Всего 11 700 точек для обучения и одна сессия тренировки — и ИИ-агент поиска OpenSeeker показывает результаты на уровне разработок Alibaba и других решений. Данные, код и веса модели полностью открыты для всех.
Системы ИИ-агентов поиска, которые самостоятельно добывают информацию в сети через цепочку шагов, раньше оставались прерогативой технологических гигантов. OpenAI, Google и Alibaba скрывают данные для обучения. Даже те проекты, что делятся весами моделей, умалчивают о корпусах данных.
По мнению ученых из Шанхайского университета Цзяотун, такая монополия на данные уже почти год парализует открытые исследования. Проект OpenSeeker меняет положение дел: данные для обучения (лицензия MIT), код и веса модели доступны всем.
Структура ссылок в вебе вместо домыслов языковой модели для создания данных
OpenSeeker опирается на две ключевые идеи при генерации данных. Для пар вопрос-ответ основа — реальная структура гиперссылок в интернете, из которой формируют запросы. Система стартует с случайно выбранных начальных страниц в веб-корпусе (примерно 68 ГБ текстов на английском и 9 ГБ на китайском), переходит по ссылкам на связанные материалы и выделяет самую ценную информацию.
Конкретные названия и термины заменяют на общие описания, чтобы агент не мог решить задачу простым поиском по ключевым словам. Так достигается настоящая многошаговая логика поиска и размышлений.

Двухступенчатый фильтр отсеивает непригодные вопросы: мощная базовая модель не должна отвечать на них без инструментов, но обязана справляться с полным контекстом. Если условие не выполняется, вопрос отбрасывают.
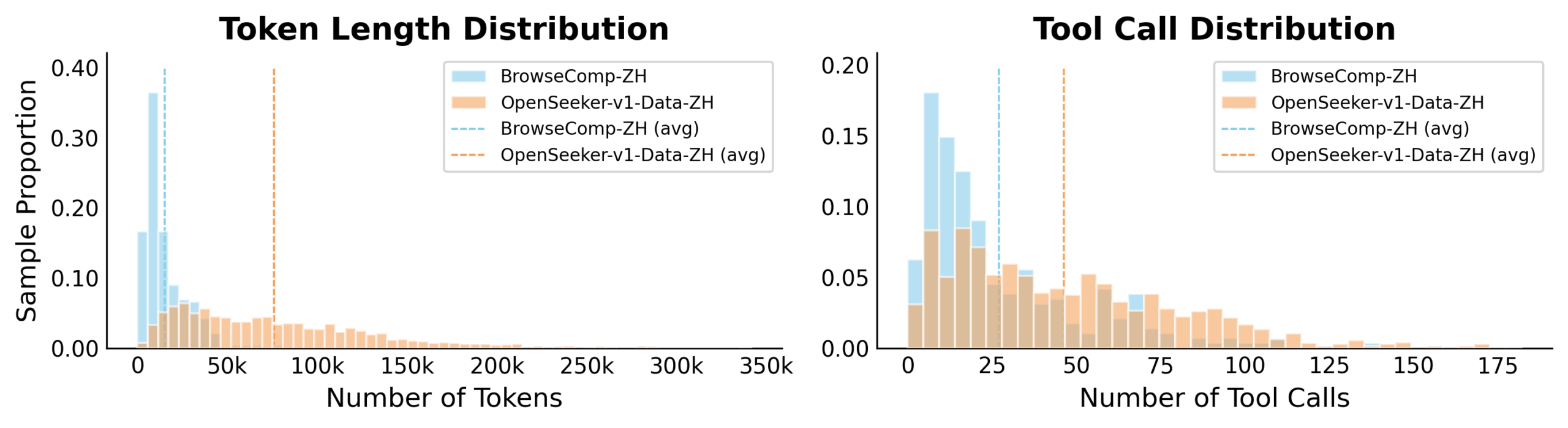
Вторая идея касается путей поиска, которые модель изучает. Веб-страницы полны помех, ухудшающих записи решений. При генерации данных учительская модель получает очищенный обзор прошлых результатов поиска и принимает более точные решения.
На этапе обучения ученическая модель работает с неочищенными сырыми данными, но должна повторять качественные выборы учителя. Это учит ее самостоятельно отличать полезный сигнал от шума.
11 700 точек данных против 147 000: качество побеждает количество
OpenSeeker построен на базе Qwen3-30B-A3B и дообучен всего на 11 700 точках данных за одну сессию с помощью supervised fine-tuning — без reinforcement learning и многократных доработок.
Как указано в статье, модель набрала 48,4% на бенчмарке BrowseComp-ZH для китайского языка, обойдя Tongyi DeepResearch от Alibaba с 46,7%. Модель Alibaba прошла трехэтапный процесс: расширенное предварительное обучение, supervised fine-tuning и reinforcement learning.
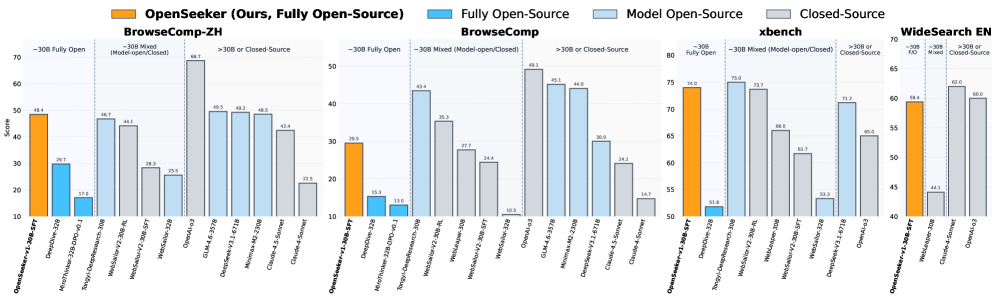
На англоязычном BrowseComp от OpenAI OpenSeeker набрал 29,5% — почти вдвое больше, чем у DeepDive с 15,3%, лидера среди полностью открытых агентов.
Сравнение с MiroThinker подчеркивает преимущество качества данных: та модель получила 147 000 примеров обучения, но показывает лишь 13,8% на BrowseComp-ZH. OpenSeeker достигает в 3,5 раза лучшего результата с менее чем двенадцатой частью данных.
До лидеров среди закрытых систем еще расстояние. GPT-5-High от OpenAI набирает 54,9% на BrowseComp, а DeepSeek-V3.2 с 671 миллиардом параметров — 51,4%. OpenSeeker работает с гораздо меньшим размером модели и затратами на обучение.
Доступ к качественным данным для обучения давно стал ключевым вопросом в индустрии ИИ. В прошлом году вышла Common Pile — 8 ТБ текстового датасета из открытых источников. Пока это не поколебало превосходство коммерческих моделей.