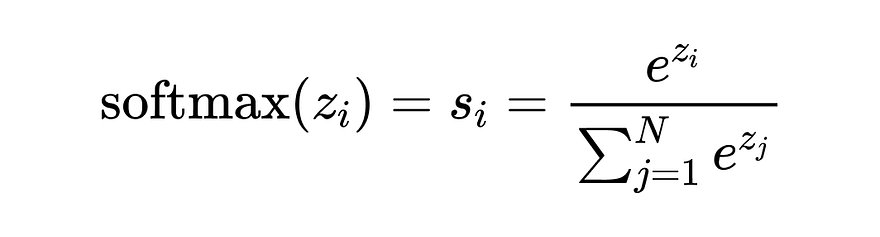Новости и статьи об искусственном интеллекте и нейросетях. Мы собираем и обрабатываем самую актуальную информацию из мира AI. О проекте
Изучение ИИ требует практики от основ до продакшена, и эти 10 репозиториев GitHub идеально подходят для этого. Они охватывают генеративный ИИ, LLM, агентов, математику, зрение и реальные проекты. Каждый ресурс предлагает код, уроки и примеры для быстрого прогресса.
Начинающие data scientists часто совершают ошибки, которые замедляют их прогресс: игнорируют математику, ищут идеальный курс, застревают в туториалах, делают много простых проектов и сразу рвутся в ИИ. Избегать этих ловушек помогает фокус на основах и практике через глубокие личные проекты. Так путь к первой работе становится короче и эффективнее.
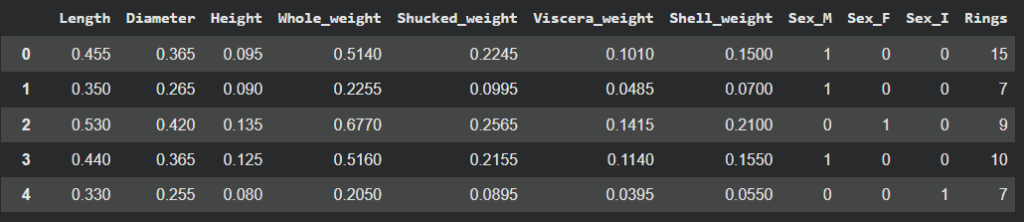
В руководстве демонстрируется построение модели множественной линейной регрессии с использованием PyTorch на наборе данных Abalone, с сравнением результатов Scikit-Learn. Анализ данных выявляет проблемы с гомоскедастичностью и выбросами, влияющие на точность. Модель PyTorch показывает скромное улучшение на 4%, подчеркивая ограничения линейных подходов для нелинейных данных.
В статье разбирается реализация умножения матриц в Triton с акцентом на оптимизации вроде блочного разбиения и согласованности памяти. Рассматривается иерархия памяти GPU на примере A100 и влияние параллелизации на производительность. Эксперименты показывают, как профилирование помогает выявлять bottlenecks в ядрах.
Статья объясняет, как оптимизировать цикл обучения в PyTorch, фокусируясь на конвейере данных для предотвращения голодания GPU. Рассматриваются узкие места, инструменты вроде Dataset, DataLoader и профайлера, а также практические эксперименты с MNIST, показывающие ускорение до 2.52 раза. В конце приведены лучшие практики и перспективы дальнейших улучшений.
Gistr — умный AI-блокнот, который помогает специалистам по данным организовывать знания из видео, статей и PDF в едином пространстве. Инструмент автоматически выделяет ключевые моменты, отвечает на вопросы по контенту и строит визуалы. Это меняет подход к исследованиям, делая его быстрее и эффективнее.
В этой статье разбирается функция softmax — ключевой элемент нейронных сетей, ее реализация в Triton с учетом градиентов и оптимизаций. Рассматриваются версии на одном и нескольких блоках, тестирование и сравнение производительности с PyTorch. Материал помогает понять, как создавать эффективные ядра для GPU.
В статье описывается создание сверточной нейронной сети на PyTorch для классификации подтипов рака лёгких по профилям числа копий ДНК. Используются публичные данные из TCGA, PCAWG и TRACERx, обработанные с помощью инструмента CNSistent. Модель достигает высокой точности в различении аденокарциномы и плоскоклеточного рака, а также обсуждаются бонусные подходы на основе LLM.
В этой статье делятся тремя практическими уроками из работы с машинным обучением за месяц: разумный выбор библиотек для новых проектов, использование менеджеров буфера обмена для удобства тестирования и польза широкого чтения литературы для глубокого понимания. Эти выводы помогают оптимизировать процесс разработки и исследования. Они основаны на личном опыте и подкреплены конкретными примерами инструментов.
Показаны все статьи (9)