Модель Helios первой среди 14-миллиардных видео-генераторов достигла 19,5 FPS на одной GPU при создании роликов длиной минуту. Код и веса модели открыты для всех.
Обычные модели генерации видео выдают клипы по 5–10 секунд, а на их обработку тратят минуты. Для реального времени с длинными последовательностями прибегают к моделям по 1,3 млрд параметров, но качество оставляет желать лучшего. Крупные варианты вроде Krea-RealTime-14B ограничиваются 6,7 FPS на H100 и мучаются от выраженных артефактов дрейфа.
Helios развивает Wan-2.1-14B, тратящую примерно 50 минут на пять секунд видео на A100. Процесс обучения разделен на три фазы: Helios-Base фокусируется на архитектуре и подавлении дрейфа, Helios-Mid вводит сжатие токенов при 1,05 FPS, а Helios-Distilled доводит скорость до максимума, сокращая вычисления до трех шагов.
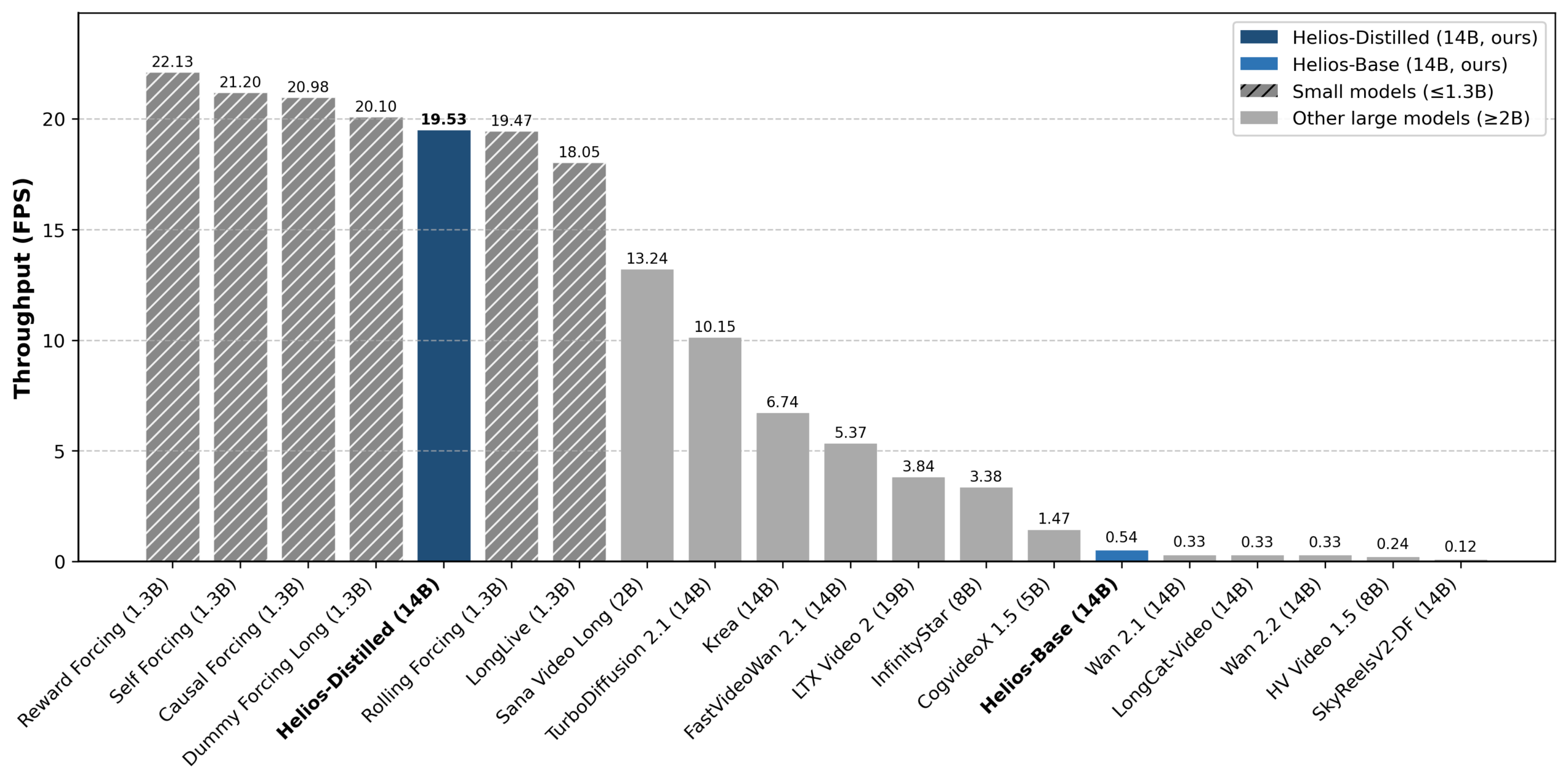
В тестах разработчиков дистиллированная Helios набирает 19,53 FPS, обгоняя даже некоторые меньшие дистиллированные аналоги. SANA Video Long с 2 млрд параметров, в семь раз компактнее, выдает только 13,24 FPS.
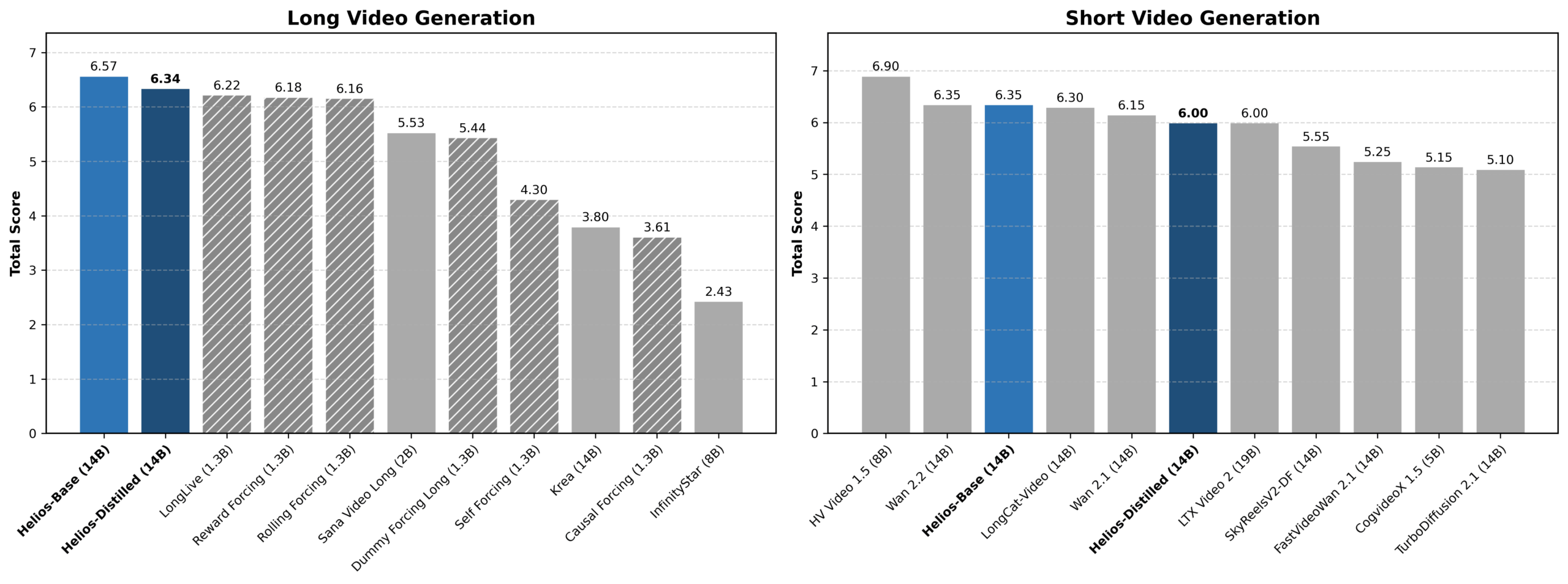
По качеству видео Helios получает 6,00 баллов за короткие ролики из 81 кадра. Авторы утверждают, что она превосходит все дистиллированные модели и не уступает базовым на своем размере. Для длинных видео показатель 6,94 — чуть лучше лидера Reward Forcing с 6,88. Результаты подтверждает опрос 200 пользователей.
Длинные синтезированные видео обычно теряют четкость, стабильность цветов и связность сюжета со временем. Раньше с этим боролись сложными методами вроде self-forcing, когда модель во время обучения использует свой вывод как вход, чтобы стереть разницу между обучением и генерацией. Helios обходитесь без таких ухищрений.

Разработчики выявили три ключевых паттерна дрейфа и ввели простые корректировки. Кодирование относительных позиций не дает модели сталкиваться с неизвестными индексами в длинных последовательностях, избегая повторяющихся движений. Якорь первого кадра постоянно держит начальное изображение в памяти как ориентир, блокируя сдвиги цвета. Симуляция целевых возмущений на обучении повышает устойчивость к собственным ошибкам, не давая им нарастать.
Единая модель для текста, изображений и видео
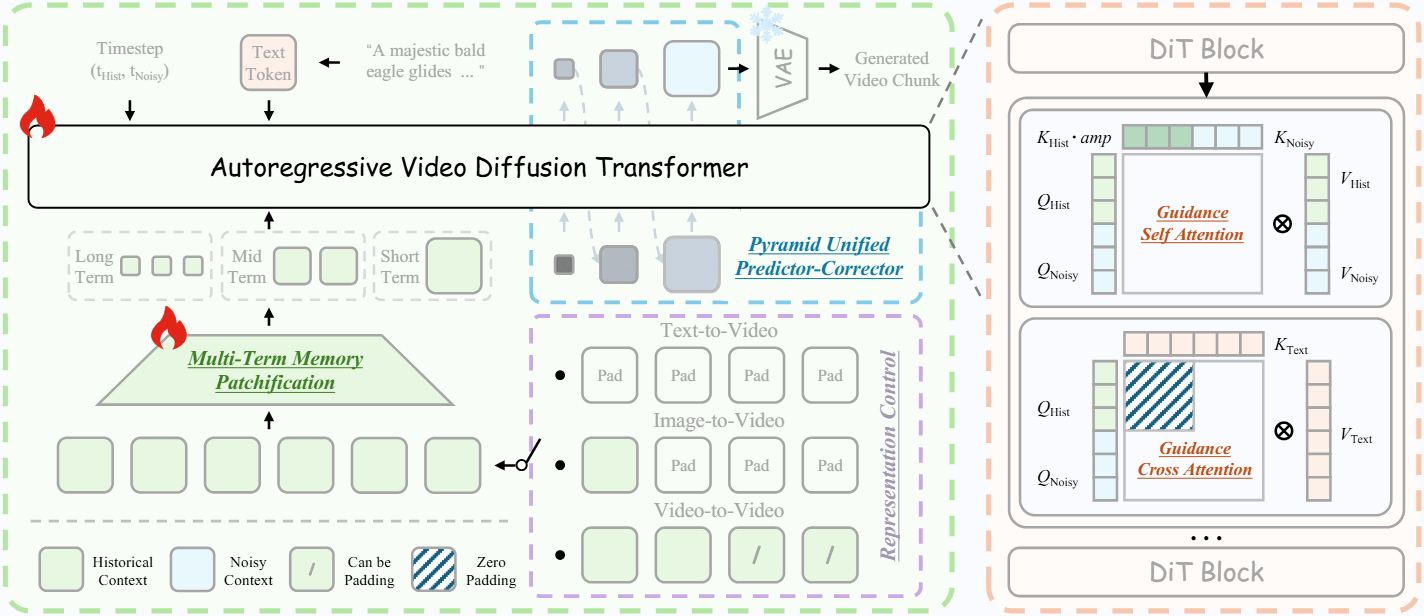
Helios применяет универсальную схему, охватывающую text-to-video, image-to-video и video-to-video в одном каркасе. Переключение между задачами происходит само по содержимому предыдущего контекста.
Пустой контекст запускает генерацию из текста. Если есть только последний кадр, модель анимирует изображение. При наличии нескольких кадров продолжается существующее видео. Промт можно менять на лету; плавный кроссфейд между старым и новым предотвращает резкие скачки в картинке.
Обучение прошло в три этапа на 800 тысячах коротких клипов по менее 10 секунд каждый. Максимальное разрешение — 384 x 640 пикселей, мерцание заметно на стыках сегментов. Поскольку бенчмарков для реального времени с длинными видео нет, создали свой набор HeliosBench из 240 промтов.
Жесткое сжатие ради снижения нагрузки
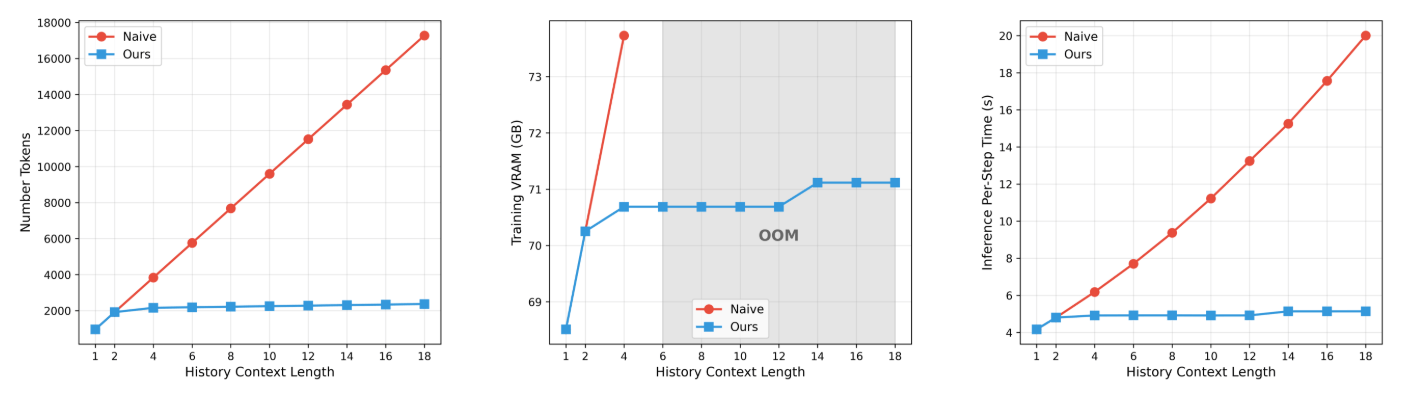
Helios достигает цели по скорости без типичных ускорений вроде KV-кэша, разреженного внимания или квантования. Вместо этого модель радикально сжимает входные данные на двух уровнях.
Иерархическая структура памяти делит историю видео на три временных горизонта. Свежие кадры сжимаются слабо, старые — сильно. Это уменьшает токены для обработки в восемь раз.
Многоэтапный семплинг сокращает токены для текущего сегмента в 2,29 раза. Начальные шаги идут в низком разрешении, финальные добавляют детали. В сумме нагрузка падает до уровня генерации одного изображения.
Специальная дистилляция урезает шаги вычислений на сегмент с 50 до 3. В отличие от предшественников, Helios использует только реальные видео как контекст и генерирует один сегмент за итерацию. Адверсариальная цель в духе GAN поднимает качество за пределы учителя.
Сжатие токенов позволяет обучать первые два этапа на одной GPU. Третий требует четырех моделей параллельно, но они укладываются в 80 ГБ памяти за счет оптимизаций. Собственные ядра для операций ускоряют тренинг и инференс на 14% по сравнению со стандартными.
Открытые веса Helios лежат на GitHub и Hugging Face, где также есть демо вживую. Примеры видео — на странице проекта. Проект предназначен только для исследований, без планов в продукты Bytedance.
Bytedance недавно отметилась Seedance 2.0 — мультимодальной моделью для видео из изображений, видео, аудио и текста. Seedance требует больше ресурсов, ограничивается 15 секундами, но дает высочайшее качество, вызвавшее тревогу в Голливуде из-за риска массовых нарушений авторских прав.