Качественное исследование разбирает, как разработчики относятся к низкокачественному контенту от ИИ, известному как «ИИ-шлак», и сопротивляются ему в процессе создания софта. Критики сравнивают ситуацию с трагедией общин: личный рост продуктивности вредит ревьюерам и сообществу open source.
Ученые из Университета Хайдельберга, Университета Мельбурна и Сингапурского управления университетом изучили, как разработчики, считающие контент от ИИ проблемой, аргументируют свою позицию и организуют критику. Они проанализировали 1154 поста из 15 обсуждений на Reddit и Hacker News.
Фокус исследования — треды с упоминанием термина «AI slop». Поэтому выборка сильно смещена в сторону негативных мнений. Положительные или нейтральные случаи использования генерации кода ИИ намеренно исключены. Получается картина аргументов именно критической группы, а не всего сообщества разработчиков.
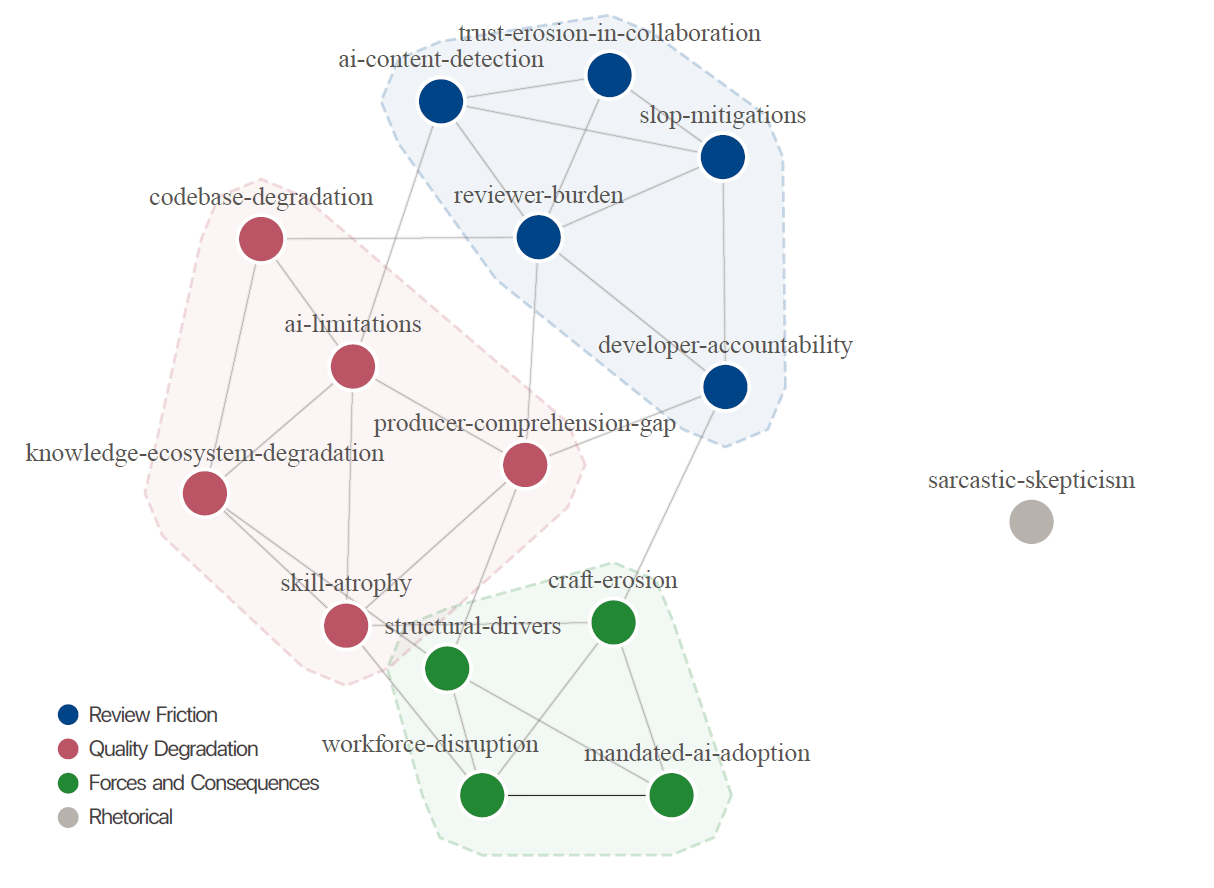
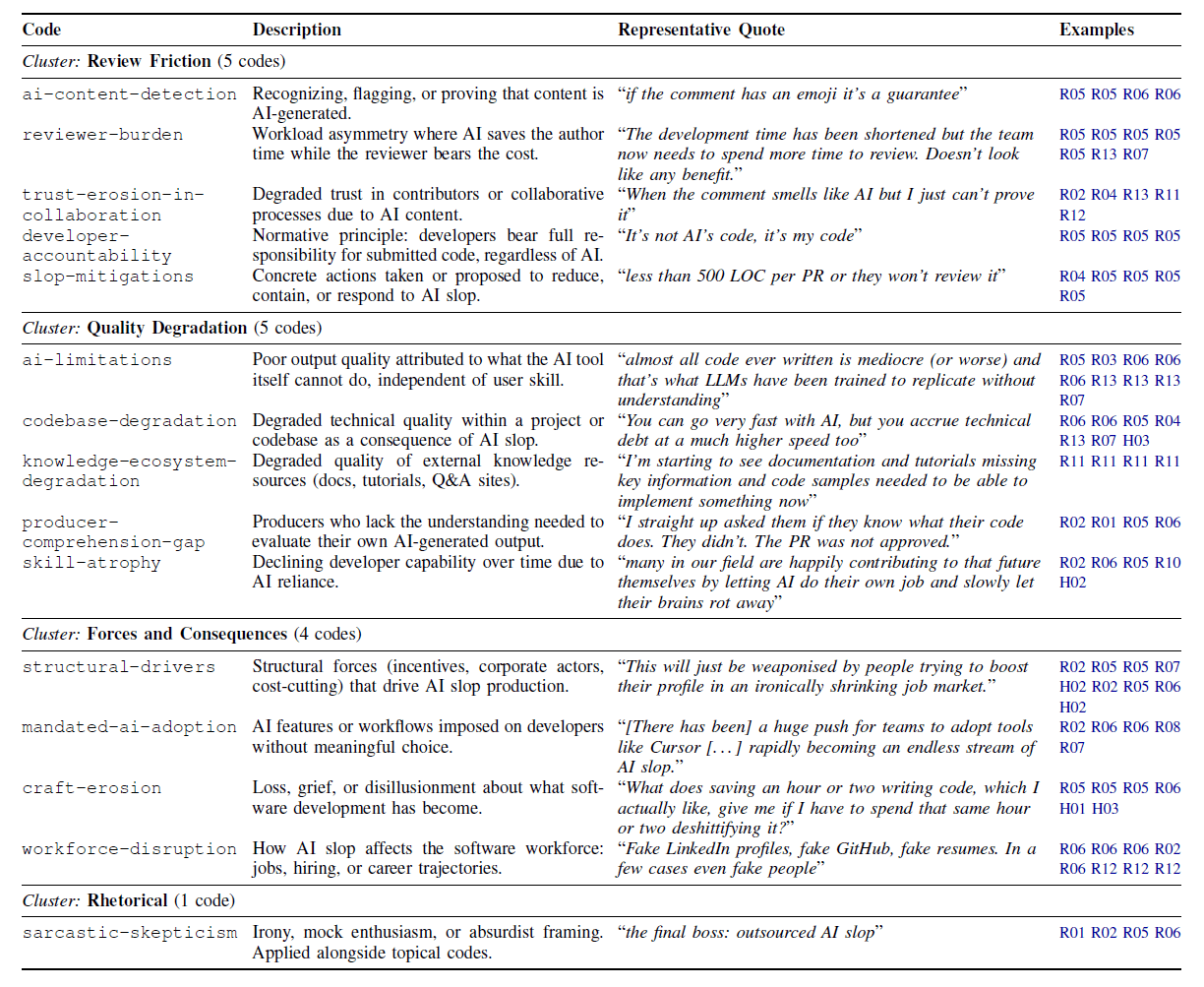
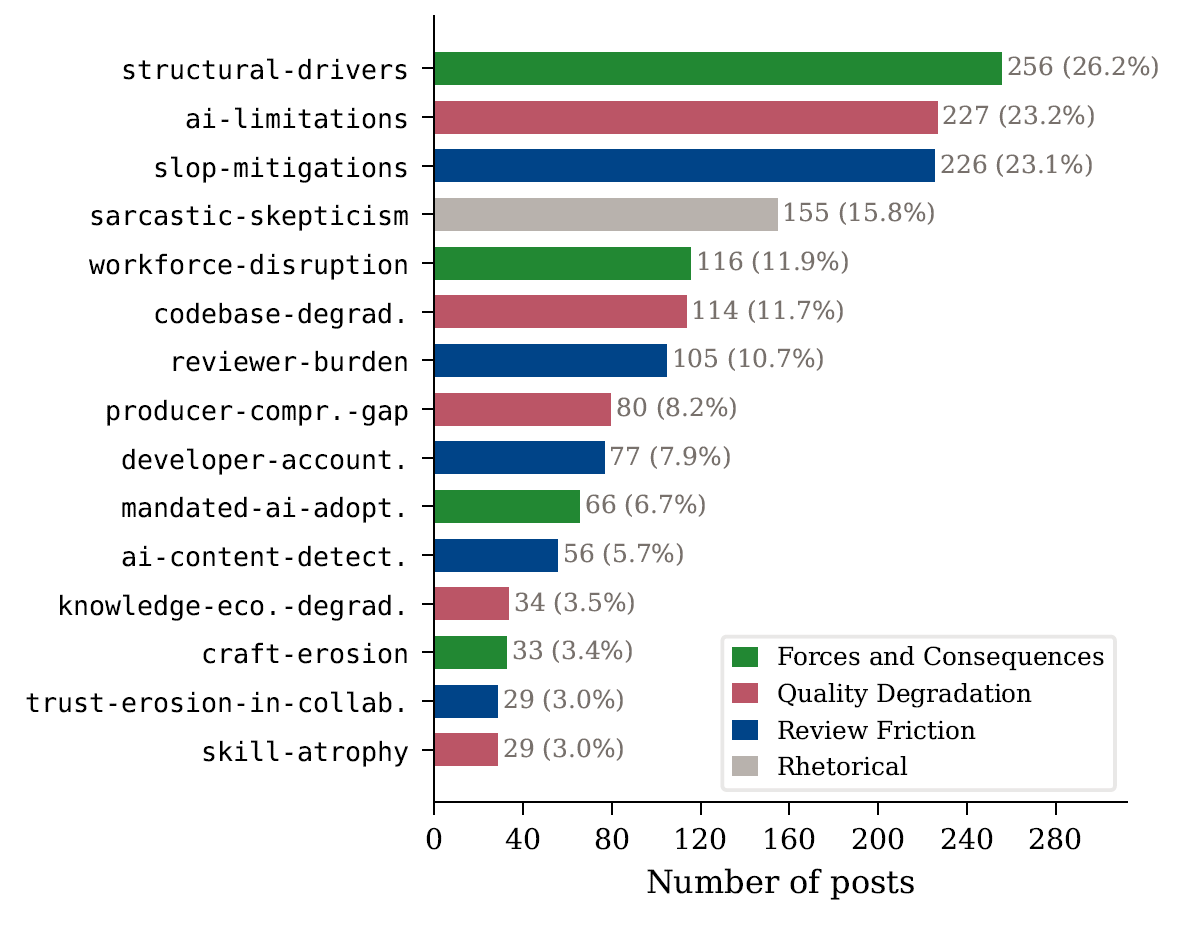
На основе данных создали кодовую книгу с 15 категориями, объединенными в три тематических группы: трение в ревью, падение качества и силы с последствиями.
Сторонники помощи ИИ в разработке возражают: с улучшением моделей качество кода по человеческим меркам станет менее важным. Сотрудник OpenAI прогнозирует отказ от ручного ревью генерируемого ИИ кода, что приведет к сложным сбоям систем, но они решатся. Известный специалист по ИИ Андрей Карпати уже назвал людей узким местом в исследованиях с ИИ.
Если развить эту идею, с ростом моделей роль человека как bottleneck усилится. Вопрос перестанет быть в соответствии кода человеческим стандартам качества, а сместится к работоспособности, поддержке, доработке и оптимизации агентами ИИ. Люди будут курировать процесс, не проверяя каждую строку вручную.
Личные плюсы продуктивности, общие минусы
Главный вывод исследования: критики видят в ИИ-шлаке трагедию общин. Отдельные разработчики и компании получают выгоду от генерируемого ИИ вывода, а ревьюеры, мейнтейнеры и все сообщество несут расходы. В кодовых базах накапливается техдолг, ресурсы знаний загрязняются, ревьюеры выгорают, рушится доверие, скрепляющее совместную работу.
Особо остро проблема бьет по миру open source, где общие ресурсы поддерживают волонтеры. Уже есть примеры: проект curl закрыл программу охоты за багами из-за ИИ-генерируемых отчетов о уязвимостях, которые тратили время мейнтейнеров впустую. Похожие случаи случились с Apache Log4j 2 и движком Godot.
Разработчики жалуются, что менеджмент навязывает рабочие процессы с ИИ. В одном случае топ-менеджеры копировали вывод ИИ напрямую для решения любой технической задачи команды.
Ревьюеры становятся бесплатными инженерами промтов
Одна из главных тем в критике — нагрузка на тех, кто проверяет код от ИИ. «Время разработки сократилось, но команде теперь уходит больше на ревью. Никакой выгоды», — отметил один разработчик. Одна команда получала 30 пул-реквестов в день при шести ревьюерах.
Ревьюеры ощущают себя «первым человеком, который вообще увидел этот код», и жалуются на роль бесплатных инженеров промтов: «Они просто используют вас, чтобы вы оценили и разобрались в их ИИ-шлаке и дали следующий промт».
Ревьюеры придумывают приемы для выявления кода от ИИ. Эмодзи в комментариях к коду — почти верный признак. Другие признаки: шаблонные пошаговые комментарии, избыточный стиль, артефакты Unicode. Доверие к совместным процессам падает. Один описал пул-реквест от ИИ-агента: «Не поймешь, как ему доверять. Нет настоящего понимания, что он делает, — просто угадывает».
ИИ-агенты показывают опасное поведение. Исследование упоминает «смертельные циклы» самокоррекций с ошибками и случаи, когда агенты меняли тесты, чтобы сломанный код проходил, вместо правки. В одном примере агент «придумал внешние сервисы, а потом замокал эти выдуманные сервисы», создав coherent, но полностью фиктивную интеграцию.
Помимо кодовых баз страдают внешние ресурсы знаний. «Документация и туториалы теперь пропускают ключевую информацию или код для реализации. Или все неверно, с несуществующими классами».
Есть опасения по деградации навыков сообщества. Комментатор на Hacker News описал ловушку: чтобы эффективно использовать ИИ, нужен опыт инженера, но опыт набирался без ИИ. Как появятся новые профи? Это касается большой части знаний-работы.
Меры от лимитов на PR до стандартов ответственности
Исследование фиксирует контрмеры, которые разработчики предлагают или уже применяют: ограничения размера пул-реквестов с ИИ-кодом («меньше 500 строк на PR, иначе не ревьюим»), обязательный саморевью перед пир-ревью, синхронные прогулки по коду, двойные ревью с внешними командами, привязка ответственности к оценкам производительности.
Авторы дают рекомендации трем группам. Разработчикам инструментов стоит переключиться с генерации на верификацию и ревью — добавить индикаторы неопределенности, информацию о происхождении. Инструменты должны продвигать мелкие инкрементальные изменения и структурировать вывод для легкой проверки.
Руководителям команд нужно пересмотреть критерии оценки: не по объему вывода, а с учетом downstream-расходов вроде усилий на ревью и уровня ошибок. При этом разработчики должны сохранять контроль над использованием ИИ. Команды обязаны требовать от контрибьюторов понимания и объяснения изменений — через лимиты PR и прогулки по коду.
Для вузов ученые советуют форматы экзаменов вроде устных или live-кодинга, плюс ограничение ИИ-инструментов на ранних курсах для закладки базовых навыков. Готовый вывод не доказывает компетенцию.