Представляем Gemini 2.5 Flash
Сегодня мы запускаем раннюю версию Gemini 2.5 Flash в режиме предварительного просмотра через Gemini API в Google AI Studio и Vertex AI. Основанная на популярной версии 2.0 Flash, эта новая модель предлагает значительное улучшение возможностей рассуждения, сохраняя приоритет скорости и стоимости. Gemini 2.5 Flash — это наша первая полностью гибридная модель рассуждений, предоставляющая разработчикам возможность включать или отключать мышление. Модель также позволяет устанавливать бюджет мышления для нахождения оптимального баланса между качеством, стоимостью и задержкой. Даже при отключенном мышлении разработчики могут сохранять высокую скорость 2.0 Flash и улучшать производительность.
Модели Gemini 2.5 с возможностью мышления
Наши модели Gemini 2.5 способны рассуждать через свои мысли перед ответом. Вместо немедленного генерации вывода модель может выполнять процесс «мышления», чтобы лучше понять запрос, разбить сложные задачи и спланировать ответ. На сложных задачах, требующих нескольких шагов рассуждения (например, решение математических проблем или анализ исследовательских вопросов), процесс мышления позволяет модели приходить к более точным и полным ответам. Фактически, Gemini 2.5 Flash показывает сильные результаты на сложных запросах в LMArena, уступая только версии 2.5 Pro.
Сравнительные показатели
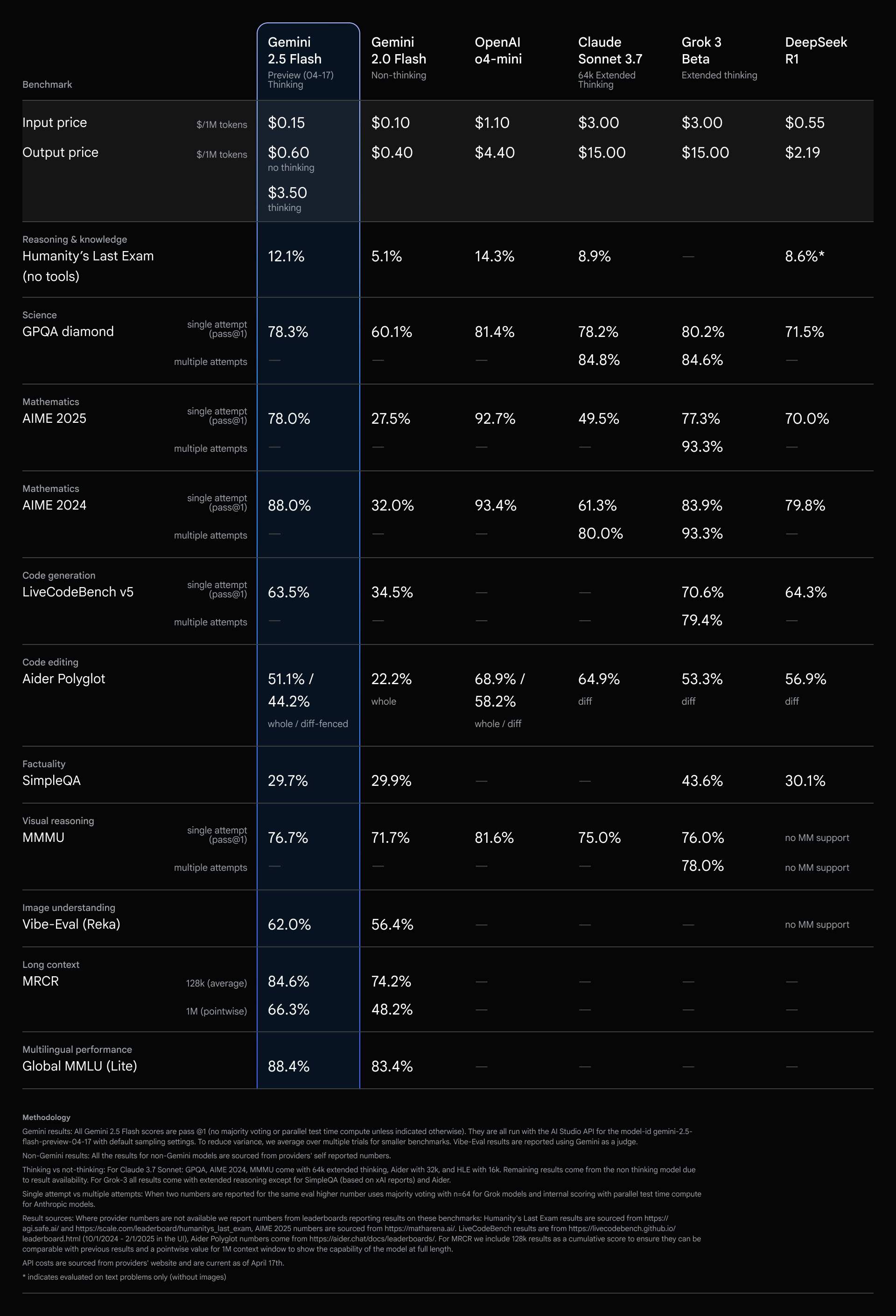
2.5 Flash имеет сопоставимые показатели с другими ведущими моделями за долю стоимости и размера.
Наша самая экономичная модель с мышлением
2.5 Flash продолжает лидировать как модель с лучшим соотношением цены и производительности.
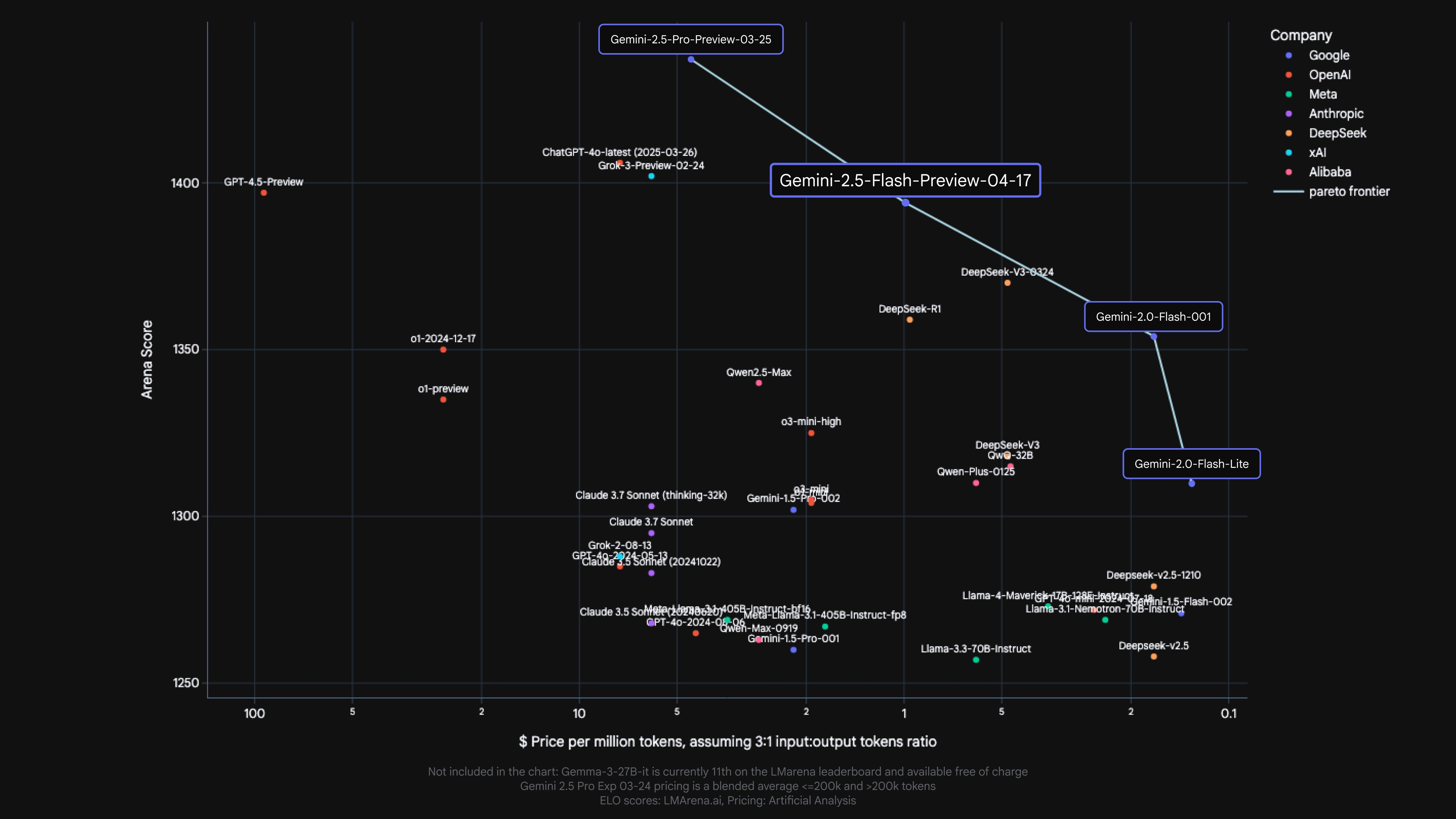
Gemini 2.5 Flash добавляет ещё одну модель к парето-фронту Google по соотношению стоимости и качества.*
Тонкий контроль над мышлением
Мы знаем, что разные варианты использования требуют различных компромиссов между качеством, стоимостью и задержкой. Чтобы предоставить разработчикам гибкость, мы включили установку бюджета мышления, который предлагает тонкий контроль над максимальным количеством токенов, которые модель может сгенерировать во время мышления. Более высокий бюджет позволяет модели рассуждать дальше для улучшения качества. Важно отметить, что бюджет устанавливает предел того, сколько может думать 2.5 Flash, но модель не использует полный бюджет, если запрос этого не требует.
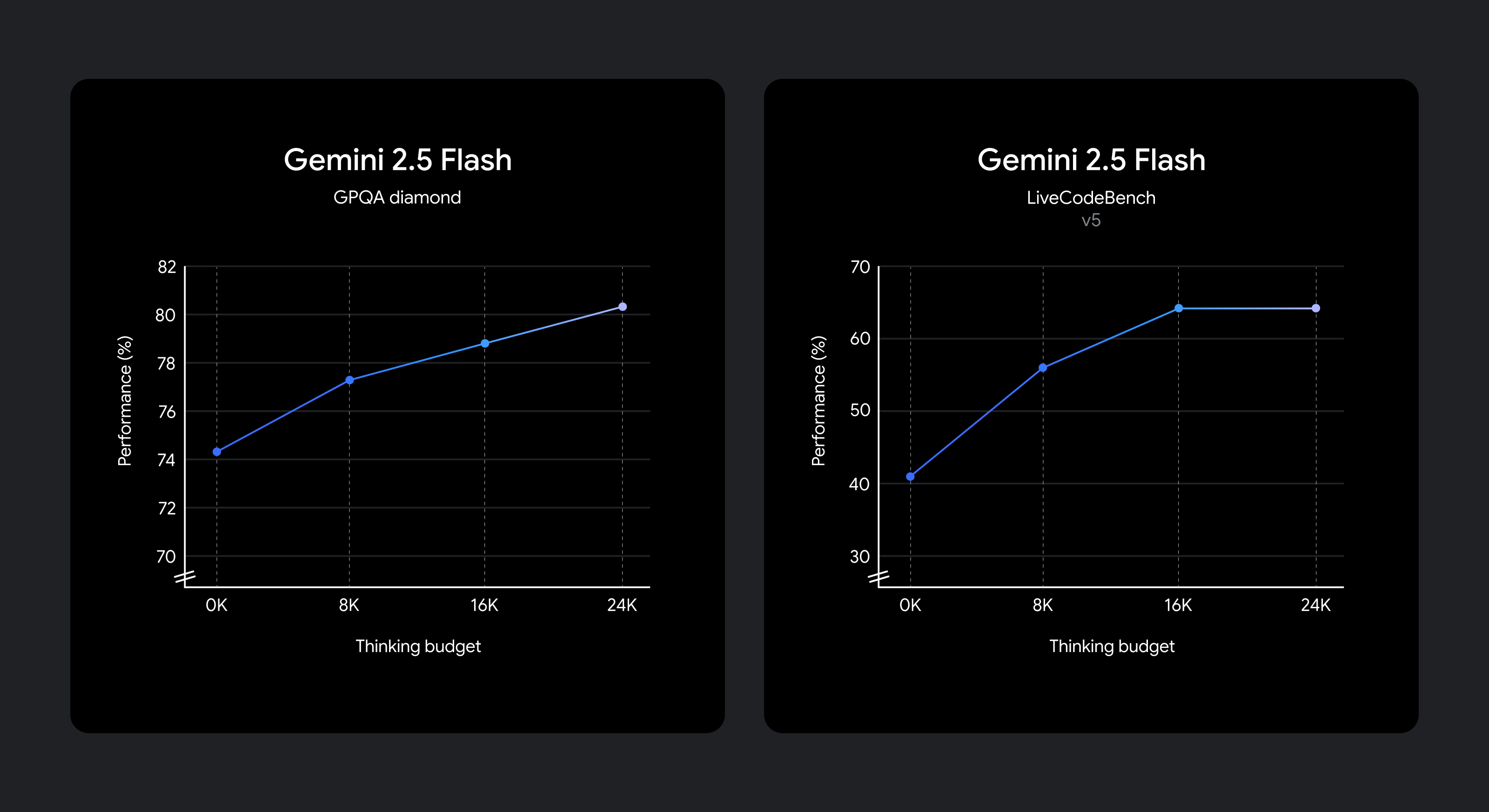
Улучшение качества рассуждений с увеличением бюджета мышления.
Модель обучена знать, как долго думать для данного запроса, и поэтому автоматически решает, сколько думать, основываясь на воспринимаемой сложности задачи.
Если вы хотите сохранить самую низкую стоимость и задержку, улучшая при этом производительность по сравнению с 2.0 Flash, установите бюджет мышления на 0. Вы также можете выбрать установку конкретного бюджета токенов для фазы мышления, используя параметр в API или ползунок в Google AI Studio и Vertex AI. Бюджет может варьироваться от 0 до 24576 токенов для 2.5 Flash.
Примеры запросов с различным уровнем рассуждений
Запросы, требующие низкого уровня рассуждений:
Пример 1: «Спасибо» на испанском
Пример 2: Сколько провинций в Канаде?
Запросы, требующие среднего уровня рассуждений:
Пример 1: Вы бросаете два кубика. Какова вероятность того, что их сумма равна 7?
Пример 2: В моём спортзале есть часы для игры в баскетбол с 9:00 до 15:00 по понедельникам, средам и пятницам и с 14:00 до 20:00 по вторникам и субботам. Если я работаю с 9:00 до 18:00 пять дней в неделю и хочу играть в баскетбол 5 часов в будние дни, создайте для меня расписание, чтобы всё успеть.
Запросы, требующие высокого уровня рассуждений:
Пример 1: Консольная балка длиной L=3 м имеет прямоугольное поперечное сечение (ширина b=0,1 м, высота h=0,2 м) и сделана из стали (E=200 ГПа). Она подвергается равномерно распределённой нагрузке w=5 кН/м по всей длине и точечной нагрузке P=10 кН на свободном конце. Рассчитайте максимальное напряжение изгиба (σ_max).
Пример 2: Напишите функцию evaluate_cells(cells: Dict[str, str]) -> Dict[str, float], которая вычисляет значения ячеек электронной таблицы.
Каждая ячейка содержит:
- Число (например,
"3") - Или формулу типа
"=A1 + B1 * 2"с использованием+,-,*,/и других ячеек.
Требования:
- Разрешение зависимостей между ячейками.
- Обработка приоритета операторов (
*/перед+-). - Обнаружение циклов и вызов
ValueError("Cycle detected at <cell>"). - Без использования
eval(). Используйте только встроенные библиотеки.
Начните разработку с Gemini 2.5 Flash сегодня
Gemini 2.5 Flash с возможностями мышления теперь доступен в предварительном просмотре через Gemini API в Google AI Studio и в Vertex AI, а также в специальном выпадающем меню в приложении Gemini. Мы рекомендуем поэкспериментировать с параметром thinking_budget и исследовать, как управляемое рассуждение может помочь решать более сложные проблемы.
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
response = client.models.generate_content(
model="gemini-2.5-flash-preview-04-17",
contents="You roll two dice. What’s the probability they add up to 7?",
config=genai.types.GenerateContentConfig(
thinking_config=genai.types.ThinkingConfig(
thinking_budget=1024
)
)
)
print(response.text)Python
Найдите подробные ссылки на API и руководства по мышлению в нашей документации для разработчиков или начните с примеров кода из Gemini Cookbook.
Мы продолжим улучшать Gemini 2.5 Flash, и скоро появится больше обновлений, прежде чем мы сделаем его общедоступным для полного производственного использования.
*Цены на модели взяты из Artificial Analysis и документации компании.