}, "escalation": { "type": "object", "properties": { "level": {"type": "integer"}, "notify_manager": {"type": "boolean"}, "sla_hours": {"type": "integer"} } } }, "required": ["title"] } }Схема определяет, что валидно, но оставляет ключевые вопросы без ответа:
- Неясность формата: Должен ли
due_dateбыть "2024-11-06", "Nov 6, 2024" или "2024-11-06T00:00:00Z"? - Соглашения ID: Это
reporter.idUUID, "USR-12345" или просто "12345"? - Использование вложенной структуры: Когда заполнять
reporter.contact? - Корреляции параметров: Как
escalation.levelиescalation.sla_hoursсвязаны с priority?
Такие неясности приводят к искаженным вызовам инструментов и непоследовательному использованию параметров.
Решение
Примеры использования инструментов позволяют добавлять образцы вызовов инструментов прямо в определения. Вместо опоры только на схему вы показываете Claude конкретные шаблоны:
{ "name": "create_ticket", "input_schema": { /* same schema as above */ }, "input_examples": [ { "title": "Login page returns 500 error", "priority": "critical", "labels": ["bug", "authentication", "production"], "reporter": { "id": "USR-12345", "name": "Jane Smith", "contact": { "email": "jane@acme.com", "phone": "+1-555-0123" } }, "due_date": "2024-11-06", "escalation": { "level": 2, "notify_manager": true, "sla_hours": 4 } }, { "title": "Add dark mode support", "labels": ["feature-request", "ui"], "reporter": { "id": "USR-67890", "name": "Alex Chen" } }, { "title": "Update API documentation" } ] }Из этих трех примеров Claude усваивает:
- Соглашения формата: Даты в YYYY-MM-DD, ID пользователей как USR-XXXXX, метки в kebab-case
- Шаблоны вложенных структур: Как строить объект reporter с вложенным contact
- Корреляции необязательных параметров: Критические баги имеют полную контактную информацию + эскалацию с жесткими SLA; запросы фич — reporter без contact/escalation; внутренние задачи — только title
В наших внутренних тестах примеры использования инструментов повысили точность с 72% до 90% для сложной обработки параметров.
Когда применять примеры использования инструментов
Примеры использования добавляют токены к определениям инструментов, так что они ценны, когда рост точности перевешивает доп. затраты.
Наибольшая польза, когда:
- Сложные вложенные структуры, где валидный JSON не подразумевает правильное использование
- Инструменты с многими необязательными параметрами, где шаблоны включения важны
- API с домен-специфическими соглашениями, не захваченными в схемах
- Похожие инструменты, где примеры уточняют выбор (например,
create_ticketvscreate_incident)
Меньше пользы, когда:
- Простые инструменты с одним параметром и очевидным использованием
- Стандартные форматы вроде URL или email, которые Claude уже понимает
- Проблемы валидации, лучше решаемые ограничениями JSON Schema
Лучшие практики
Создание агентов, выполняющих реальные действия, требует баланса масштаба, сложности и точности. Эти три функции решают разные узкие места в рабочих процессах с инструментами. Вот как их комбинировать эффективно.
Накладывайте функции стратегически
Не каждый агент нуждается во всех трех функциях для задачи. Начните с главного узкого места:
- Раздувание контекста от определений инструментов → Инструмент поиска инструментов
- Большие промежуточные результаты, загрязняющие контекст → Программный вызов инструментов
- Ошибки параметров и искаженные вызовы → Примеры использования инструментов
Этот фокусированный подход позволяет решить конкретное ограничение, тормозящее агента, без лишней сложности на старте.
Затем добавляйте другие функции по мере нужды. Они дополняют друг друга: инструмент поиска обеспечивает нахождение правильных инструментов, программный вызов — эффективное выполнение, примеры использования — верный вызов.
Настройте инструмент поиска для лучшего обнаружения
Поиск инструментов работает по именам и описаниям, так что четкие, описательные определения улучшают точность обнаружения.
// Хорошо { "name": "search_customer_orders", "description": "Search for customer orders by date range, status, or total amount. Returns order details including items, shipping, and payment info." } // Плохо { "name": "query_db_orders", "description": "Execute order query" }Добавьте руководство в системный промт, чтобы Claude знал, что доступно:
У вас есть инструменты для сообщений в Slack, управления файлами в Google Drive, отслеживания тикетов в Jira и операций с репозиториями в GitHub. Используйте поиск инструментов для нахождения конкретных возможностей.Держите 3-5 наиболее используемых инструментов всегда загруженными, остальное — отложенным. Это балансирует быстрый доступ к распространенным операциям с обнаружением по требованию для всего остального.
Настройте программный вызов для правильного выполнения
Поскольку Claude пишет код для парсинга выводов инструментов, четко документируйте форматы возврата. Это помогает Claude писать правильную логику парсинга:
{ "name": "get_orders", "description": "Retrieve orders for a customer. Returns: List of order objects, each containing: - id (str): Order identifier - total (float): Order total in USD - status (str): One of 'pending', 'shipped', 'delivered' - items (list): Array of {sku, quantity, price} - created_at (str): ISO 8601 timestamp" }Вот инструменты, которые выигрывают от программной оркестрации:
- Инструменты, выполняемые параллельно (независимые операции)
- Операции, безопасные для повторного запуска (идемпотентные)
Настройте примеры использования для точности параметров
Создавайте примеры для ясности поведения:
- Используйте реалистичные данные (реальные названия городов, правдоподобные цены, не "string" или "value")
- Показывайте разнообразие: минимальные, частичные и полные шаблоны спецификации
- Держите кратко: 1-5 примеров на инструмент
- Фокусируйтесь на неоднозначностях (добавляйте примеры только где правильное использование не очевидно из схемы)
Начало работы
Эти функции доступны в бета-версии. Чтобы их включить, добавьте заголовок беты и укажите нужные инструменты:
client.beta.messages.create( betas=["advanced-tool-use-2025-11-20"], model="claude-sonnet-4-5-20250929", max_tokens=4096, tools=[ {"type": "tool_search_tool_regex_20251119", "name": "tool_search_tool_regex"}, {"type": "code_execution_20250825", "name": "code_execution"}, # Ваши инструменты с defer_loading, allowed_callers и input_examples ] )Эти функции переводят использование инструментов от простого вызова функций к интеллектуальной оркестрации. По мере того как агенты берутся за сложные процессы с десятками инструментов и большими наборами данных, динамическое обнаружение, эффективное выполнение и надежный вызов становятся основой.