Введение
Всё началось во вторник, который полностью выскользнул из-под контроля. Нужно было резюмировать три клиентских брифа, разобрать накопившиеся вкладки с исследованиями, ответить на несколько вдумчивых писем и продвинуть наполовину написанный технический документ, который висел открытым уже четвёртый день. К тому моменту, как я оторвался от бесконечных переключений между задачами, было уже за семь вечера, а по-настоящему ценного сделано почти ничего не было.
В тот вечер я не стал просто закрывать ноутбук, смирившись с поражением, а начал смотреть на проблему иначе. Не хватка времени — нехватка рычагов. Почти для каждой задачи, которой я занимался в тот день, существовал способ делегировать её чему-то более умному, чем закладка в браузере. Так я и начал строить.
Эта статья — честный рассказ о процессе: почему я создал собственного ИИ-ассистента, а не заплатил за готовое решение, как выглядит архитектура, настоящий код, что пошло не так и что теперь он реально умеет, на что я полагаюсь.
Почему «зачем» важнее «как»
Большинство тех, кто решает создавать ИИ-ассистента, начинают с поиска «Python LangChain tutorial». Это неправильный путь. Первый вопрос, с которым стоит разобраться: зачем вообще его строить, когда уже есть Siri, ChatGPT, Copilot и дюжина других инструментов?
Честный ответ для меня — контроль. Не в параноидальном смысле «отключиться от сети», а в практическом: любой готовый ассистент создан на основе чужих предположений о том, что вам нужно. Они универсальны по дизайну, а универсальность всегда требует компромиссов. Мне же нужно было что-то, что знает мой контекст, говорит в моём тоне, подключается к моим инструментам и остаётся в рамках рабочего процесса, которому я уже доверяю.
Есть ещё вопрос данных. Когда вы пользуетесь сторонним ассистентом, ваши запросы и контекст проходят через их инфраструктуру. Для личной продуктивности это, вероятно, нормально. А для клиентских или коммерчески чувствительных материалов всё становится мутнее. Создавая своё, вы сами решаете, где хранятся данные.
И ещё один довод, который часто недооценивают: вы понимаете инструмент гораздо лучше, когда строите его сами. Когда что-то ломается, вы знаете, где искать. Когда хотите добавить новую функцию, не ждёте обновления продукта.
Время также сыграло на руку. По данным MarketsandMarkets, рынок ИИ-ассистентов вырастет с $3,35 млрд в 2025 году до $21,11 млрд к 2030 — совокупный годовой рост на 44,5%. Такая траектория говорит о том, что эта технология — не просто тренд, а инфраструктура. Освоить её сейчас, строя, а не только потребляя, — значит оказаться впереди большинства через пару лет.
Тем не менее, строить — не всегда правильный выбор. Если нужен быстрый движок ответов или помощник по текстам за $20/месяц — покупайте. Но если хотите что-то, что интегрируется в ваш реальный рабочий процесс, учится на ваших предпочтениях и выполняет задачи специфичным для вас образом, — это стоит строить.
Выбор стека
Когда я решился строить, следующим шагом был выбор инструментов. Вот что я действительно рассматривал, а не общая сравнительная таблица.
- Выбор большой языковой модели свёлся к двум серьёзным вариантам: GPT-4o от OpenAI и Claude от Anthropic. Я протестировал оба на одинаковых запросах, связанных с исследованиями, письмом и рассуждениями. GPT-4o быстр, широко функционален и имеет зрелый API. Claude особенно хорошо работает с длинными документами и точно следует инструкциям. В итоге основным выбором стал GPT-4o — из-за надёжности вызова инструментов и зрелости экосистемы, а Claude оставлен как запасной вариант для некоторых задач с документами.
- Для оркестровки я выбрал LangChain. В кругах разработчиков идут споры, не добавляет ли LangChain слишком много абстракции, и эта критика не лишена оснований. Но для такого проекта — где нужны память, использование инструментов и цикл рассуждений — абстракции LangChain реально экономят время. Альтернатива — писать всё это руками, что возможно, но не на том стоит сосредотачиваться, когда цель — выпустить работающий продукт.
- Память была требованием с самого начала. Чат-бот без состояния, забывающий всё между сессиями, хорош для разовых вопросов, но не для настоящего ассистента.
ConversationBufferMemoryиз LangChain работал для контекста внутри сессии. Для долговременной памяти между сессиями я использовал подход с SQLite, который покажу в разделе с кодом. - Что касается инструментов, я дал ассистенту возможность искать в интернете (через API DuckDuckGo — ключ не требуется), читать и резюмировать переданные файлы, а также вызывать собственные функции Python, написанные для повторяющихся задач. Именно здесь заключается настоящая ценность: превращение чат-бота в то, что действительно может что-то делать.
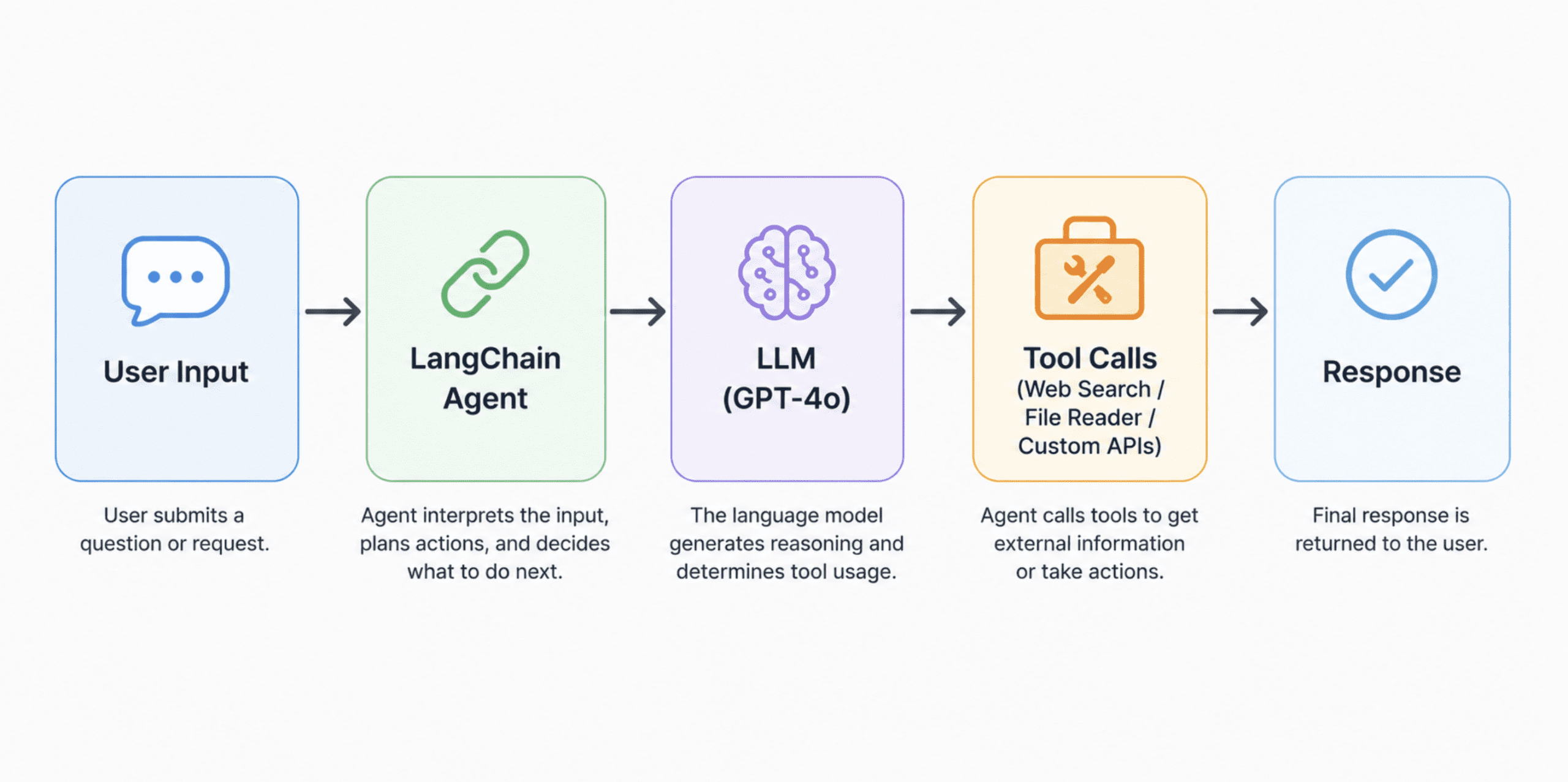
Настройка окружения
Прежде чем запускать код, нужно три вещи: Python 3.10 или выше, виртуальное окружение и безопасно сохранённые API-ключи.
Шаг 1: Создание и активация виртуального окружения
# Создаём виртуальное окружение с именем 'assistant_env'
python -m venv assistant_env
# Активируем на macOS/Linux
source assistant_env/bin/activate
# Активируем на Windows
assistant_env\Scripts\activateВиртуальное окружение изолирует зависимости проекта от всего остального на компьютере. Это важнее, чем кажется — конфликты зависимостей между проектами часто становятся незаметным источником ошибок.
Шаг 2: Установка необходимых пакетов
pip install langchain==0.3.0 \
langchain-openai \
langchain-community \
langgraph \
duckduckgo-search \
python-dotenv \
pydantic \
requestsВот что делает каждый пакет:
langchain— основной фреймворк, связывающий модель, память и инструменты.langchain-openai— коннектор для моделей OpenAI.langchain-community— даёт доступ к инструментам и интеграциям, созданным сообществом, включая поиск DuckDuckGo.langgraph— для более сложных, сохраняющих состояние агентных рабочих процессов.duckduckgo-search— позволяет ассистенту искать в интернете без API-ключа.python-dotenv— загружает API-ключи из файла.env, а не из жёстко зашитого кода.pydantic— обрабатывает валидацию данных для структурированных вводов и выводов.
Шаг 3: Безопасное хранение API-ключей
Никогда не вставляйте API-ключ прямо в скрипт. Создайте файл .env в корне проекта:
# .env файл — никогда не коммитьте его в систему контроля версий
OPENAI_API_KEY=your_openai_key_hereЗатем сразу добавьте .env в .gitignore:
# .gitignore
.env
assistant_env/
__pycache__/Создание ядра ассистента
Вот где всё собирается воедино. Я пройду по каждому компоненту в порядке его создания.
- Подключение к большой языковой модели
# assistant.py import os from dotenv import load_dotenv from langchain_openai import ChatOpenAI # Загружаем переменные окружения из .env load_dotenv() # Инициализируем языковую модель # temperature контролирует случайность: 0 — сфокусированно и детерминированно, 1 — более творчески # Для ассистента, которому нужна точность и последовательность, держите этот параметр низким (0.1–0.3) llm = ChatOpenAI( model="gpt-4o", temperature=0.2, api_key=os.getenv("OPENAI_API_KEY") )Что это делает:
ChatOpenAIустанавливает соединение с GPT-4o через API. Параметрtemperatureстоит понимать: при 0 модель всегда выбирает самый вероятный следующий токен, что даёт очень последовательные, но иногда жёсткие ответы. При 1 — гораздо более разнообразные и творческие. Для ассистента, ориентированного на задачи, значение от 0.1 до 0.3 обеспечивает надёжность без потери качества естественного языка. - Разработка системного промта
Системный промт — самая недооценённая часть всей сборки. Он определяет личность ассистента, его ограничения и то, как он ведёт себя в неоднозначных ситуациях. Потратьте на него больше времени, чем кажется нужным.
# Системный промт — это постоянные инструкции ассистента. # Он отправляется в начале каждого диалога, чтобы закрепить поведение. SYSTEM_PROMPT = """ Ты — сосредоточенный и надёжный персональный ассистент. Твоя задача — помогать пользователю исследовать темы, резюмировать документы, готовить черновики текстов и выполнять структурированные задания. Ты всегда: - Даёшь прямой ответ, прежде чем вдаваться в подробности - Говоришь, если не уверен, вместо того чтобы гадать - Уточняешь задачу, если она действительно неоднозначна - Отвечаешь кратко, если не запрошена дополнительная детализация У тебя есть доступ к веб-поиску, и ты можешь читать файлы, которые предоставляет пользователь. Используя эти инструменты, всегда указывай, откуда взята информация. Не выдумывай факты, не придумывай ссылки и не заполняй пробелы правдоподобными выдумками. """Что это делает: Этот промт отправляется перед каждым диалогом. Воспринимайте его как должностную инструкцию, которую вы даёте живому ассистенту в первый рабочий день. Чем он конкретнее, тем меньше придётся поправлять модель по ходу разговора. Расплывчатые инструкции всегда порождают расплывчатое поведение.
- Добавление памяти
Без памяти ассистент забывает всё, как только начинается новое сообщение. Вот как это исправить.
from langchain.memory import ConversationBufferMemory from langchain_community.chat_message_histories import SQLChatMessageHistory # SQLChatMessageHistory сохраняет историю разговора в локальную базу данных SQLite. # session_id позволяет вести отдельные цепочки памяти (например, по одной на проект). message_history = SQLChatMessageHistory( session_id="main_session", connection_string="sqlite:///assistant_memory.db" ) # ConversationBufferMemory оборачивает историю сообщений и передаёт её модели # на каждом шагу, чтобы модель знала, что было сказано ранее. memory = ConversationBufferMemory( memory_key="chat_history", chat_memory=message_history, return_messages=True )Что это делает:
SQLChatMessageHistoryсохраняет каждый обмен в локальный SQLite-файлassistant_memory.db. Это значит, что ассистент помнит контекст между сессиями.session_id— просто метка: можно создать несколько сессий для разных проектов или тем, и они останутся полностью разделёнными.Одно предостережение: буферная память хранит всю историю и в долгих разговорах может упереться в лимит контекста модели. Для продакшена лучше использовать
ConversationSummaryMemory— она сжимает старую историю в краткое резюме, чтобы оставаться в пределах токенов. - Предоставление инструментов
Это то, что отличает чат-бота от ассистента. Инструменты позволяют модели совершать реальные действия.
from langchain.agents import AgentExecutor, create_openai_tools_agent from langchain_community.tools import DuckDuckGoSearchRun from langchain.tools import tool from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder # Инструмент 1: Веб-поиск через DuckDuckGo — не требует API-ключа search_tool = DuckDuckGoSearchRun() # Инструмент 2: Пользовательское средство чтения файлов # Декоратор @tool регистрирует эту функцию как то, что агент может вызывать @tool def read_file(file_path: str) -> str: """Читает текстовый файл по указанному пути и возвращает его содержимое. Используй, когда пользователь просит прочитать, проанализировать или резюмировать файл.""" try: with open(file_path, "r", encoding="utf-8") as f: return f.read() except FileNotFoundError: return f"Файл не найден: {file_path}" except Exception as e: return f"Ошибка при чтении файла: {str(e)}" # Регистрируем инструменты, доступные агенту tools = [search_tool, read_file] # Строим шаблон промта # MessagesPlaceholder подставляет память (chat_history) и черновик агента prompt = ChatPromptTemplate.from_messages([ ("system", SYSTEM_PROMPT), MessagesPlaceholder(variable_name="chat_history"), ("human", "{input}"), MessagesPlaceholder(variable_name="agent_scratchpad") ]) # Создаём агента — это связывает модель, инструменты и промт agent = create_openai_tools_agent(llm, tools, prompt) # AgentExecutor — это цикл выполнения: он вызывает агента, запускает выбранные инструменты, # передаёт результаты обратно и повторяет, пока не получит окончательный ответ agent_executor = AgentExecutor( agent=agent, tools=tools, memory=memory, verbose=True, # Для продакшена ставьте False; True показывает шаги рассуждения max_iterations=5 # Предотвращает зацикливание на сложных задачах )Что это делает:
AgentExecutor— это движок. Когда вы отправляете сообщение, он не просто передаёт его модели и возвращает что попало. Он запускает цикл: модель решает, нужен ли инструмент, вызывает его, получает результат, обдумывает следующий шаг и возвращает окончательный ответ только когда удовлетворена. Это паттерн ReAct (Reasoning + Acting) на практике.
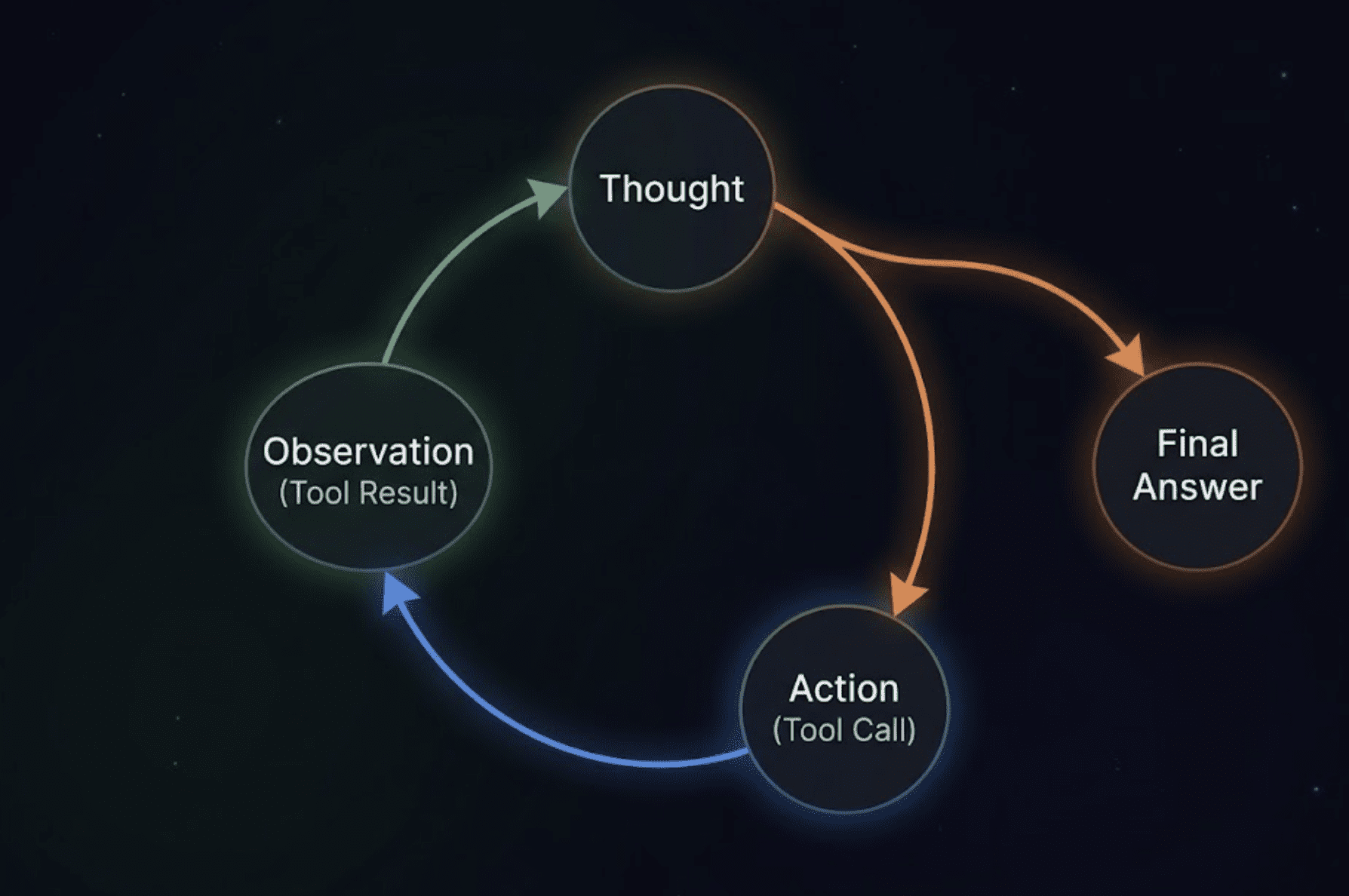
Собирая всё вместе, главный цикл выполнения:
def chat(user_input: str) -> str:
"""Отправляет сообщение ассистенту и получает ответ.
Память обрабатывается автоматически через agent_executor."""
try:
response = agent_executor.invoke({"input": user_input})
return response["output"]
except Exception as e:
# Вежливая обработка ошибок — сообщает, что сломалось, не роняя сессию
return f"Что-то пошло не так: {str(e)}. Пожалуйста, попробуйте снова или переформулируйте запрос."
# Простой интерфейс командной строки для запуска ассистента
if __name__ == "__main__":
print("Ассистент готов. Для выхода наберите 'quit'.\n")
while True:
user_input = input("Вы: ").strip()
if user_input.lower() in ["quit", "exit", "q"]:
print("До свидания.")
break
if not user_input:
continue
response = chat(user_input)
print(f"\nАссистент: {response}\n")Что это делает: Функция chat() — единая точка входа для всей системы. Вы передаёте ей строку, она обрабатывает всё — извлечение из памяти, вызов инструментов, рассуждение модели, обработку ошибок — и возвращает строку. Блок if __name__ == "__main__" превращает весь скрипт в работающего ассистента командной строки, который можно запустить сразу через python assistant.py.
Тестирование и исправление ошибок
При первом запуске ассистент выдал уверенный, но фактически неверный ответ, проигнорировал инструмент, который должен был использовать, и оформил ответ так, как мне не понравилось. Ничего необычного. Это не значит, что сборка сломана — это начало настоящей работы.
Самое важное, что нужно протестировать в первую очередь, — действительно ли агент использует инструменты, когда должен. Частая ошибка: модель пытается ответить по памяти, хотя следовало бы поискать, потому что системный промт недостаточно явно это требует. Я исправил это, добавив в системный промт:
Отвечая на вопросы о недавних событиях, текущих данных или чём-то, что зависит от времени, всегда используй веб-поиск. Не полагайся на свои обучающие данные для фактов, которые могли измениться.Об обработке ошибок: это важнее, чем признают многие руководства. Согласно исследованию Mordor Intelligence, почти половина сгенерированного ИИ кода не проходит первую проверку безопасности. Тот же принцип применим к ответам ИИ — вывод должен рассматриваться как черновик, а не окончательный ответ, пока вы не убедились в надёжности для конкретного типа задач. Блок try/except в функции chat() выше — это начало, но вы захотите расширить его по мере обнаружения специфичных сбоев.
Для более структурированного тестирования напишите тестовые сценарии:
# test_assistant.py
# Запускайте, чтобы проверить, ведёт ли себя ассистент как ожидается, перед развёртыванием
test_cases = [
{
"input": "Какова текущая цена биткойна?",
"expected_behavior": "Должен использовать веб-поиск, а не отвечать по памяти"
},
{
"input": "Резюмируй файл /tmp/test_document.txt",
"expected_behavior": "Должен вызвать инструмент read_file"
},
{
"input": "О чём я спрашивал пять сообщений назад?",
"expected_behavior": "Должен корректно обратиться к памяти разговора"
}
]
for case in test_cases:
print(f"Тестируем: {case['input']}")
print(f"Ожидаемое поведение: {case['expected_behavior']}")
result = chat(case["input"])
print(f"Получено: {result[:200]}...") # Выводим первые 200 символов ответа
print("---")Запускайте эти тесты после каждого изменения системного промта или конфигурации инструментов. Небольшие правки промта часто имеют неожиданные последующие эффекты.
Полный код
Всё вышеописанное было разобрано по частям. Здесь оно собрано в один полный файл, готовый к копированию. Сохраните как assistant.py, убедитесь, что файл .env в той же директории, и запускайте python assistant.py.
# assistant.py
# Полноценный ИИ-ассистент — построен на LangChain, GPT-4o, DuckDuckGo Search и памяти SQLite
# Требования: Python 3.10+ | Установка: pip install langchain==0.3.0 langchain-openai
# langchain-community langgraph duckduckgo-search python-dotenv pydantic requests
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain.memory import ConversationBufferMemory
from langchain_community.chat_message_histories import SQLChatMessageHistory
from langchain.agents import AgentExecutor, create_openai_tools_agent
from langchain_community.tools import DuckDuckGoSearchRun
from langchain.tools import tool
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
# ──────────────────────────────────────────────
# 1. ЗАГРУЗКА ПЕРЕМЕННЫХ ОКРУЖЕНИЯ
# ──────────────────────────────────────────────
# Читает OPENAI_API_KEY из вашего .env файла.
# Никогда не записывайте ключи прямо в исходный код.
load_dotenv()
# ──────────────────────────────────────────────
# 2. ИНИЦИАЛИЗАЦИЯ ЯЗЫКОВОЙ МОДЕЛИ
# ──────────────────────────────────────────────
# temperature=0.2 сохраняет ответы сфокусированными и последовательными.
# Повышайте к 1.0, если хотите более творческий, разнообразный вывод.
llm = ChatOpenAI(
model="gpt-4o",
temperature=0.2,
api_key=os.getenv("OPENAI_API_KEY")
)
# ──────────────────────────────────────────────
# 3. ОПРЕДЕЛЕНИЕ СИСТЕМНОГО ПРОМТА
# ──────────────────────────────────────────────
# Это постоянный набор инструкций ассистента.
# Он влияет на поведение на каждом ходе — отнеситесь к нему тщательно.
SYSTEM_PROMPT = """
Ты — сосредоточенный и надёжный персональный ассистент. Твоя задача — помогать пользователю исследовать темы, резюмировать документы, готовить черновики текстов и выполнять структурированные задания. Ты всегда:
- Даёшь прямой ответ, прежде чем вдаваться в подробности
- Говоришь, если не уверен, вместо того чтобы гадать
- Уточняешь задачу, если она действительно неоднозначна
- Отвечаешь кратко, если не запрошена дополнительная детализация
У тебя есть доступ к веб-поиску, и ты можешь читать файлы, которые предоставляет пользователь. Используя эти инструменты, всегда указывай, откуда взята информация. Отвечая на вопросы о недавних событиях, текущих данных или чём-то, что зависит от времени, всегда используй веб-поиск. Не полагайся на свои обучающие данные для фактов, которые могли измениться. Не выдумывай факты, не придумывай ссылки и не заполняй пробелы правдоподобными выдумками.
"""
# ──────────────────────────────────────────────
# 4. НАСТРОЙКА ПОСТОЯННОЙ ПАМЯТИ
# ──────────────────────────────────────────────
# SQLChatMessageHistory сохраняет историю разговора в локальную базу SQLite.
# Это значит, что ассистент помнит контекст между сессиями, а не только внутри одной.
# Меняйте session_id, чтобы вести отдельные цепочки памяти (например, по проектам).
message_history = SQLChatMessageHistory(
session_id="main_session",
connection_string="sqlite:///assistant_memory.db"
)
# ConversationBufferMemory оборачивает историю сообщений и внедряет её
# в каждый промт, чтобы у модели всегда был полный контекст разговора.
# Примечание: для очень длинных диалогов замените на ConversationSummaryMemory,
# чтобы не выходить за лимит токенов модели.
memory = ConversationBufferMemory(
memory_key="chat_history",
chat_memory=message_history,
return_messages=True
)
# ──────────────────────────────────────────────
# 5. ОПРЕДЕЛЕНИЕ ИНСТРУМЕНТОВ
# ──────────────────────────────────────────────
# Инструмент 1: Веб-поиск через DuckDuckGo — не требует API-ключа
search_tool = DuckDuckGoSearchRun()
# Инструмент 2: Пользовательский читатель файлов
# Декоратор @tool регистрирует эту функцию Python как вызываемый инструмент,
# который агент может задействовать, когда пользователь просит прочитать файл.
@tool
def read_file(file_path: str) -> str:
"""Читает текстовый файл по указанному пути и возвращает его содержимое.
Используй, когда пользователь просит прочитать, проанализировать или резюмировать файл."""
try:
with open(file_path, "r", encoding="utf-8") as f:
return f.read()
except FileNotFoundError:
return f"Файл не найден: {file_path}"
except Exception as e:
return f"Ошибка при чтении файла: {str(e)}"
# Собираем все инструменты в список — добавляйте сюда новые по мере создания
tools = [search_tool, read_file]
# ──────────────────────────────────────────────
# 6. СБОРКА АГЕНТА
# ──────────────────────────────────────────────
# Шаблон промта структурирует каждое сообщение, отправляемое модели.
# MessagesPlaceholder подставляет память (chat_history) и внутренний
# черновик рассуждений агента на каждом шагу.
prompt = ChatPromptTemplate.from_messages([
("system", SYSTEM_PROMPT),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# create_openai_tools_agent связывает вместе модель, инструменты и промт
# в единого агента, который знает, как решать, когда и какие инструменты вызывать.
agent = create_openai_tools_agent(llm, tools, prompt)
# AgentExecutor — это цикл выполнения.
# Он вызывает агента, запускает любые выбранные им инструменты, подаёт результаты обратно
# и повторяет, пока не достигнет окончательного ответа (или не достигнет max_iterations).
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True, # В продакшене ставьте False; True показывает шаги рассуждения
max_iterations=5 # Предотвращает бесконечное зацикливание на сложных задачах
)
# ──────────────────────────────────────────────
# 7. ФУНКЦИЯ CHAT
# ──────────────────────────────────────────────
def chat(user_input: str) -> str:
"""Отправляет сообщение ассистенту и получает ответ.
Управление памятью, использование инструментов и обработка ошибок происходят здесь."""
try:
response = agent_executor.invoke({"input": user_input})
return response["output"]
except Exception as e:
# Возвращает читаемое сообщение об ошибке, не обрушивая сессию.
# В продакшене стоит записывать полное исключение в лог для отладки.
return f"Что-то пошло не так: {str(e)}. Пожалуйста, попробуйте снова или переформулируйте запрос."
# ──────────────────────────────────────────────
# 8. ИНТЕРФЕЙС КОМАНДНОЙ СТРОКИ
# ──────────────────────────────────────────────
# Запустите этот файл напрямую, чтобы начать сессию в командной строке: python assistant.py
# Чтобы обернуть в браузерный интерфейс, смотрите Gradio или Streamlit в части 7.
if __name__ == "__main__":
print("Ассистент готов. Для выхода наберите 'quit'.\n")
while True:
user_input = input("Вы: ").strip()
if user_input.lower() in ["quit", "exit", "q"]:
print("До свидания.")
break
if not user_input:
continue
response = chat(user_input)
print(f"\nАссистент: {response}\n")Результаты
После примерно двух недель регулярного использования вот что ассистент теперь реально делает для меня:
- Синтез исследований: я даю ему тему и три-пять URL, и он извлекает ключевые моменты в структурированное резюме. То, что раньше занимало 45 минут, теперь занимает около 4 минут, оставшееся время уходит на собственную проверку и суждение.
- Генерация черновиков: первые варианты писем, резюме и структурированных документов. Результат не финальный, и я этого не жду, но иметь что редактировать гораздо быстрее, чем начинать с чистого листа каждый раз.
- Переваривание файлов: я скидываю заметки со встреч, PDF и файлы логов в папку и прошу извлечь конкретную информацию. С этим ассистент справляется надёжно, если файлы текстовые и примерно до 50 000 слов.
Экономия времени реальна. Данные анализа DX, охватившего более 135 000 разработчиков, показали в среднем 3,6 сэкономленных часа в неделю при использовании ИИ-инструментов, а у ежедневных пользователей результаты ещё выше. Мой опыт укладывается в этот диапазон для насыщенных задач, хотя сильно варьируется в зависимости от типа работы.
Заключение
Тот вторник, с которого я начал рассказ — когда я проработал весь день и почти ничего не сделал — всё ещё случается. Но реже, и когда такое происходит, это редко бывает из-за того, что я застрял не на том типе работы. Ассистент берёт на себя те части работы, которые не требуют именно меня, освобождая время для того, что требует.
Чего я не ожидал — так это того, что сам процесс создания изменил моё восприятие работы. Когда вы отвечаете за инструмент, вы начинаете иначе замечать трение. Вы начинаете чаще спрашивать: «Можно ли это делегировать?» — а это полезная умственная привычка, независимо от того, участвует ИИ или нет.
Порог для создания чего-то подобного ниже, чем кажется. Полноценный работающий ассистент, представленный выше, — это меньше 150 строк Python, используются свободно доступные фреймворки, и работает на любой машине с Python. Самое сложное — решить, что вы на самом деле хотите, чтобы он делал, и над этим вопросом стоит тщательно подумать, потому что сфокусированный ассистент всегда превосходит универсального.
Начните с малого. Дайте ему одну задачу. Добавляйте сложность только тогда, когда исчерпали ценность на простом уровне. Этот подход работает и для инструментов, и для формирования привычек вокруг них.