Краткий обзор
Системы LLM в роли судьи могут обмануться убедительными, но неверными ответами, что создает ложное ощущение надежности моделей. Мы разработали датасет с ручной разметкой и применили открытый фреймворк syftr для тщательного тестирования конфигураций оценщиков. Результаты описаны в полной статье. Главный вывод: не полагайтесь слепо на оценщика — проверяйте его.
Переходя на саморазвернутые открытые модели для нашей системы генерации с агентами и извлечением данных (RAG), мы были впечатлены первыми результатами. На сложных тестах, таких как FinanceBench, наши системы демонстрировали выдающуюся точность.
Этот энтузиазм быстро угас, когда мы детально разобрались в способе работы системы LLM-оценщика при присвоении баллов ответам.
Реальность: наши новые оценщики вводились в заблуждение.
В RAG-системе, не сумевшей отыскать данные для расчета финансового показателя, просто объяснялось, что информация недоступна.
Оценщик начислял полные баллы за это правдоподобное объяснение, считая, что система правильно констатировала отсутствие данных. Эта единственная уязвимость искажала итоги на 10–20% — достаточно, чтобы средняя система казалась передовой.
Это вызвало ключевой вопрос: если оценщику нельзя верить, как верить результатам?
Ваш LLM-оценщик может вас обманывать, и вы не узнаете об этом без строгих проверок. Лучший оценщик не всегда самый крупный или дорогой.
С подходящими данными и инструментами можно создать вариант дешевле, точнее и надежнее, чем gpt-4o-mini. В этом подробном обзоре исследования мы объясняем, как это сделать.
Причины сбоев LLM-оценщиков
Открытая нами проблема выходила за рамки обычной ошибки. Оценка сгенерированного контента всегда сложна по своей природе, а LLM-оценщики подвержены тонким, но значимым сбоям.
Наш начальный случай идеально иллюстрировал, как оценщик поддается влиянию уверенного тона рассуждений. Например, в одной проверке по семейному древу оценщик постановил:
«Сгенерированный ответ релевантен и верно определяет, что недостаточно данных для указания конкретного двоюродного родственника… Хотя эталонный ответ перечисляет имена, вывод сгенерированного ответа соответствует логике, что вопрос не содержит нужных сведений.»
На деле информация присутствовала — RAG-система просто не смогла ее извлечь. Оценщик попался на властный тон ответа.
Глубже копнув, мы выявили другие трудности:
- Неопределенность в числах: Является ли 3,9% «достаточно близким» к 3,8%? Оценщики часто не имеют контекста для вердикта.
- Семантическое равенство: Подходит ли «APAC» вместо «Азиатско-Тихоокеанский регион: Индия, Япония, Малайзия, Филиппины, Австралия»?
- Ошибочные эталоны: Бывает, что сам «правильный» ответ неверен, ставя оценщика в тупик.
Эти сбои подчеркивают важный урок: выбор мощного LLM и простая просьба оценить недостаточны. Идеальное совпадение между оценщиками, будь то люди или машины, невозможно без более строгого метода.
Разработка фреймворка для надежности
Чтобы преодолеть эти трудности, нам требовался способ оценивать самих оценщиков. Это подразумевало два аспекта:
- Качественный датасет с ручной разметкой суждений.
- Систему для последовательного тестирования различных конфигураций оценщиков.
Сначала мы собрали собственный датасет, доступный на HuggingFace. Мы создали сотни тройек вопрос-ответ-реакция с помощью разнообразных RAG-систем.
Затем наша команда вручную разметила все 807 примеров.
Каждый пограничный случай обсуждался, и мы ввели четкие, единообразные правила оценки.
Сам процесс оказался поучительным, демонстрируя субъективность оценки. В итоге разметка отразила распределение: 37,6% неудачных и 62,4% успешных ответов.
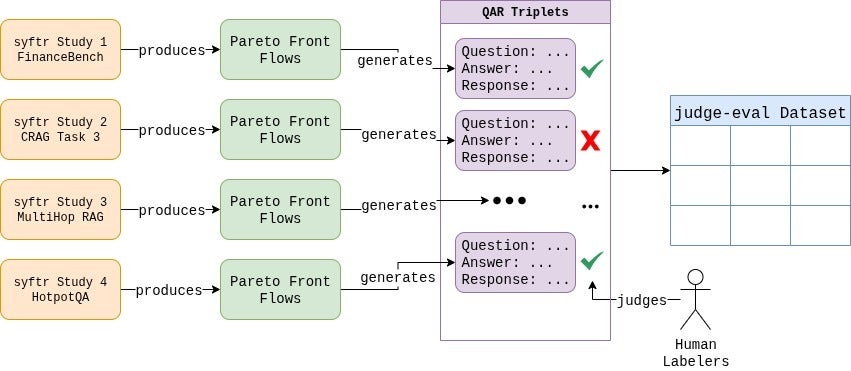
Далее требовался инструмент для экспериментов. Здесь пригодился наш открытый фреймворк syftr.
Мы расширили его новым классом JudgeFlow и настраиваемым пространством поиска для изменения выбора LLM, температуры и дизайна промпта. Это позволило систематически изучать — и находить — конфигурации оценщиков, наиболее близкие к человеческим суждениям.
Тестирование оценщиков на практике
С фреймворком наготове мы приступили к экспериментам.
Первый тест сосредоточился на модели Master-RM, специально настроенной, чтобы избегать «хакинга вознаграждений» путем приоритета контента над фразами рассуждений.
Мы сравнили ее с базовой моделью по четырем промптам:
- «Стандартный» промпт CorrectnessEvaluator из LlamaIndex, запрашивающий рейтинг 1–5.
- Тот же промпт CorrectnessEvaluator, но с рейтингом 1–10.
- Более детализированная версия промпта CorrectnessEvaluator с явными критериями.
- Простой промпт: «Верни YES, если Сгенерированный Ответ верен относительно Эталонного Ответа, или NO, если нет.»
Результаты оптимизации syftr показаны ниже на графике стоимость–точность. Точность — это процент совпадения оценщика с human-эвалюаторами, стоимость оценена по ценам за токен от Together.ai.
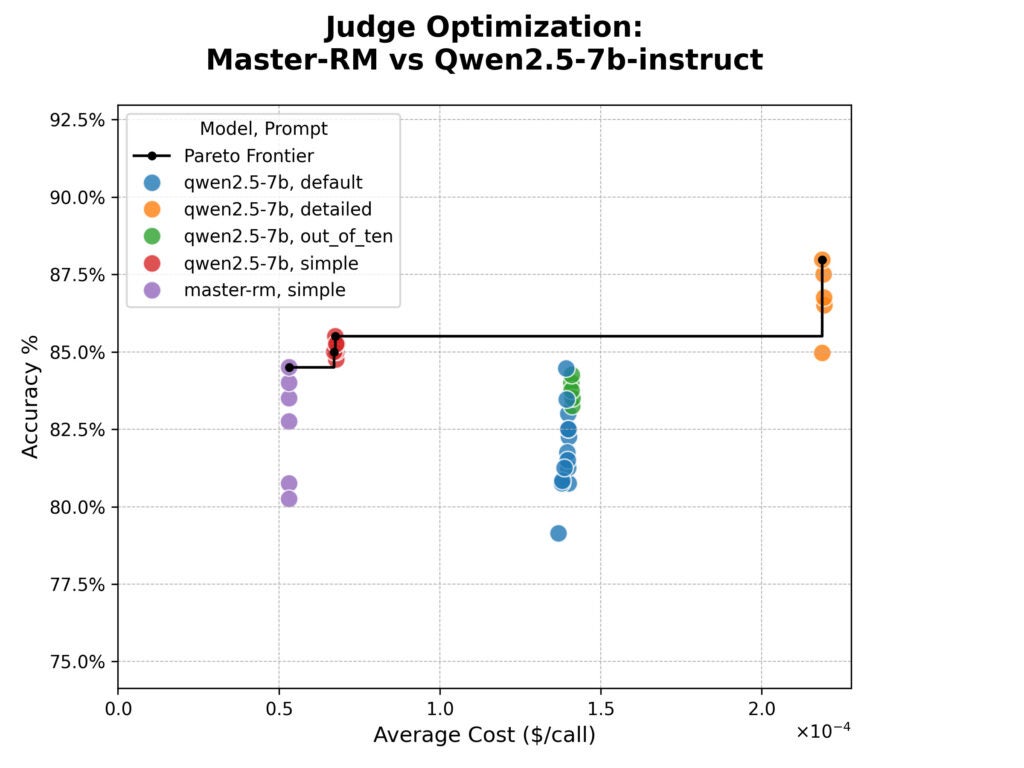
Результаты удивили.
Master-RM не превосходила базовую модель по точности и испытывала трудности с форматами за пределами «простого» промпта из-за узкой специализации обучения.
Хотя обучение модели помогало противостоять влиянию конкретных фраз рассуждений, оно не повысило общую согласованность с человеческими суждениями в нашем датасете.
Мы также отметили явный компромисс. «Детализированный» промпт был самым точным, но в четыре раза дороже по токенам.
Затем мы расширили масштаб, оценив группу крупных открытых моделей (от Qwen, DeepSeek, Google и NVIDIA) и протестировав новые стратегии оценщиков:
- Случайный выбор: Выбор оценщика случайно из пула для каждой проверки.
- Консенсус: Опрос 3 или 5 моделей с взятием большинства голосов.
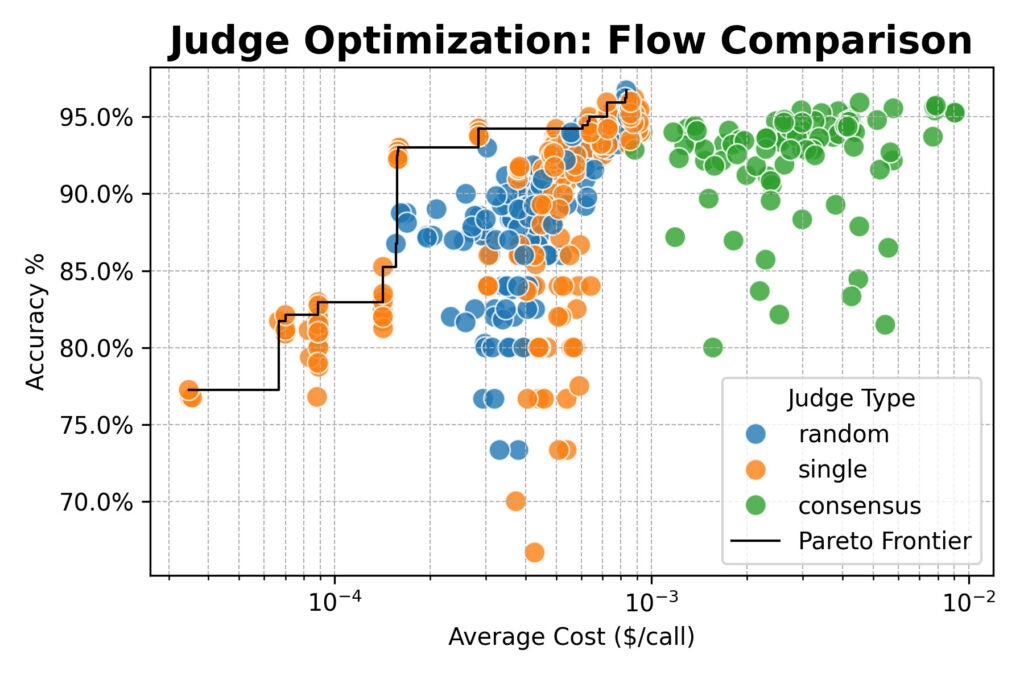
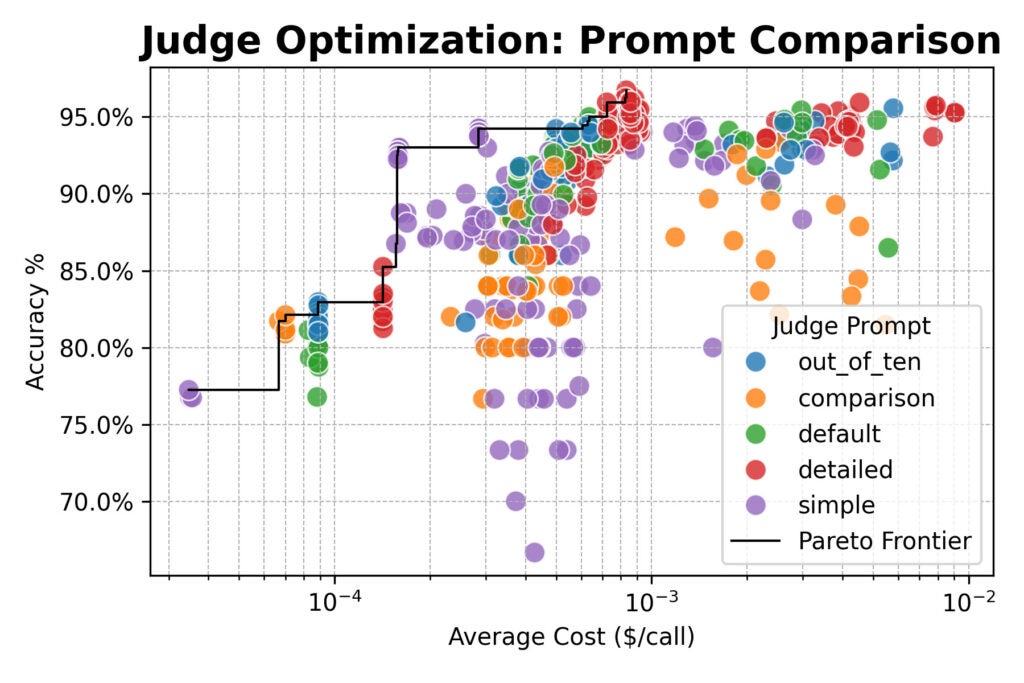
Что отличает этот подход?
Долгое время нашим правилом было: «Просто используйте gpt-4o-mini.» Это популярный упрощенный вариант для команд, ищущих готового надежного оценщика. Хотя gpt-4o-mini показывала хорошие результаты (около 93% точности со стандартным промптом), эксперименты выявили ее ограничения. Она — лишь одна точка на широкой кривой компромиссов.
Систематический метод предлагает набор оптимизированных опций вместо единственного дефолта:
- Максимальная точность, независимо от цены. Консенсусный поток с детализированным промптом и моделями вроде Qwen3-32B, DeepSeek-R1-Distill и Nemotron-Super-49B достиг 96% согласованности с людьми.
- Экономичный, быстрый тест. Одна модель с простым промптом обеспечила ~93% точности за пятую часть стоимости базовой gpt-4o-mini.
Оптимизируя по точности, стоимости и задержке, вы получаете обоснованные выборы, адаптированные к проекту, — вместо ставки на универсального оценщика.
Создание надежных оценщиков: Основные выводы
Независимо от использования нашего фреймворка, наши открытия помогут построить более стабильные системы оценки:
- Промптинг — главный рычаг. Для наибольшей близости к человеку применяйте детализированные промпты, четко описывающие критерии. Не надейтесь, что модель сама поймет, что значит «хорошо» для вашей задачи.
- Простота эффективна при приоритете скорости. Если критичны стоимость или задержка, простой промпт (например, «Верни YES, если Сгенерированный Ответ верен относительно Эталонного Ответа, или NO, если нет.») в паре с сильной моделью дает отличное соотношение с минимальной потерей точности.
- Комитеты обеспечивают устойчивость. Для ключевых проверок, где точность обязательна, опрос 3–5 разнообразных мощных моделей с большинством голосов снижает предвзятость и шум. В нашем исследовании топовый консенсус объединил Qwen/Qwen3-32B, DeepSeek-R1-Distill-Llama-70B и Nemotron-Super-49B от NVIDIA.
- Крупные, умные модели выигрывают. Большие LLM стабильно опережали малые. К примеру, переход от microsoft/Phi-4-multimodal-instruct (5,5B) с детализированным промптом к gemma3-27B-it с простым дал прирост точности на 8% — при почти нулевой разнице в стоимости.
От сомнений к уверенности
Наше путешествие стартовало с тревожного открытия: вместо следования рубрике наши LLM-оценщики поддавались длинным, правдоподобным отказами.
Рассматривая оценку как строгую инженерную задачу, мы перешли от неуверенности к твердости. Мы обрели четкое понимание и открытый датасет, побуждая изучить собственные пайплайны оценки. «Лучшая» конфигурация всегда зависит от ваших нужд, но теперь не нужно гадать.