Специалисты Qualcomm AI Research создали модульную систему, которая позволяет запускать языковые модели с функциями рассуждения прямо на смартфонах. Она уменьшает объем многословных мыслительных процессов этих моделей в 2,4 раза.
Модели рассуждений на мобильных устройствах сталкиваются с серьезными ограничениями: их длинные цепочки мыслей порождают огромное количество токенов, что приводит к перегрузке памяти и быстрому расходу заряда батареи. Новый подход Qualcomm решает эти проблемы и делает возможным работу таких моделей на смартфонах.
Как указано в исследовании, разработчики видят применение в умных персональных ассистентах, способных самостоятельно планировать многоэтапные задачи и взаимодействовать с приложениями, интерфейсами устройств и внешними сервисами. Локальный запуск обеспечивает безопасность данных, минимальные задержки и независимость от интернета.
Единая базовая модель с переключением режимов
Вместо создания новой модели с нуля авторы выбрали модульный метод. В основе лежит стандартная языковая модель без рассудительных способностей (Qwen2.5-7B-Instruct), дополненная LoRA-адаптерами — компактными модулями, которые активируются по необходимости. Такая модель может быстро отвечать как чат-бот или глубоко размышлять в зависимости от запроса.
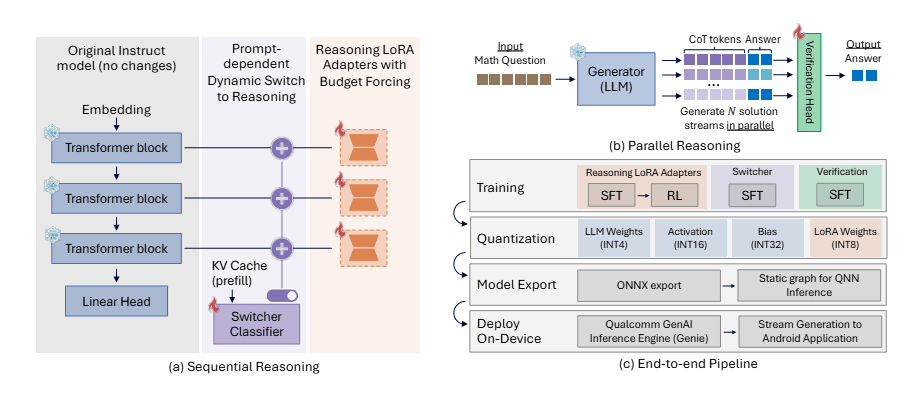
Обучение требуется лишь для примерно 4 процентов параметров, отмечают исследователи. При этом производительность приближается к показателям DeepSeek-R1-Distill-Qwen-7B, но с меньшими затратами на доработку. Встроенный классификатор сам определяет для каждого запроса, нужен ли сложный режим рассуждений, что экономит ресурсы на простых вопросах.
Обучение с подкреплением сокращает избыток токенов до 8 раз
После базовой настройки модели начинают генерировать чрезмерно длинные ответы. Они часто находят верное решение быстро, но затем тратят тысячи токенов на неоднократные проверки. Это явление исследователи называют «эпистемической нерешительностью», а в научном сообществе оно известно как «передумывание».
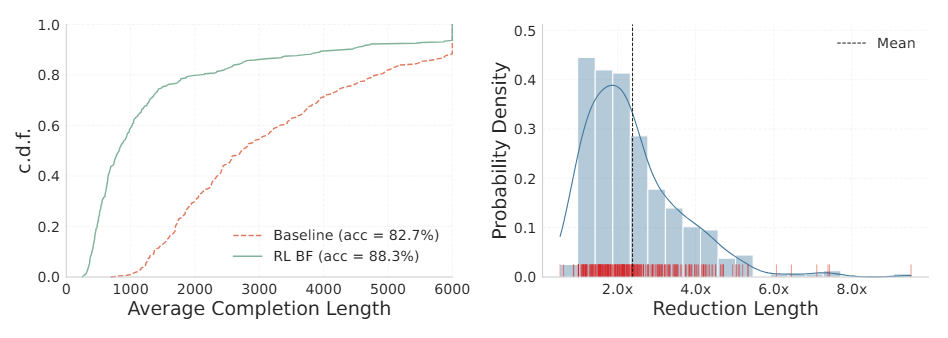
Чтобы справиться с этим, команда применила обучение с подкреплением, которое штрафует за слишком развернутые ответы. В среднем длина сокращается в 2,4 раза, а на отдельных задачах — до 8 раз. Пример из исследования: упрощение алгебраического выражения, на которое базовая модель потратила 3118 токенов, после оптимизации решается за 810 токенов. Точность при этом почти не страдает.

Первая попытка ограничить длину обернулась проблемой: модель формально завершала блок рассуждений, но переносила размышления в основную часть ответа. Пришлось переработать функцию вознаграждения, чтобы учитывать общую длину, — только тогда система перестала обходить ограничения.
Параллельные пути решений и сжатие до 4 бит для практики
Фреймворк поддерживает одновременный поиск нескольких путей решения. Небольшая оценочная голова на базовой модели определяет наиболее вероятный правильный вариант. При восьми параллельных запусках точность на бенчмарке MATH500 растет примерно на 10 процентов без заметного удлинения времени ответа, как показано в исследовании. Причина в том, что на мобильных устройствах генерация токенов ограничена доступом к памяти, а не вычислениями, поэтому параллельные потоки используют простоевую мощность.
Для реального запуска на смартфоне веса модели квантуют до 4 бит. Адаптеры рассуждений дообучают уже на сжатой версии; иначе выходит бессмысленный текст, предупреждают авторы. Несмотря на такое сильное сжатие, итоговая модель теряет всего около 2 процентов точности по сравнению с несжатой. На странице проекта есть видео с демонстрацией работы на мобильных устройствах.
Локальный ИИ на устройствах пока не вышел за рамки демонстраций
Qualcomm давно продвигает ИИ-модели для мобильных платформ, выпустив 80 оптимизированных моделей для Snapdragon и представив оркестратор ИИ, который связывает личные данные, приложения и локальные модели. Google тоже экспериментирует, показывая, как компактные языковые модели работают на Android с помощью FunctionGemma и AI Edge Gallery.
Однако все эти инициативы остаются на уровне технических прототипов. Для глубокой интеграции в систему — когда ассистент обращается к почте, фото и календарю — компании по-прежнему полагаются на облачные решения. Недавно анонсированная Google функция «Personal Intelligence» связывает Gemini с Gmail, Google Photos и Поиском, но полностью работает на серверах.