Китайская компания MiniMax представила модель M2.7, которая активно включилась в процесс своего создания. Благодаря автономным циклам оптимизации она повысила эффективность обучения и достигла конкурентных показателей в тестах.
В ходе работы M2.7 обновляла свои базы знаний, разрабатывала десятки сложных функций в инфраструктуре агентов и совершенствовала обучение на основе вознаграждений самостоятельно. Полученные итоги модель применила для доработки собственного процесса обучения.
MiniMax называет M2.7 первой моделью, которая глубоко вовлеклась в свою эволюцию, и описывает перспективы, где будущие ИИ будут полностью автономно управлять сбором данных, обучением моделей, архитектурой вывода, оценкой и другими этапами без участия людей.

MiniMax не единственная, кто пробует такой подход. Недавно OpenAI анонсировала модель GPT-5.3 Codex для кодирования с похожими заявлениями об ИИ-помощи в разработке. По словам OpenAI, команда Codex применяла ранние версии модели для поиска ошибок в обучении, управления развертыванием и анализа тестов. Они удивились, насколько Codex ускорил свой собственный процесс создания.
Более 100 автономных циклов оптимизации демонстрируют возможности самосовершенствующегося ИИ
Чтобы проверить пределы самооптимизации, в MiniMax развернули внутреннюю версию M2.7 в системе исследовательских агентов, взаимодействующих с проектными командами компании. Агент занимается поиском литературы, отслеживанием экспериментов, отладкой, анализом метрик и исправлением кода в повседневной работе команды RL. Люди вмешиваются только на ключевых решениях. Модель покрывает 30–50 процентов всего рабочего процесса.
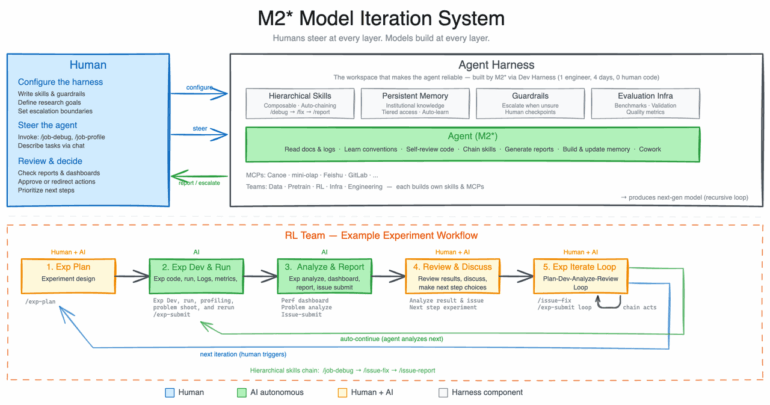
В одном эксперименте M2.7 полностью самостоятельно оптимизировала производительность модели в кодинге в внутренней среде за более чем 100 итераций. На каждом шаге она разбирала неудачи, планировала правки, корректировала код, тестировала итоги и решала, сохранять изменения или откатывать. MiniMax сообщает о росте производительности на 30 процентов по внутренним тестам.
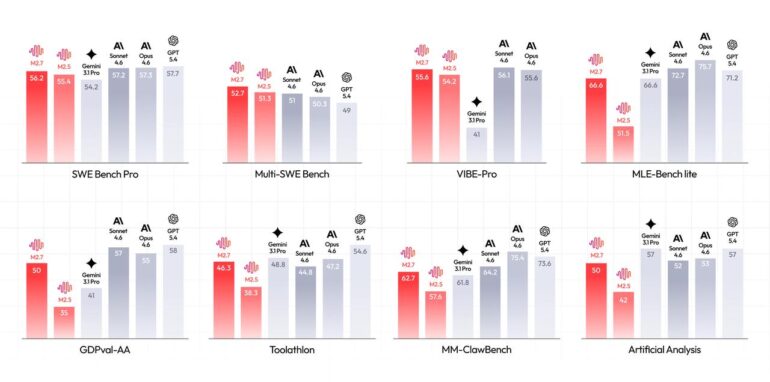
В 22 соревнованиях по машинному обучению из MLE-Bench Lite за три 24-часовых запуска M2.7 получила средний медальный рейтинг 66,6 процента. Это ставит ее позади Opus 4.6 (75,7 процента) и GPT-5.4 (71,2 процента), но на уровне Gemini 3.1, по данным компании.
Бенчмарки дают полезные ориентиры, но не всегда отражают реальные сценарии. Результаты на стандартных тестах могут сильно отличаться от повседневных задач, они зависят от условий тестирования, форматирования запросов и оптимизации модели. Такие цифры стоит воспринимать как приблизительные ориентиры, а не абсолютные меры способностей.
M2.7 не уступает ведущим западным моделям в программировании и офисных задачах
По утверждению MiniMax, M2.7 показывает результаты на уровне топовых западных моделей в бенчмарках по разработке ПО. На SWE-Pro — 56,22 процента, близко к GPT-5.3-Codex. На VIBE-Pro для полной доставки проектов — 55,6 процента. В реальных случаях M2.7 сокращала время восстановления после сбоев в продакшене до менее трех минут несколько раз.
Для офисной работы M2.7 набрала ELO 1495 на GDPval-AA — лучший результат среди моделей с открытыми весами, по версии MiniMax. Модель точно справляется с многоуровневыми правками в Word, Excel и PowerPoint, сохраняя 97 процентов верности правилам по более чем 40 сложным наборам инструкций.
Как пример, MiniMax приводит финансовый анализ TSMC: M2.7 самостоятельно изучила годовые отчеты, создала модель прогноза продаж и оформила результаты в презентацию с исследовательским отчетом. Специалисты по финансам отметили, что вывод годится как черновик.
Открытый демо-проект переносит взаимодействие с ИИ в графическую среду
Помимо продуктивности, MiniMax повысила в модели последовательность персонажей и эмоциональный интеллект. Для демонстрации компания выложила OpenRoom — открытый проект, переносящий общение с ИИ в графическую веб-среду, где персонажи сами взаимодействуют с окружением. M2.7 доступна через MiniMax Agent и API-платформу, в отличие от прошлых версий веса пока не опубликованы.
Юрген Шмидхубер заложил теоретическую основу самосовершенствующегося ИИ в 2003 году с концепцией "машины Гёделя", которая меняет свой код только при формальном доказательстве пользы. Проекты вроде "Darwin-Gödel Machine" от Sakana AI и "Huxley-Gödel Machine" из лаборатории Шмидхубера в KAUST применяют прагматичный метод: агенты ИИ итеративно меняют код и отбирают лучшие варианты эволюционно.