Южнокорейский интернет-гигант Naver разработал видео-мировую модель, опирающуюся на реальную геометрию города из более миллиона своих панорам Street View. Эта модель переносится на другие города без дополнительной настройки.
Ранние видео-мировые модели создают правдоподобные, но полностью вымышленные окружения. Всё за пределами начального кадра — невидимые улицы, дальние здания — просто придумывается. Специалисты из Naver и Naver Cloud пошли другим путём: их Seoul World Model (SWM) привязывает генерацию видео к настоящей геометрии и виду реального города.
Как указано в исследовательской работе, это первая мировая модель, привязанная к конкретному физическому месту. Naver часто называют «гуглом Южной Кореи» — компания ведёт ведущую поисковую систему страны и сервис Naver Map с панорамами улиц, похожими на Google Maps. Модель берёт данные прямо из этого хранилища.
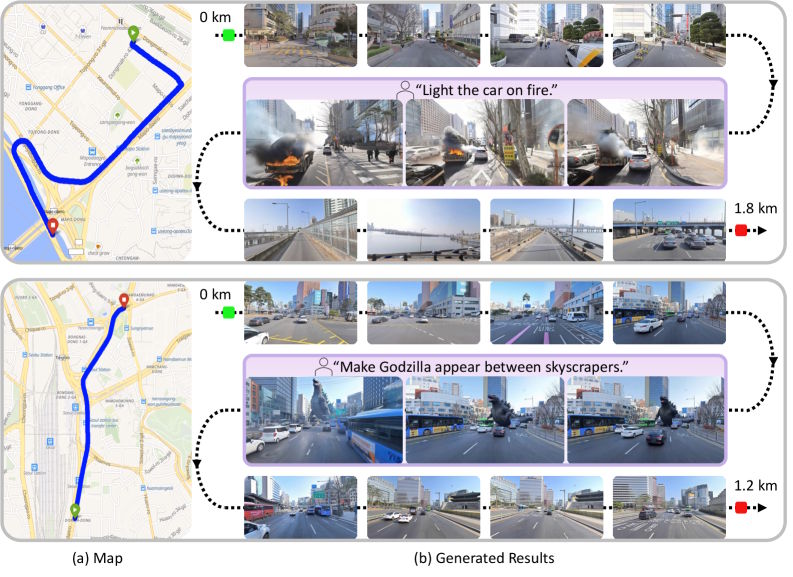
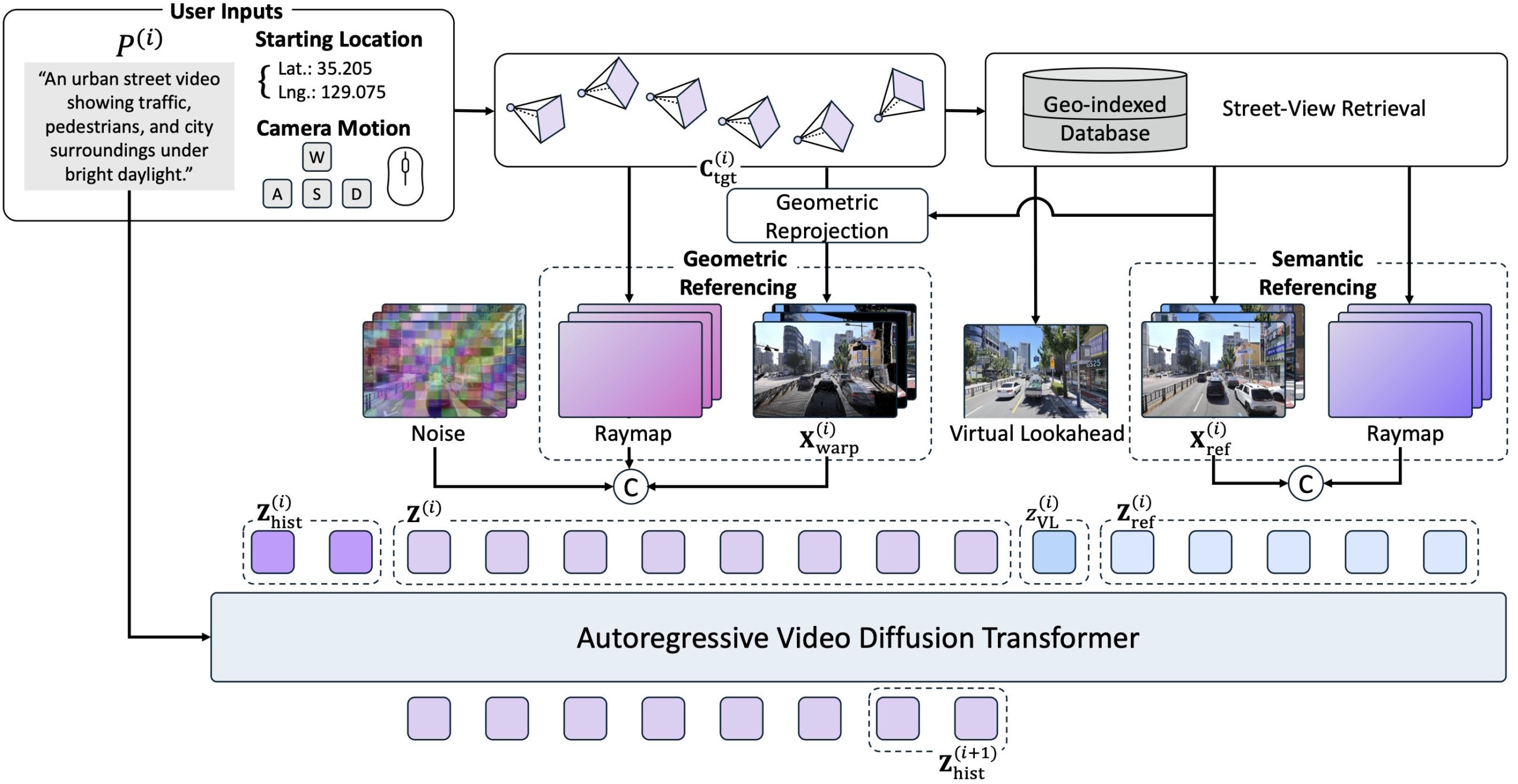
Пользователи задают географические координаты, желаемое движение камеры и текстовый запрос. Тогда модель ищет в базе 1,2 миллиона панорамных изображений из Naver Map, находит ближайшие Street View и использует их как ориентиры для пошаговой генерации видео.
Реальные данные с улиц порождают три основные трудности
Работа с настоящими изображениями рождает задачи, которых нет у чисто синтетических моделей. Главная: панорамы Street View — это статичные снимки. Машины и прохожие, попавшие в кадр во время съёмки, не связаны с динамичной сценой, которую нужно создать. Без корректировки модель просто скопирует эти случайные объекты из референсов в видео.

Разработчики устранили это с помощью «кросс-временной пары»: на обучении они специально сочетали референсные снимки и целевые последовательности из разных времён съёмки. Так модель учится отличать постоянные элементы вроде фасадов от временных, как припаркованные авто. Тесты без этой фичи показали: она даёт наибольший эффект среди всех компонентов.
Кроме того, камеры Street View ставят на машины и снимают раз в 5–20 метров. Полноценных видео нет, нет видов с уровня пешехода или с воздуха. Чтобы заполнить пробел, создали 12 700 синтетических видео в симуляторе Unreal Engine CARLA, охватив перспективы пешехода, транспорта и свободного полёта. Ещё ввели конвейер для создания временно coherent обучающих видео из разрозненных снимков.

Наконец, мелкие ошибки накапливаются на длинных дистанциях, поскольку видео строится по частям. Старые методы цепляются за первый кадр как за якорь, но он бесполезен после сотен метров пути камеры.
SWM меняет фиксированный якорь на «виртуальный смотровой пункт вперёд»: для каждой новой секции модель берёт Street View чуть дальше по маршруту и вставляет как виртуальную цель. Это даёт безошибочный ориентир, двигающийся вместе с камерой.
Карты глубины и исходные фото дополняют друг друга
Полученные Street View поступают в генератор по двум взаимодополняющим каналам. Сначала модель проецирует близкий референс в целевую перспективу через данные о глубине, задавая структуру сцены.
Во-вторых, референсы не подаются в трансформер сырыми пикселями. Их кодируют в латентные представления и интегрируют как семантические ориентиры. Так модель ловит детали вида окружения. Без любого из каналов качество сильно падает, отмечают авторы.
SWM основана на Cosmos-Predict2.5-2B от Nvidia — диффузионном трансформере с двумя миллиардами параметров. Обучение прошло на 24 GPU Nvidia H100 с 440 тысячами панорам Сеула, данными CARLA и открытыми записями Waymo.
SWM справляется с городами, которых не видела на обучении
Тестировали SWM в Сеуле, а также в Пусане и американском Энн-Арборе — обоих нет в обучающих данных. По статье, модель лучше шести актуальных видео-мировых, включая Aether, DeepVerse и HY-World1.5, по качеству видео, верности камеры, временной связности и соответствию реальным местам. Бенчмарки — 30 последовательностей по 100 метров.
Другие модели на длинных путях теряют чёткость или рушатся. SWM держит стабильность на сотни метров. При строгой привязке к геометрии она всё равно реагирует на текст: меняет погоду, время суток или добавляет сценарии, не трогая основу города.
Отсутствие полных видео всё ещё сдерживает точность предсказаний
Поскольку сплошных видео городов в открытом доступе нет, обучение идёт на интерполированных последовательностях из снимков — они уступают реальным записям. Неточные метки времени иногда вызывают резкое появление или исчезновение машин в видео.
Все Street View обработали по правилам приватности: лица и номера anonymized до обучения, говорят исследователи. Возможные применения — планировка городов, автономное вождение, исследования на местности.
Мировые модели сейчас в фокусе ИИ-разработок. Runway недавно показал первую «общую мировую модель» GWM-1, строящую внутреннее представление окружения и симулирующую события в реальном времени. Глава Google DeepMind Деми Хассабис считает такие модели шагом к общему ИИ. Исследование Microsoft Research и вузов США показало, что большие языковые модели подходят как мировые, предсказывая условия среды с точностью свыше 99 процентов.