Alibaba представила Qwen3.5-Omni — омнимодальную модель ИИ, способную работать с текстом, изображениями, аудио и видео. Она превосходит Gemini 3.1 Pro в аудиозадачах и при этом обрела неожиданную способность: генерировать код на основе устных указаний и видеовходов.
Новейшая версия линейки Qwen от Alibaba вышла в трех вариантах Instruct (Plus, Flash и Light). Поддерживает контекст до 256 000 токенов и, по словам разработчиков, обрабатывает свыше десяти часов аудио плюс более 400 секунд видео в 720p при одном кадре в секунду. Модель прошла нативную предобработку как омнимодальная на данных объемом свыше 100 миллионов часов аудиовизуального контента. Она выдает речь параллельно с текстом.
Qwen3.5-Omni-Plus установила рекорды на 215 аудиобенчмарках
Разработчики из Qwen сообщают: версия Plus достигла лучших показателей сразу на 215 подзадачах по аудио и аудиовизуальным тестам. Это охватывает три аудиовизуальных бенчмарка, пять аудио, восемь задач распознавания речи, 156 переводческих заданий на разных языках и 43 задания по распознаванию на конкретных языках. Qwen3.5-Omni-Plus обходит Gemini 3.1 Pro от Google по общему пониманию аудио, рассуждениям, распознаванию, переводу и диалогам. В аудиовизуальном понимании она сравнялась с Gemini 3.1 Pro.

Среди конкретных результатов Qwen3.5-Omni-Plus набрала 82,2 в понимании аудио (MMAU) против 81,1 у Gemini 3.1 Pro. Разрыв растет в распознавании музыки (RUL-MuchoMusic): 72,4 против 59,6. На бенчмарке VoiceBench для диалогов модель достигла 93,1, обойдя Gemini с 88,9. Визуальные и текстовые возможности соответствуют отдельным текстовым моделям Qwen3.5 того же размера.
В генерации речи сравнение шло с ElevenLabs, Gemini 2.5 Pro, GPT-Audio и Minimax. На сложном наборе "seed-hard" Qwen3.5-Omni-Plus показала word error rate 6,24. У GPT-Audio — 8,19, Minimax — 8,62, ElevenLabs — 27,70. При клонировании голосов на 20 языках модель получила word error rate 1,87 и cosine similarity 0,79.
Распознавание речи расширилось до 74 языков
Команда Qwen значительно увеличила языковую поддержку по сравнению с Qwen3-Omni. Теперь распознавание речи работает для 74 языков и 39 китайских диалектов — всего 113 языков и диалектов. Предыдущая версия охватывала лишь 11 языков и 8 китайских диалектов. Синтез речи поддерживает 36 языков и диалектов с 55 голосами, включая пользовательские, сценариевые, диалектные и многоязычные варианты.

На датасете Fleurs по распознаванию речи (топ-60 языков) Qwen3.5-Omni-Plus достигла word error rate 6,55 против 7,32 у Gemini 3.1 Pro. Для китайских вариантов вроде кантонского разрыв огромен: 1,95 против 13,40. Окно контекста выросло с 32 000 до 256 000 токенов.
ARIA решает проблему реального времени в синтезе речи
Архитектура сохраняет принцип thinker-talker. Thinker анализирует омнимодальные входы и выдает текст, talker преобразует его в контекстную речь. Оба компонента теперь на гибридной архитектуре attention-MoE вместо чистого mixture-of-experts у предшественника.
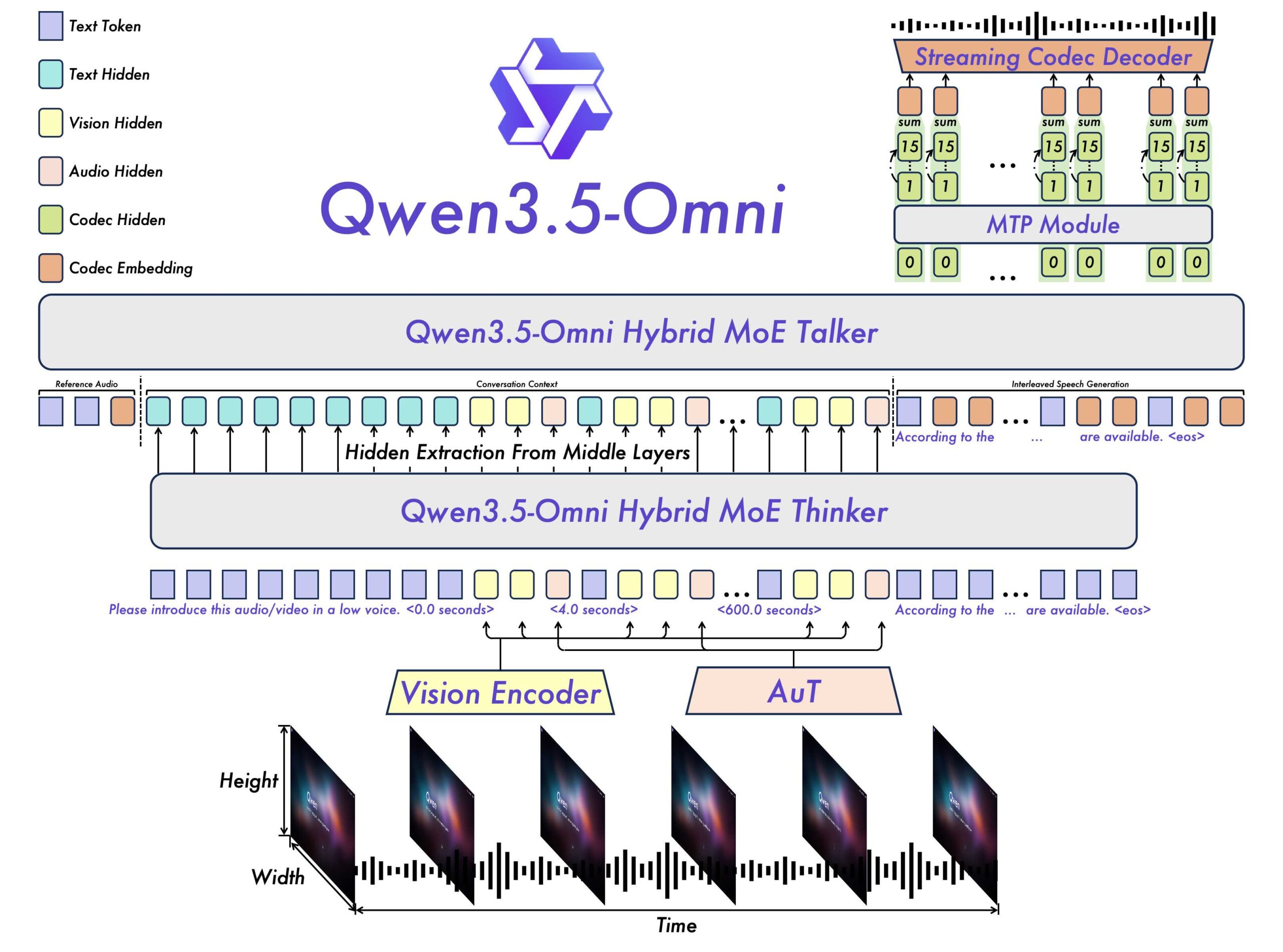
Ключевым техноулучшением — ARIA (Adaptive Rate Interleave Alignment). Она динамически выравнивает и чередует токены текста и голоса. Разработчики создали ее, чтобы устранить известную проблему реального времени в синтезе речи: токены текста и аудио кодируются с разной скоростью. Из-за чего в стриминговых разговорах пропадают слова, искажается произношение или сбиваются числа. ARIA делает синтез естественнее и надежнее, не жертвуя скоростью. Предшественник использовал жесткое соотношение 1:1 между токенами текста и аудио.
«Аудиовизуальный вайб-кодинг» возник как побочный навык
При масштабировании омнимодального обучения команда обнаружила неожиданную способность, по словам разработчиков Qwen. Модель генерирует код напрямую из устных инструкций и видеоконтента — так называемый «аудиовизуальный вайб-кодинг». Навык не обучали специально, он появился как следствие нативного мультимодального масштабирования. В демонстрациях Qwen3.5-Omni-Plus создает рабочую игру snake по словесному описанию и видеоклипу.
Модель описывает аудио и видео с такой детализацией, что результат похож на сценарий. Она автоматически сегментирует контент, добавляет метки времени с точностью до секунды и дает подробности о персонажах, диалогах, звуковых эффектах и их взаимодействии. В одном демо она разбирает трехминутный фрагмент документального фильма о львах по сценам, отмечая каждого говорящего, каждый монтаж и каждый звук. В другом — выявляет сцены насилия в видеоиграх для модерации контента, перечисляя их в таблице с метками времени и уровнями риска.
Разговоры в реальном времени обзавелись умными прерываниями и поиском в сети
Для бесед в реальном времени Qwen3.5-Omni добавила функции, которых не было у предшественника. «Семантическое прерывание» отличает реальное желание пользователя говорить от фонового шума или случайных реплик. Модель самостоятельно решает, запускать ли веб-поиск для актуальных вопросов, и справляется со сложными вызовами функций.
Пользователи регулируют стиль речи ИИ голосовыми командами. Громкость, темп и эмоции меняются прямо в разговоре. Клонирование голоса позволяет загрузить свой голос и использовать его для ассистента. Команда Qwen отмечает: все эти возможности доступны через real-time API.
Модель работает также в Qwen Chat и Alibaba Cloud Model Studio. В отличие от прошлых релизов вроде Qwen3-Omni и текстовых Qwen3.5, Alibaba пока не выложила веса моделей и не указала лицензию. Сейчас Qwen3.5-Omni доступна только как API-сервис.
Выпуск случился на фоне перестановок в команде и быстрого роудмапа моделей
Alibaba выпускает модели в быстром темпе. Предшественник Qwen3.5-Omni, Qwen3-Omni, появился в апреле 2025 года. Эта модель с 30 миллиардами параметров лидировала на 32 из 36 аудио- и видеобенчмарках и реагировала на чисто аудиовходы за 211 миллисекунду. После этого Alibaba расширила линейку текстовых Qwen 3.5 до четырех моделей, флагман Qwen3.5-397B-A17B использует mixture-of-experts с 397 миллиардами общих параметров и 17 миллиардами активных.
Однако темп совпал с сложным периодом. Главный разработчик ИИ Alibaba, Junyang Lin — ключевой автор всей серии Qwen — недавно неожиданно ушел. За ним последовали другие ключевые члены команды, включая руководителей Qwen-кодеров, постобучения и Qwen 3.5/VL.
Уходы связывают с внутренней реорганизацией, которая должна была поставить во главе исследователя из команды Gemini Google. CEO Alibaba Eddie Wu отреагировал, объявив новую «Задачную группу по базовым моделям» и подчеркнув, что разработка базовых моделей остается «ключевым стратегическим приоритетом для будущего».