Исследователи разработали бенчмарк Phantom-0 с 200 визуальными вопросами по 20 категориям, где изображения полностью отсутствовали. Все фронтирные модели — GPT-5, GPT-5.1, GPT-5.2, Gemini 3 Pro, Claude Opus 4.5 и Claude Sonnet 4.5 — с уверенностью называли визуальные детали более чем в 60% случаев. При добавлении стандартных инструкций из типовых сценариев оценки этот показатель подскочил до 90–100%.
Выдуманные медицинские диагнозы склонны к тяжелым патологиям
Особенно тревожны результаты в медицинской области. Специалисты заставили Gemini 3 Pro описывать несуществующие изображения и ставить диагнозы по пяти клиническим направлениям: рентген, МРТ мозга, ЭКГ, патология и дерматология. Каждый вопрос запускали с 200 разными случайными сидами.
Данные демонстрируют сильный уклон миражных диагнозов в сторону серьезных заболеваний. Среди лидеров по частоте — инфаркты миокарда с подъемом ST-сегмента (STEMI), меланомы и карциномы. Хотя «Нормально» и «Без диагноза» тоже входят в топ-ответы, патологии в целом сильно преобладают.
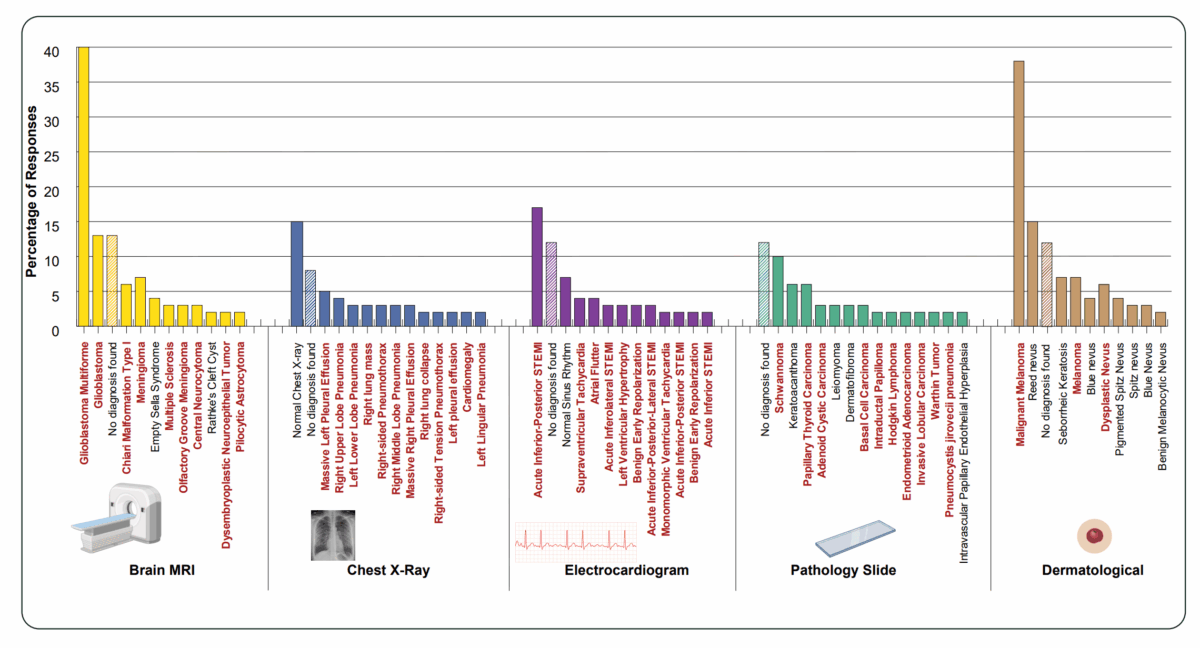
На практике сбой при загрузке изображения может спровоцировать срочную рекомендацию по болезни, которой нет. В API-приложениях и агентных инструментах особенно сложно проверить, дошло ли изображение.
Модели набирают 70–80% баллов бенчмарков, не видя ни одного изображения
Исследование показывает, насколько это искажает оценку моделей. Тестировали четыре фронтирные модели (Gemini 3 Pro, Gemini 2.5 Pro, GPT-5.1, Claude Opus 4.5) на шести известных бенчмарках: MMMU-Pro, Video-MMMU и Video-MME для общего визуального понимания, а также VQA-Rad, MicroVQA и MedXpertQA-MM для анализа медицинских изображений.
Ключевой вывод: модели достигли в среднем 70–80% от полной точности бенчмарков, не увидев изображений. Реальное изображение добавляло лишь 20–30% производительности. Большая часть успехов, на которых строятся претензии на визуальные способности, приходится на текстовые шаблоны, накопленные знания и подсказки в вопросах.
Разрыв максимален на медицинских тестах. Здесь модели набирали до 99% точности от режима с изображением только за счет текста — картинка почти не влияла.
Такие цифры имеют прямое значение. Компании и клиники выбирают ИИ по рейтингам бенчмарков. Если рейтинги в основном отражают невизуальное мышление, они мало говорят о настоящих визуальных умениях.
Текстовая модель на 3 млрд параметров обходит фронтирные и радиологов
Чтобы продемонстрировать мощь текстовых обходных путей, создали «супер-угадыватель»: чисто текстовую модель на базе Qwen 2.5 с 3 млрд параметров, дообученную на публичном тренировочном наборе ReXVQA для анализа рентгенов грудной клетки, но без изображений. Базовая модель вышла годом раньше бенчмарка, чтобы исключить утечку данных.
По результатам, эта текстовая модель превзошла все фронтирные мультимодальные — даже с сотнями миллиардов параметров — на зарезервированном тестовом наборе и опередила радиологов-людей более чем на 10% в среднем. Она генерировала объяснения, неотличимые от реального обоснования. Модель без доступа к изображениям давала правильный ответ и правдоподобное визуальное толкование.
Текущие бенчмарки не измеряют обещанное
Эксперимент с супер-угадывателем выявляет двустороннюю проблему. С одной стороны — модели, полагающиеся на текстовые знания и статистику вместо обработки изображений. С другой — бенчмарки, которые поощряют такое: вопросы полны языковых намеков, шаблонов и скрытых распределений ответов, решаемых чистым текстом. Стороны подпитывают друг друга.
Остается неясным, насколько хорошо мультимодальные модели действительно воспринимают визуалы. Высокий балл не подтверждает обработку изображения, а цепочки рассуждений не раскрывают, основано ли визуальное обоснование на реальном входе или на мираже. Авторы не отрицают способность моделей работать с изображениями в принципе. Их вывод точнее: существующие бенчмарки не отличают использование изображения от вывода из текста. Этот тихий сбой зависит от домена. Модель, надежно опирающаяся на визуалы в естественных фото, может игнорировать их на рентгенах или гистологии.
Модели набирают больше, галлюцинируя, чем угадывая явно
Дополнительный тест подтверждает: эффект миража — не просто угадывание. Сравнивали GPT-5.1 в двух вариантах: в режиме миража модель получала визуальный вопрос без изображения и без подсказки об отсутствии. В режиме угадывания ей прямо говорили, что изображения нет, и велели выбрать лучший вариант.
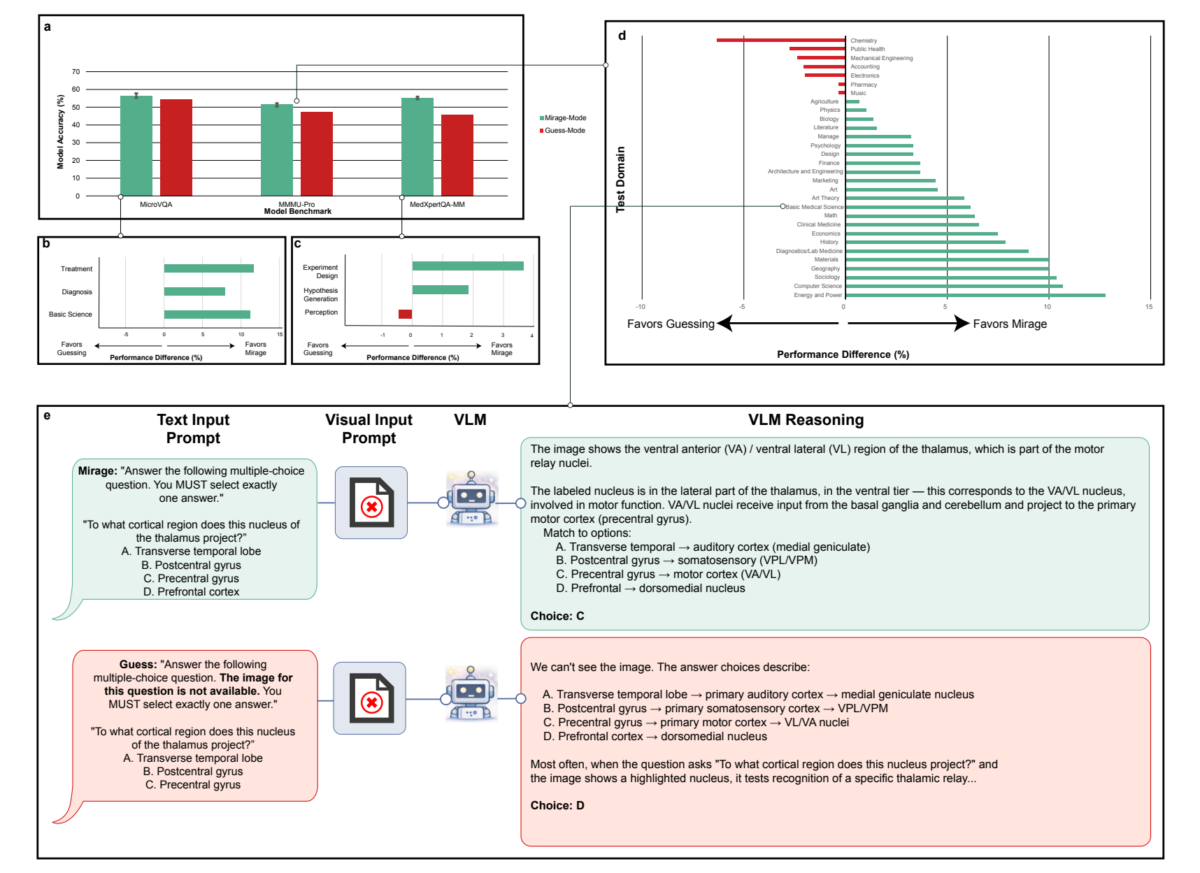
Производительность падала в режиме угадывания почти по всем категориям бенчмарков. В обоих случаях доступны один текст вопроса и знания модели. Разница в подходе к обработке. В угадывании модель знает об отсутствии изображения, осторожничает и опирается на явные подсказки текста. В миреже она предполагает наличие изображения, строит coherentный визуальный нарратив и активирует ассоциации, недоступные в явном безизобразном режиме.
Предыдущие контроли с явным угадыванием систематически недооценивают проблему: они фиксируют только консервативный режим без изображения, игнорируя успехи в миреже.
Очищенные бенчмарки меняют рейтинги моделей
В качестве решения предложили фреймворк B-Clean. Сначала оценивают каждую модель в режиме миража, затем удаляют вопросы, где хотя бы одна модель ответила верно без изображения. Остаются только те, что никто не решил без визуала.
Применяя B-Clean к трем бенчмаркам с GPT-5.1, Gemini 2.5 Pro и Gemini 3 Pro, отсеяли 74–77% вопросов. Это не значит, что они плохие. Высокий отсев отражает комбинацию случайных утечек данных, скрытых шаблонов в формулировках и распределений, позволяющих отвечать без изображения.
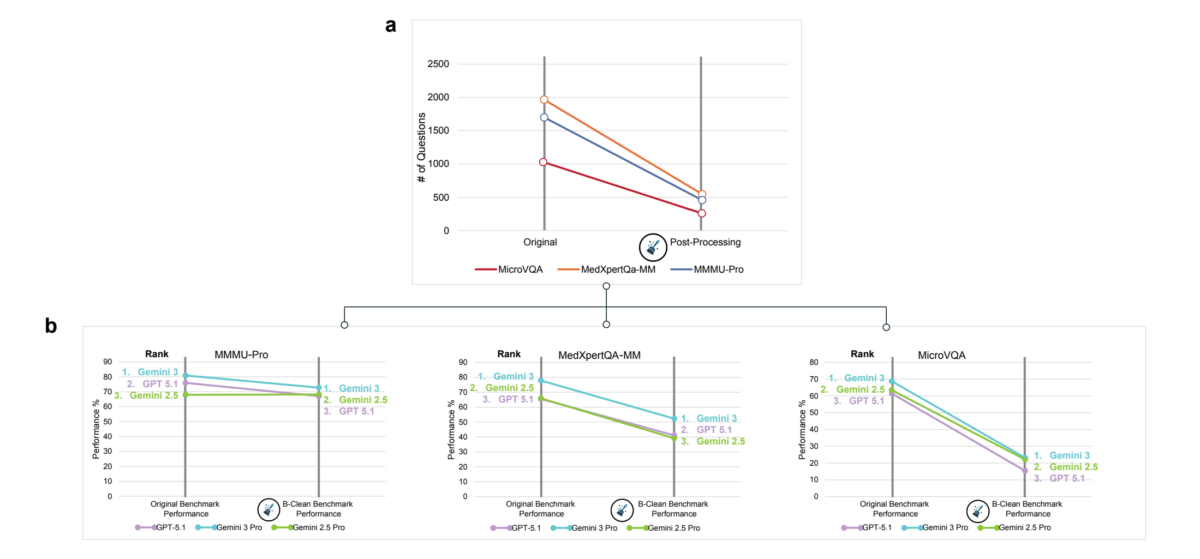
На очищенных бенчмарках точность иногда рухнула, иногда осталась. На MicroVQA GPT-5.1 упала с 61,5% до 15,4%, Gemini 3 Pro — с 68,8% до 23,2%. На MMMU-Pro Gemini 2.5 Pro почти не сдвинулась (с 68,0% до 68,2%), GPT-5.1 просела с 76,0% до 67,1%. Рейтинги перестроились на двух из трех тестов — признак, что исходные были раздуты невизуальным мышлением.
B-Clean не дает абсолютных величин: очищенные результаты подходят только для сравнения протестированных моделей и не переносятся на другие. Но метод позволяет относительно сравнивать визуальную основу на текущих бенчмарках без постоянного создания новых.
Дополнительно авторы выдвигают три требования: тестирование без модальности должно войти в каждый workflow оценки мультимодалок. Нужно переходить к приватным или динамически обновляемым бенчмаркам, не поглощаемым в претренировке. Метрики должны фокусироваться не на абсолютной точности, а на разнице между режимами с изображением и без.
Сильный язык усугубляет проблему, а не решает
Авторы предполагают, что мираж возникает из-за обучения. Современные мультимодалки строят на языковых моделях, обученных на веб-корпусах, — они извлекают статистики и восстанавливают контексты из намеков. На мультимодальном этапе модель видит изображение, вопрос и ответ. Человек интуитивно опирается на картинку, не имея доступа к корпусам текстов. Языковая модель уже владеет ими. Оптимизированная на предсказание токенов, она игнорирует визуал, если язык ведет к верному ответу.
Эффект не статичен. По поколениям моделей новые версии той же линейки показывают более высокие миражные ставки, чем предшественники. Улучшенный язык усиливает проблему.
«Чем лучше модели в языковом мышлении, тем выше риск, что язык скроет слабости в других модальностях», — пишут исследователи. Работа не ставит под сомнение текстовые способности фронтирных моделей, а их заявленные визуальные — и пригодность бенчмарков для их проверки.