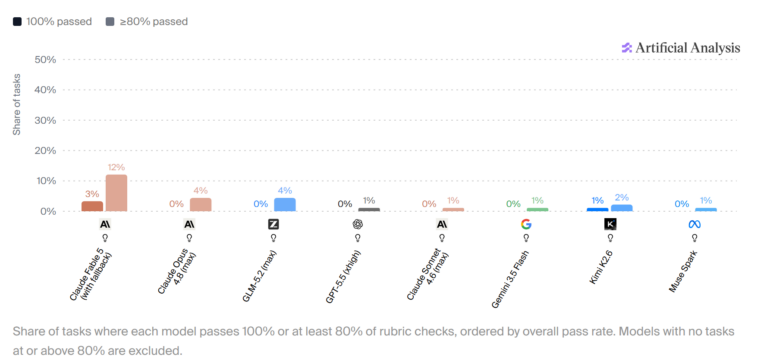
Даже самая продвинутая ИИ-модель не справляется с реалистичной интеллектуальной работой — полностью выполняет лишь 3% заданий.
Новый бенчмарк AA-Briefcase от Artificial Analysis погружает модели ИИ в многонедельные проекты по работе со знаниями, построенные из тысяч фрагментированных исходных файлов — таких как цепочки сообщений Slack, электронные письма, расшифровки встреч и большие массивы экспортируемых данных.

Характер ошибок меняется по мере улучшения моделей. Более слабые модели захлебываются на базовом исполнении — пропускают нужные файлы или выдают непригодные результаты. Сильные модели терпят неудачу тише: они соблюдают очевидные требования, но упускают детали, которые можно заметить только собрав информацию из нескольких источников.
Существует также значительный разброс цен — стоимость одной задачи варьируется более чем 800‑кратно: от примерно $0,04 за использование DeepSeek V4 Flash до свыше $31 за Claude Fable 5.