Google запускает семейство Gemma 4 — свои наиболее мощные открытые модели на сегодняшний день. Четыре свежих варианта подходят для устройств от смартфонов до профессиональных станций и впервые распространяются под полностью открытой лицензией Apache 2.0.
Они построены на той же основе, что и закрытые Gemini 3 от Google, и выходят под коммерчески свободной лицензией Apache 2.0. Это позволяет разработчикам самостоятельно управлять своими данными, оборудованием и моделями. Ранние версии Gemma раньше публиковались под более строгой собственной лицензией компании.
Каждый вариант Gemma 4 демонстрирует прорыв в задачах с многоэтапным мышлением и математикой, по данным Google. В агентских сценариях модели сразу поддерживают вызовы функций, вывод в формате JSON и системные указания, чтобы независимые агенты могли подключаться к разным инструментам и API.
Четыре размера от компактных устройств до мощных станций
Семейство Gemma 4 включает четыре размера: Effective 2B (E2B), Effective 4B (E4B), 26B с архитектурой Mixture-of-Experts (MoE) и 31B плотную (Dense). Все они выходят за рамки простого диалога и решают сложные логические задачи плюс агентские процессы.
| E2B | E4B | 26B MoE | 31B Dense | |
|---|---|---|---|---|
| Активные параметры | "эффективно" 2 миллиарда | "эффективно" 4 миллиарда | 3,8 миллиарда активных | - |
| Архитектура | - | - | MoE | Dense |
| Окно контекста | 128K токенов | 128K токенов | до 256K токенов | до 256K токенов |
| Целевое оборудование | Смартфоны, Raspberry Pi, Jetson Orin Nano | Смартфоны, Raspberry Pi, Jetson Orin Nano | Персональные ПК, потребительские GPU (квантизованные), рабочие станции, ускорители | Персональные ПК, потребительские GPU (квантизованные), рабочие станции, ускорители |
| Работа оффлайн | ✅ | ✅ | ✅ | ✅ |
| Зрение (изображения/видео) | ✅ | ✅ | ✅ | ✅ |
| Аудиовход | ✅ | ✅ | - | - |
| Квантизация на потребительском GPU | - | - | ✅ | ✅ |
| Рейтинг Arena AI (открытые) | - | - | #6 | #3 |
| Особенность | Эффективность вычислений и памяти на edge-устройствах | Эффективность вычислений и памяти на edge-устройствах | Оптимизация под задержки, 3,8 миллиарда активных параметров, быстрое создание токенов | Максимальное качество, основа для дообучения |
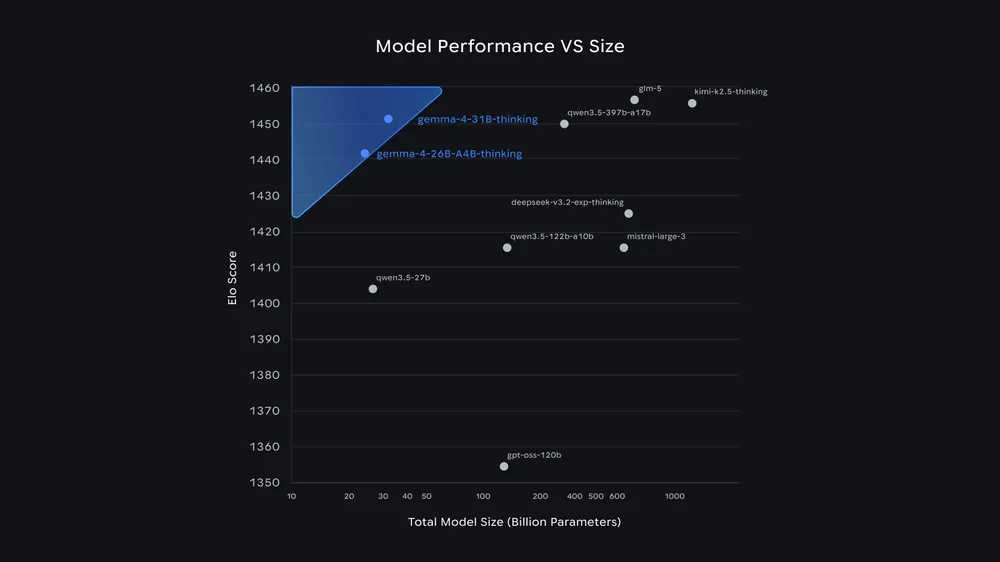
Сейчас 31B-модель занимает 3-е место среди всех открытых моделей в мировом Arena AI Text Leaderboard, а 26B MoE — 6-е. Google заявляет, что Gemma 4 обходит варианты в 20 раз крупнее себя. Для разработчиков это значит отличные результаты при минимальных требованиях к оборудованию.
Две крупные модели ориентированы на рабочие станции и серверы. Невыквантизованные веса bfloat16 для 31B помещаются на одной 80 ГБ NVIDIA H100 GPU, а квантизованные версии подойдут и для обычных видеокарт.
В 26B MoE во время вывода задействуется только 3,8 миллиарда параметров, что обеспечивает особенно высокую скорость генерации токенов. А 31B плотная модель заточена под пиковое качество и подходит как стартовая точка для дообучения.
Компактные E2B и E4B созданы специально для мобильных гаджетов и IoT-оборудования. Они активируют соответственно 2 и 4 миллиарда параметров при работе, чтобы экономить память и энергию батареи. Оба варианта для периферии напрямую обрабатывают изображения, видео и аудио для распознавания речи. Их окно контекста достигает 128 000 токенов, а у старших — до 256 000.
Независимые тесты от Artificial Analysis подтверждают показатели для крупных моделей Gemma 4. На бенчмарке GPQA Diamond по научному мышлению 31B набирает 85,7% в режиме рассуждений. По данным Artificial Analysis, это второй лучший результат среди открытых моделей меньше 40 миллиардов параметров — сразу за Qwen3.5 27B с 85,8%. Примерно на 1,2 миллиона выходных токенов Gemma 4 31B требует меньше вычислений, чем Qwen3.5 27B (1,5 миллиона) и Qwen3.5 35B A3B (1,6 миллиона).
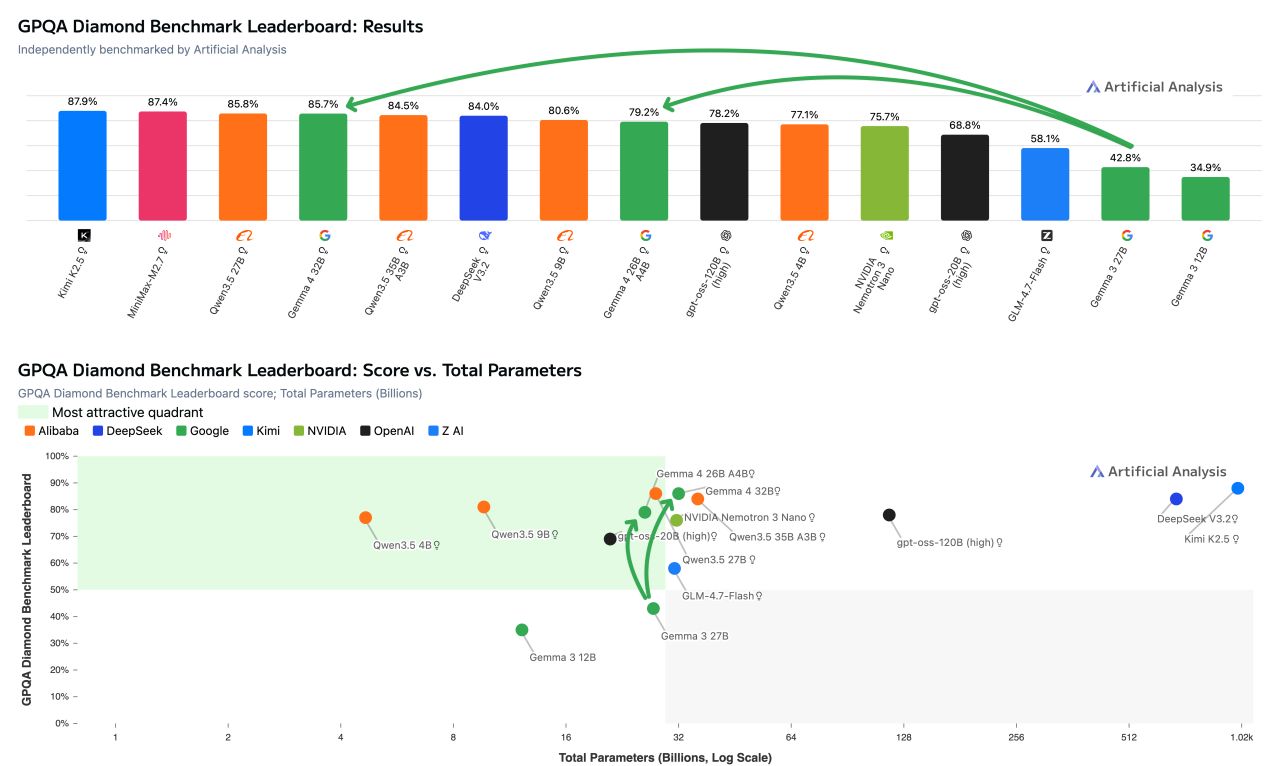
Модель 26B MoE показывает 79,2% на том же тесте — лучше, чем 76,2% у gpt-oss-120B от OpenAI, но хуже, чем 80,6% у Qwen3.5 9B. Artificial Analysis подчёркивает, что обе протестированные модели запускаются на одной H100 GPU. Полная проверка всех четырёх Gemma 4 в Intelligence Index от Artificial Analysis ещё впереди. Как обычно, результаты бенчмарков не всегда точно отражают поведение в реальных условиях.
Где скачать Gemma 4 и какие платформы поддерживаются
Gemma 4 уже доступна на Hugging Face, Kaggle и Ollama. В Google AI Studio работают 31B и 26B, а Google AI Edge Gallery берёт E4B и E2B.
С релиза модели совместимы с множеством фреймворков и сервисов: Hugging Face Transformers, vLLM, llama.cpp, MLX, Ollama, NVIDIA NIM и NeMo, LM Studio, Unsloth, SGLang, Keras и другими. Дообучение возможно в Google Colab, Vertex AI или на домашних игровых GPU. Для продакшена масштабирование идёт через Google Cloud с Vertex AI, Cloud Run и GKE.
С точки зрения железа Google отмечает поддержку NVIDIA от Jetson Orin Nano до Blackwell GPU, AMD GPU через ROCm и собственных Trillium с Ironwood TPU.