Специалисты из четырех американских университетов разработали фреймворк, который совершенствует ИИ-агентов прямо в процессе работы. Он ориентируется на записи в Google Calendar, чтобы определить подходящее время для обучения.
Обычно ИИ-агенты на базе больших языковых моделей проходят обучение один раз и потом работают без изменений. Однако требования пользователей меняются, а модель не подстраивается под них.
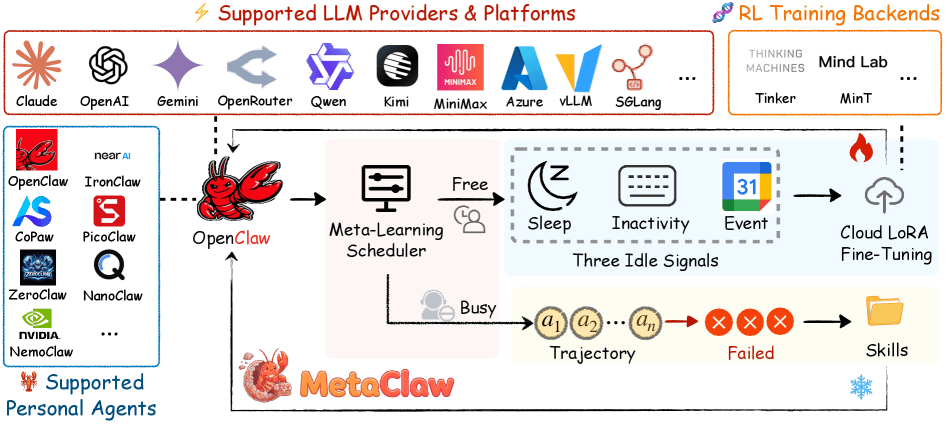
Ученые из UNC-Chapel Hill, Carnegie Mellon University, UC Santa Cruz и UC Berkeley предлагают решение в виде MetaClaw. Этот фреймворк непрерывно развивает ИИ-агента, извлекая уроки из собственных промахов, причем без заметных для пользователя сбоев и простоев сервиса.
Неудачные задания превращаются в правила поведения
Первый механизм активируется при любой ошибке агента. Отдельная языковая модель разбирает провальную последовательность действий и выводит из нее краткое правило поведения. Это правило сразу добавляется в системный промт агента и начинает действовать для всех последующих заданий. Сама модель при этом не меняется, а сервис продолжает работать без перерыва.
Как указано в статье, процесс порождает три ключевых вида правил: правильная нормализация форматов времени, создание резервных копий перед опасными операциями с файлами и соблюдение правил именования. Поскольку правила универсальны и не привязаны к конкретному заданию, одна ошибка может улучшить выполнение множества других задач в будущем.
Обучение запускается, когда пользователь не смотрит
Второй механизм корректирует веса модели с помощью обучения с подкреплением и облачного дообучения LoRA. Такие обновления ненадолго прерывают работу агента, поэтому проводить их нельзя, пока пользователь активно взаимодействует с системой.
Чтобы обойти это, авторы внедрили фоновый процесс OMLS (Opportunistic Meta-Learning Scheduler). Он отслеживает три индикатора: заданное время сна, отсутствие ввода с клавиатуры и мыши на уровне ОС, а также события в Google Calendar. Если календарь показывает встречу, открывается окно для тренировки. Процесс можно приостанавливать и возобновлять, так что даже короткие паузы используются эффективно.
Система четко разделяет данные, собранные до введения нового правила, и после него. В обучение попадают только свежие данные. Иначе модель получит штраф за ошибки, которые правило уже устранило.
По словам разработчиков, механизмы усиливают друг друга: улучшенная модель генерирует более ценную информацию об ошибках, что приводит к качественным правилам. А те, в свою очередь, обеспечивают лучшие данные для следующих обновлений весов.
Слабая модель почти догоняет лидера
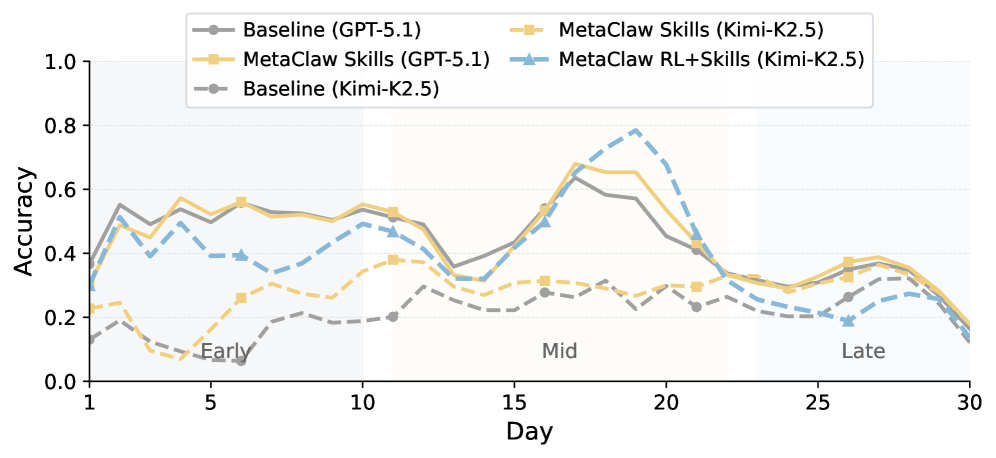
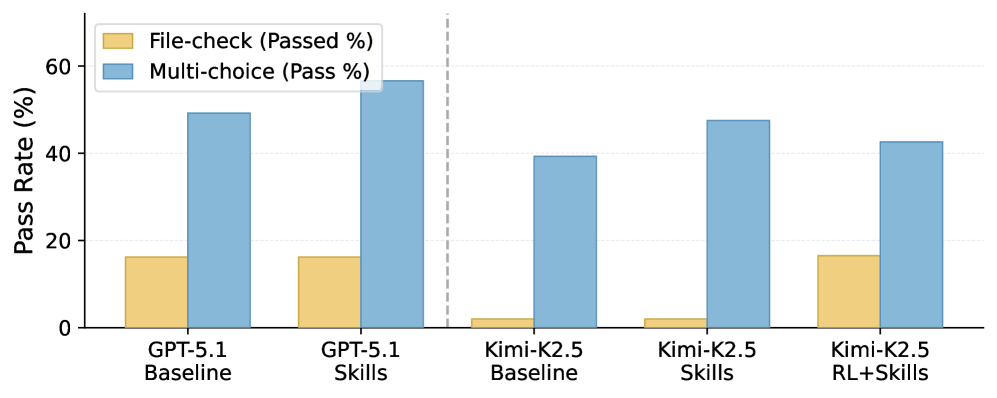
Тестирование MetaClaw прошло на специальном бенчмарке из 934 вопросов за 44 симулированных рабочих дня с моделями GPT-5.2 и Kimi-K2.5. Только правила поведения повышают точность Kimi-K2.5 относительно на 32 процента. Полный фреймворк поднимает ее с 21,4 до 40,6 процента — почти до базовых 41,1 процента GPT-5.2. Количество полностью решенных задач вырастает в 8,25 раза.
Этот эффект наблюдается повсеместно, отмечают авторы статьи: слабым моделям выгода больше, поскольку им не хватает процедурных знаний, которые добавляют правила. GPT-5.2 стартует с высокого уровня и имеет меньше пространства для роста.
Чтобы подтвердить применимость за пределами CLI-задач, фреймворк подключили к AutoResearchClaw. Эта цепочка самостоятельно проходит 23 шага от обзора литературы до экспериментов и готовой статьи. Одни правила поведения, без дообучения модели, снижают повторяемость шагов на 24,8 процента и количество циклов доработки на 40 процентов.
Симулированный бенчмарк имеет ограничения
Разработчики признают: их бенчмарк — симуляция, а не реальные сессии пользователей. Сырые показатели не переносятся напрямую в боевые условия. Кроме того, распознавание окон простоя зависит от настроек пользователя. Код доступен на GitHub. MetaClaw не требует локального GPU и работает через прокси к облачным endpoint'ам.
Недавно исследователи из Princeton University представили OpenClaw-RL — похожий фреймворк для улучшения ИИ-агентов в реальном времени. OpenClaw-RL использует отклики из каждого взаимодействия, такие как ответы пользователя или результаты тестов, как источник для обучения. MetaClaw опирается на инфраструктуру OpenClaw, но идет другим путем: отделяет быстрое добавление правил в промт от отложенной оптимизации весов в периоды простоя.