Сколько оценщиков требуется надежному бенчмарку ИИ? Новое исследование убеждает: стандартные три-пять человек на пример часто не справляются, а распределение бюджета аннотаций важнее его объема.
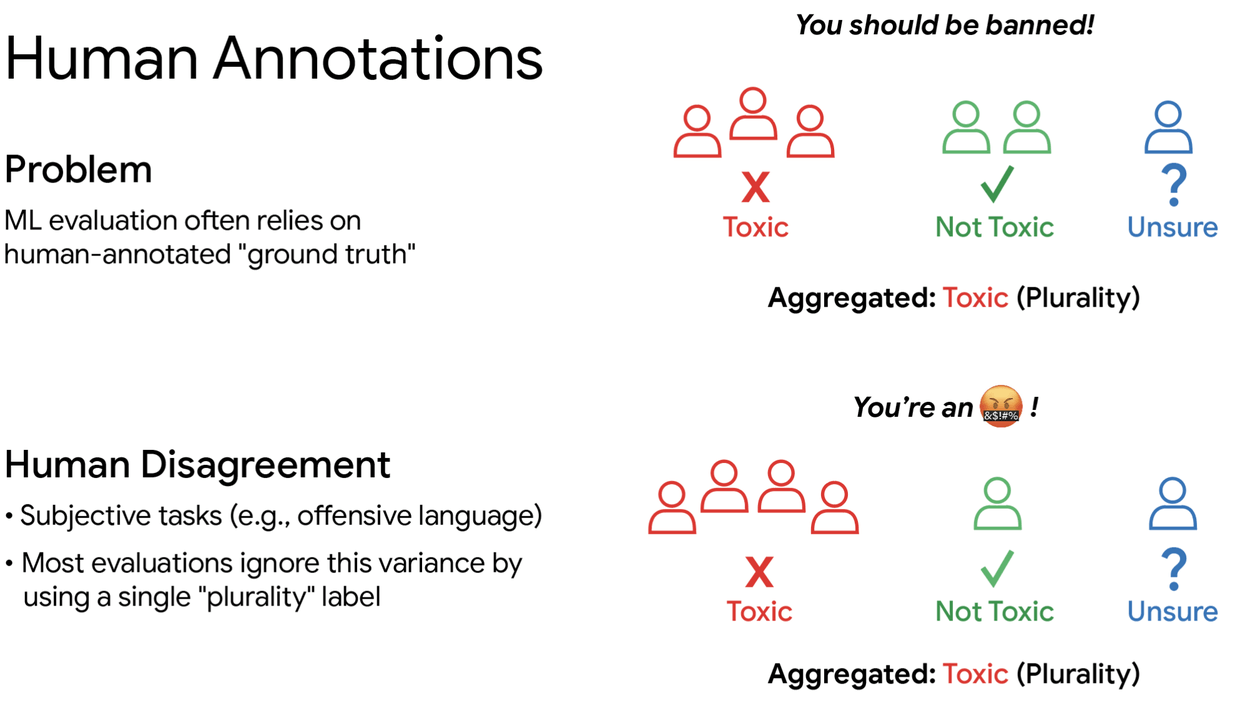
При сопоставлении ИИ-моделей человеческие оценки нередко определяют победителя. Люди решают, токсичен ли комментарий или безвреден ли ответ чат-бота.
Проблема в том, что мнения людей расходятся. В исследованиях ИИ обычно собирают три-пять оценок на каждый пример и выбирают единственный «верный» ответ большинством голосов. Такой метод полностью отсекает разнообразие человеческих взглядов.
Специалисты из Google Research и Rochester Institute of Technology искали оптимальный подход к расходам на ограниченный бюджет оценок. Основной вопрос: стоит ли проверять максимум примеров минимальным числом людей или ограничиться меньшим количеством примеров с большим числом оценщиков?
Разработчики объясняют дилемму на примере ресторана. Если опросить тысячу посетителей по одному блюду, выйдет широкая, но поверхностная картина. А если попросить 20 гостей оценить 50 блюд, получите глубокое понимание сильных и слабых сторон меню. Большинство сегодняшних бенчмарков ИИ придерживаются первого варианта: проверяют множество примеров, но с тонким слоем человеческих суждений.
Проверка тысяч вариантов распределения бюджета
Чтобы выявить идеальное соотношение, команда создала симулятор, который воспроизводит паттерны человеческих оценок на основе реальных наборов данных. Он создает синтетические оценки для двух моделей, где одна намеренно уступает другой. Это позволяет проверить, при каких условиях различия между моделями обнаруживаются стабильно.
Симулятор настроили по пяти реальным наборам данных: распознавание токсичности, безопасность чат-ботов и оценка оскорбительности в разных культурах. В итоге протестировали тысячи комбинаций общих бюджетов и числа оценщиков на пример.
Менее десяти оценщиков на пример не хватает
Выводы ставят под сомнение текущие методы. Один-пять оценщиков на пример обычно не гарантируют воспроизводимых сравнений моделей, считают авторы. Чтобы результаты статистически надежны и отражали спектр человеческих мнений, требуется больше десяти человек на каждый пример.
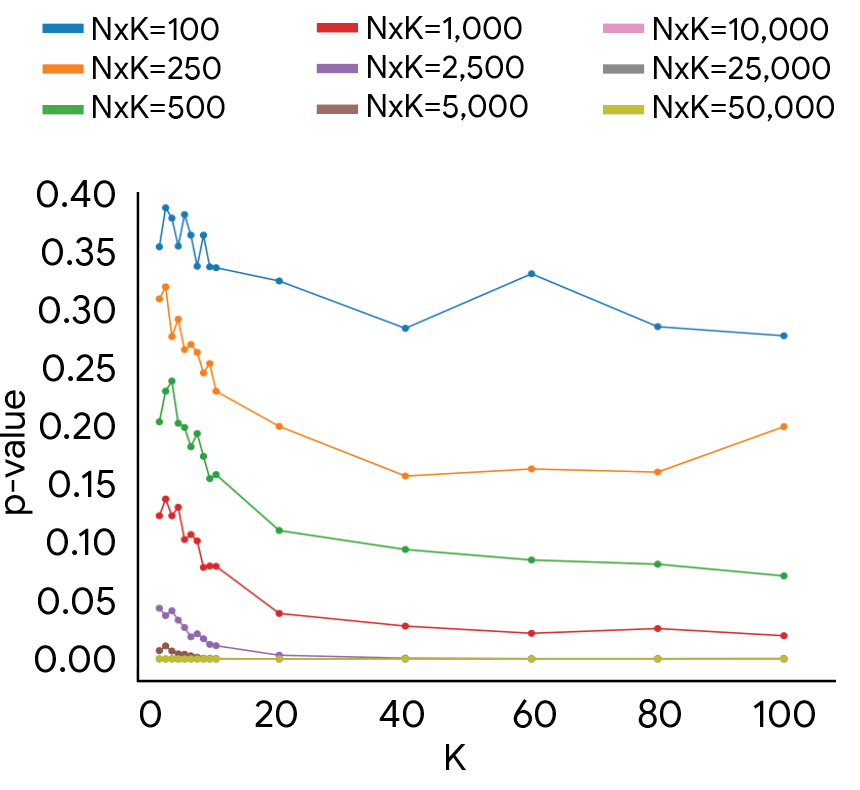
Эксперименты подтверждают: около тысячи аннотаций в сумме хватает для надежных выводов, но только при верном распределении между примерами и оценщиками. Неправильный баланс приводит к ненадежным результатам даже при большем бюджете.
Метрика определяет стратегию расходов
Главный урок: универсального соотношения нет. Выбор зависит от того, что именно измеряют.
Для точности — проверки совпадения модели с большинством голосов — лучше широкий охват: максимум примеров с минимумом оценщиков на каждый. Точность фокусируется на популярном ответе, дополнительные люди мало меняют картину.
Чтобы учесть весь разброс ответов — например, с метрикой total variation — нужен обратный подход. Меньше примеров, но существенно больше оценщиков на каждый. Только так удастся отобразить степень согласия или разногласий.
Разные примеры могут иметь одинаковую метку по большинству, но с разными распределениями ответов. В тестах метрика, учитывающая распределение, требовала минимального бюджета для надежных результатов.