Большой анализ свыше 170 тысяч трассировок рассуждений из открытых моделей показывает, что крупные языковые модели сильно зависят от простых стандартных подходов, когда задания усложняются. Новый фреймворк из когнитивной науки для классификации процессов мышления помогает лучше понять, каких способностей не хватает и когда дополнительные подсказки в промте действительно полезны.
Как указано в исследовании под названием "Когнитивные основы рассуждений и их проявление в больших языковых моделях", существующие тесты для языковых моделей не оценивают их способности к рассуждениям по-настоящему. Они в основном проверяют, верен ли итоговый ответ, отмечают авторы. А то, действительно ли модель рассуждает или просто воспроизводит знакомые шаблоны, обычно остается за кадром.
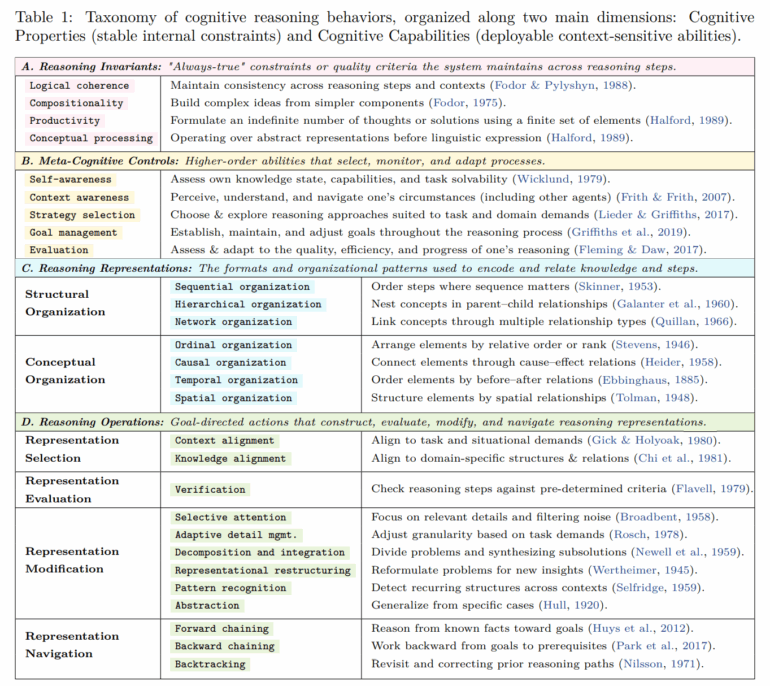
Чтобы обойти эту проблему, исследователи разобрали 171 485 подробных трассировок рассуждений от 17 моделей и сопоставили их с 54 путями решений, которые люди описывали вслух. Задания включали математические задачи, поиск ошибок, политические и медицинские дилеммы.

Карта когнитивных блоков, лежащих в основе рассуждений моделей
Для сравнения трассировок ученые выделили 28 повторяющихся элементов мышления. Среди них:
- Базовые правила, такие как последовательность и объединение простых идей в более сложные.
- Поведение по самоконтролю, включая постановку целей, распознавание неопределенности или отслеживание прогресса.
- Различные способы упорядочивания данных — в виде списка, дерева, цепочки причинно-следственных связей или пространственного образа.
- Стандартные шаги рассуждений, например, разбиение проблемы на части, проверка промежуточных этапов, откат неверного пути или обобщение на основе примеров.
Этот фреймворк применили для пометки каждого фрагмента трассировки рассуждений, где проявлялся один из таких элементов.
Когда задания усложняются, модели ИИ переходят на автопилот
Результаты выявляют четкую закономерность. На четко структурированных заданиях, вроде классических математических задач, модели задействуют довольно разнообразный набор элементов мышления. Но по мере того как задания становятся более расплывчатыми — например, открытые кейсы или моральные дилеммы — поведение моделей сужается. Доминирует линейная пошаговая обработка вместе с простыми проверками правдоподобия и прямым выводом из исходных фактов.
Статистический анализ демонстрирует, что успешные решения на таких сложных заданиях связаны с противоположным поведением: большим разнообразием структур, иерархической организацией, построением сетей причинных связей, рассуждением от цели назад и сознательным переосмыслением. Эти паттерны гораздо чаще встречаются в трассировках людей. Люди описывают свой подход, оценивают промежуточные результаты и гибко переключаются между стратегиями и представлениями.
Примеры из статьи наглядно иллюстрируют разницу. В логической задаче с шахматной доской человек решает ее кратким аргументом на основе абстракции цветовой схемы. Трассировка DeepSeek-R1 для той же задачи тянется более чем на 7000 токенов: она перечисляет координаты по одной, мечется между гипотезами и многократно пытается верифицировать, прежде чем дойти до абстракции.
В открытом задании по реформе здравоохранения участник- человек явно разбивает проблему на подцели, называет стратегию, оценивает источники по надежности, фокусируется на релевантных данных, организует системы здравоохранения по критериям, абстрагирует комплексную оценку и в конце отмечает, что результат неожиданный. Трассировка DeepSeek-R1 тоже применяет декомпозицию проблемы и причинное рассуждение, но почти не показывает явных смен стратегий, моментов самоанализа или изменений представлений.

По всем заданиям паттерн сохраняется: люди чаще прибегают к метапознанию и абстракции, гибко меняя представления, в то время как большие языковые модели генерируют длинные, повторяющиеся, линейные цепочки рассуждений.
Неясно, распространяются ли эти выводы на проприетарные модели рассуждений от компаний вроде OpenAI. Авторы предполагают, что открытые модели сильно зависят от автоматически сгенерированных трассировок рассуждений во время обучения, что может толкать их в последовательный автопилот. Как ведут себя проприетарные модели, обученные интенсивнее на данных человеческих рассуждений, — вопрос, на который исследование не дает ответа.
Подсказки для рассуждений помогают только сильным моделям
Команда также проверила, можно ли превратить наиболее успешные паттерны рассуждений в практические промты. Из типичных структур успеха они вывели инструкции, предписывающие процесс мышления — например, сначала отбирать релевантную информацию, потом строить структуру и только после этого делать выводы.
Модели вроде Qwen3-14B, Qwen3-32B, R1-Distill-Qwen-14B/32B, R1-Distill-Llama-70B и Qwen3-8B продемонстрировали явный рост точности, иногда более чем на 20 процентов относительно. На дилеммах и анализе кейсов точность вырастала до 60 процентов в отдельных сценариях. Сложные, плохо структурированные категории вроде Dilemma, Diagnosis-Solution и Case Analysis выигрывали больше всего.
Для меньших или слабых моделей эффект иногда оказывался обратным. Hermes-3-Llama-3-8B и DeepScaleR-1.5B фиксировали двузначные относительные падения в среднем и теряли до 70 процентов точности на некоторых четко структурированных заданиях. R1-Distill-Qwen-7B и OpenThinker-32B реагировали непредсказуемо: выигрыши в одних категориях и потери в других.
Авторы заключают, что существует порог возможностей: только модели с достаточно сильными навыками рассуждений и следования инструкциям умеют эффективно использовать детальный когнитивный каркас. Результаты также намекают, что дополнительные намеки на структуру менее полезны на четко организованных проблемах и могут конфликтовать с усвоенными эвристиками. Является ли такая подсказка разблокировкой скрытых способностей или в основном оптимизацией извлечения обученных паттернов — остается неясным.
Почему научное сообщество упускает сложное из виду
Метаанализ 1598 статей на arXiv показывает, что исследования по рассуждениям в больших языковых моделях в основном сосредоточились на легковымеряемых поведениях вроде пошаговых объяснений и декомпозиции проблем. Метапознание и пространственная или временная организация редко привлекают внимание — хотя анализ трассировок рассуждений предполагает, что они ключевы для сложных, плохо структурированных заданий.
В целом исследователи утверждают, что область все еще опирается на узкий фреймворк линейной декомпозиции, игнорируя множество важных когнитивных явлений.
Что это значит для следующего поколения моделей рассуждений
Авторы подчеркивают несколько вызовов и возможностей на основе своих находок.
Во-первых, нет теории, связывающей методы обучения с возникающими когнитивными способностями. Когнитивная психология подсказывает, что процедурные навыки развиваются через повторение, но метапознание требует явного размышления о своем мышлении. Применительно к большим языковым моделям это может означать, что стандартные настройки RL усиливают верификацию, но мало помогают с самоконтролем или сменой стратегий.
Во-вторых, исследование демонстрирует, что большие языковые модели хорошо справляются с ясными заданиями вроде задач на сюжеты или фактических запросов, но буксуют на похожих, но менее структурированных, таких как задачи дизайна или диагностики. В когнитивной науке гибкое рассуждение требует обучения абстрактным правилам на множестве разных типов заданий. Авторы предлагают обучать большие языковые модели на структурно разнообразных датасетах и учить их сравнивать форматы заданий.
В-третьих, они предупреждают, что шаги решений, генерируемые моделью, не всегда показывают, понимает ли модель проблему по-настоящему или просто переиспользует паттерны. Чтобы проверить это, нужны оценки, измеряющие перенос знаний на новые ситуации, плюс глубокий анализ внутренних механизмов модели.
В-четвертых, исследователи видят в своей когнитивной карте инструмент для более осознанного формирования обучения. Например, награды в reinforcement learning можно настроить, чтобы поощрять редкие, но важные стили рассуждений вроде переосмысления или метапознания.
Команда собирается выложить свой код и данные на GitHub и Hugging Face.