Крупные модели рассуждений нередко продолжают размышлять далеко за пределами правильного ответа: перепроверяют, перефразируют и удостоверяются в уже верном решении. Новое исследование Bytedance подтверждает, что модели сами понимают момент завершения. Стандартные способы генерации просто не дают им прерваться.
Такая особенность известна давно. На бенчмарке AIME 2025 Deepseek-R1 создаёт ответы почти в пять раз длиннее, чем у Claude 3.7 Sonnet, сохраняя похожий уровень точности. QwQ-32B опережает на два процента пункта самыми краткими вариантами, тратя на 31% меньше токенов. При этом в 72% случаев, когда появлялись как верные, так и ошибочные варианты, именно удлинённый ответ оказывался неверным.
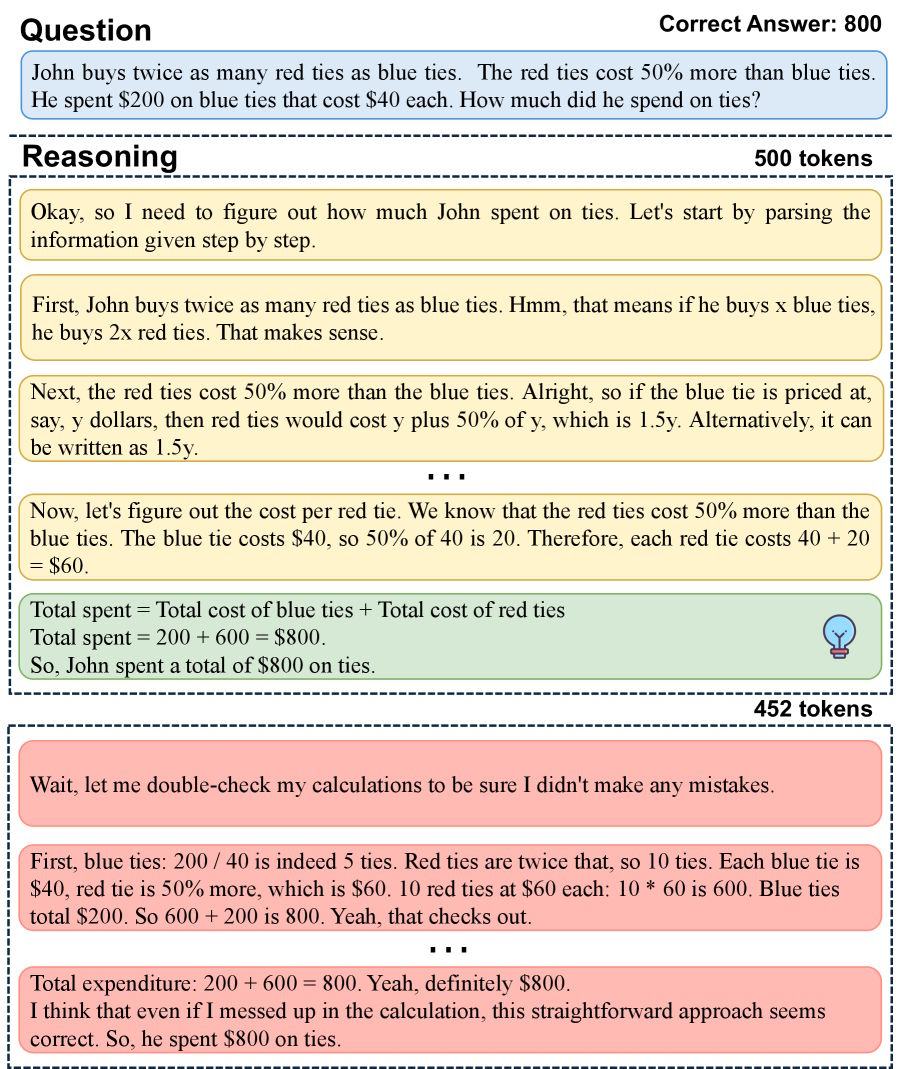
Ответ уже готов, а модель всё говорит
Для оценки масштаба проблемы авторы ввели показатель RFCS (Ratio of the First Correct Step), который фиксирует положение первого верного шага в цепочке рассуждений относительно полной длины. На датасете MATH-500 правильное решение возникает задолго до финала более чем в половине задач, решённых успешно.
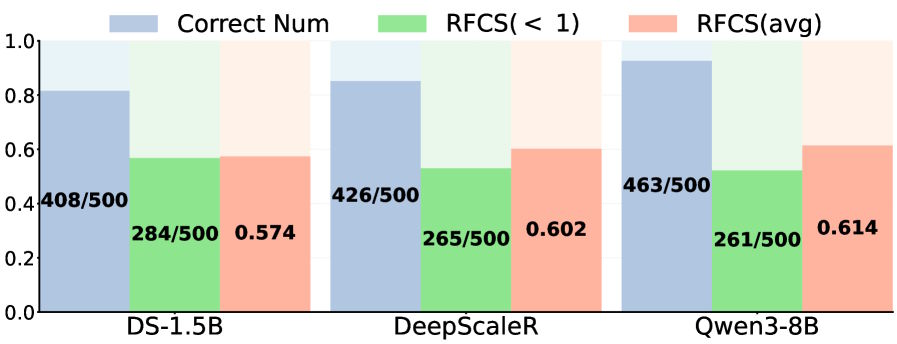
В конкретном случае модель достигла цели за 500 токенов, но потратила следующие 452 на перепроверки, перефразировки и лишние подтверждения верного результата. Подобное поведение проявляется как в компактных вариантах вроде Deepseek-R1-Distill-Qwen-1.5B, так и в масштабных, таких как Qwen3-8B. Даже усиленная доработка после базового обучения не устраняет дефект.
Модели чувствуют завершение; сэмплинг — нет
При параллельном ведении нескольких цепочек рассуждений во время инференса модели стабильно отбирают краткие и точные траектории, которым приписывают высокую уверенность. Об этом свидетельствует TSearch — подход, усредняющий вероятности по всей цепочке вместо отдельных токенов.
Три ключевых вывода: отобранные пути короче и вернее. У их финальных точек сигнал остановки стабильно лидирует среди кандидатов на следующий токен — модель понимает, что выполнена. Увеличение числа параллельных ветвей усиливает эту закономерность. Способность timely завершаться заложена в самих моделях; повседневные методы генерации её игнорируют.
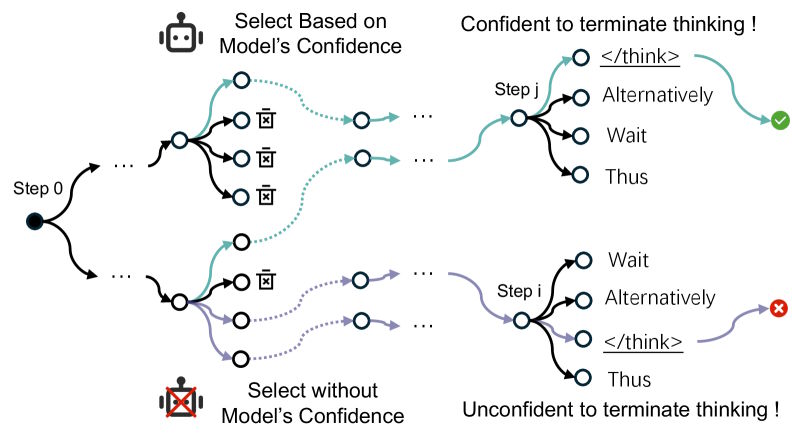
SAGE продвигается шагами, а не токенами
Предложенное решение — SAGE (Self-Aware Guided Efficient Reasoning). В отличие от поэлементного роста, SAGE удлиняет цепочки полноценными шагами рассуждений и после каждого сверяет наличие сигнала завершения. При положительном ответе процесс прерывается.
В тестах SAGE адаптировался к условиям: мощные модели на трудных наборах данных повышали верность. Слабые на лёгких существенно укорачивали выводы. По сути, метод устранял переизбыток и раскрывал резерв, где он был.
Для закрепления паттернов введён SAGE-RL — модификация обычного обучения с подкреплением. В каждой группе из восьми сгенерированных ответов два получены SAGE, шесть — стандартным способом. Через механизм преимущества модель осваивает приоритет компактных траекторий.
По шести математическим наборам данных, включая MATH-500, AIME 2024 и 2025, OlympiadBench, результаты схожи: альтернативы вроде LC-R1, ThinkPrune или AdaptThink сберегают токены за счёт снижения качества. SAGE-RL поднимает оба параметра. На Deepseek-R1-Distill-Qwen-7B вариант SAGE-GRPO достиг 93% на MATH-500 против 91,6%, уменьшив объём с 3871 до 2141 токена.
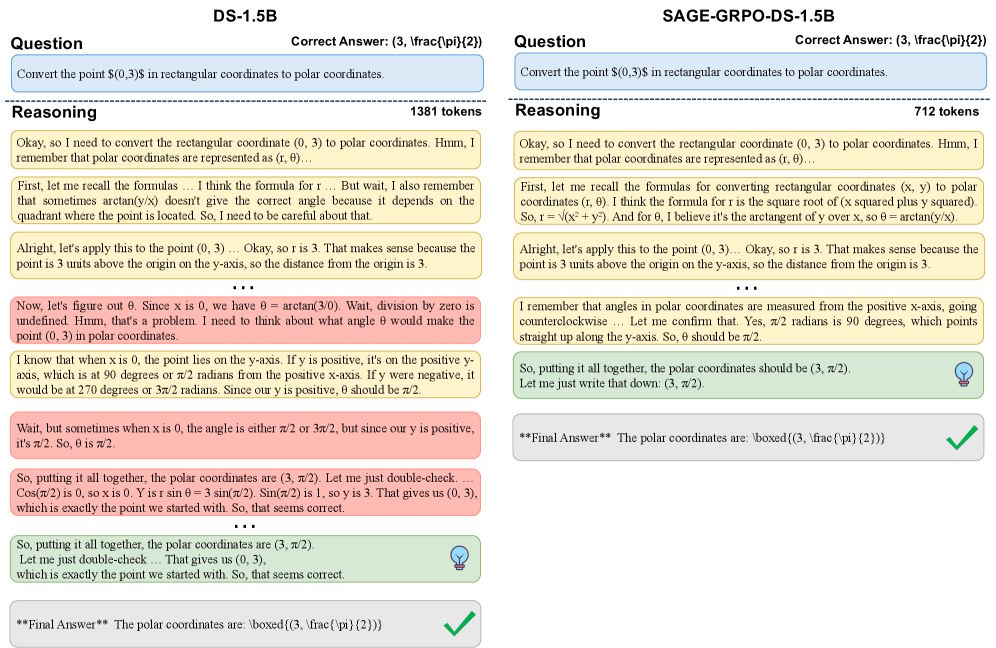
На AIME 2025 точность DS-1.5B подскочила на 6,2 процентных пункта. Сильная Qwen3-8B сократила ответы вдвое — с 18342 до 9183 токенов, не уступив в качестве. Время обработки сократилось более чем на 40% для большинства комбинаций моделей и тестов.
Наибольший эффект заметен на особо сложных примерах — именно там скрыт основной потенциал оптимизации. Устранение передумывания может обойтись без свежих архитектур или хитрых функций вознаграждения. Достаточно уважать сигналы моделей о готовности.
Избыточные размышления моделей — тема давних исследований. Год назад анализ выявил, что чрезмерное «мышление» в диалоговых режимах существенно бьёт по эффективности. Свежие работы Google раскрыли: цепочки строятся как дебаты между внутренними ролями, что усиливает точность ценой растянутости.